This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world has known the term artificialintelligence for decades. Developing AI When most people think about artificialintelligence, they likely imagine a coder hunched over their workstation developing AI models. In some cases, the data ingestion comes from cameras or recording devices connected to the model.
To solve the problem, the company turned to gen AI and decided to use both commercial and opensourcemodels. With security, many commercial providers use their customers data to train their models, says Ringdahl. Thats one of the catches of proprietary commercial models, he says.
The move relaxes Meta’s acceptable use policy restricting what others can do with the largelanguagemodels it develops, and brings Llama ever so slightly closer to the generally accepted definition of open-source AI.
Tanmay Chopra Contributor Share on Twitter Tanmay Chopra works in machinelearning at AI search startup Neeva , where he wrangles languagemodelslarge and small. Last summer could only be described as an “AI summer,” especially with largelanguagemodels making an explosive entrance.
LLM or largelanguagemodels are deep learningmodelstrained on vast amounts of linguistic data so they understand and respond in natural language (human-like texts). These encoders and decoders help the LLMmodel contextualize the input data and, based on that, generate appropriate responses.
For many, ChatGPT and the generative AI hype train signals the arrival of artificialintelligence into the mainstream. “Vector databases are the natural extension of their (LLMs) capabilities,” Zayarni explained to TechCrunch. ” Investors have been taking note, too. .
Media outlets and entertainers have already filed several AI copyright cases in US courts, with plaintiffs accusing AI vendors of using their material to train AI models or copying their material in outputs, notes Jeffrey Gluck, a lawyer at IP-focused law firm Panitch Schwarze. How was the AI trained?
Data scientists and AI engineers have so many variables to consider across the machinelearning (ML) lifecycle to prevent models from degrading over time. Let’s dive into Cloudera’s latest AMPs: PromptBrew The PromptBrew AMP is an AI assistant designed to help AI engineers create better prompts for LLMs.
A largelanguagemodel (LLM) is a type of gen AI that focuses on text and code instead of images or audio, although some have begun to integrate different modalities. But there’s a problem with it — you can never be sure if the information you upload won’t be used to train the next generation of the model.
Explosion , a company that has combined an opensourcemachinelearning library with a set of commercial developer tools, announced a $6 million Series A today on a $120 million valuation. Since then, that opensource project has been downloaded over 40 million times.
Speech recognition remains a challenging problem in AI and machinelearning. In a step toward solving it, OpenAI today open-sourced Whisper, an automatic speech recognition system that the company claims enables “robust” transcription in multiple languages as well as translation from those languages into English.
Bob Ma of Copec Wind Ventures AI’s eye-popping potential has given rise to numerous enterprise generative AI startups focused on applying largelanguagemodel technology to the enterprise context. First, LLM technology is readily accessible via APIs from large AI research companies such as OpenAI.
All industries and modern applications are undergoing rapid transformation powered by advances in accelerated computing, deep learning, and artificialintelligence. The next phase of this transformation requires an intelligent data infrastructure that can bring AI closer to enterprise data.
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 million H100 GPU hours.
Jorge Torres is CEO and co-founder of MindsDB , an opensource AI layer for existing databases. Adam Carrigan is a co-founder and COO of MindsDB , an opensource AI layer for existing databases. Open-source software gave birth to a slew of useful software in recent years. Contributor. Share on Twitter.
But so far, only a handful of such AI systems have been made freely available to the public and opensourced — reflecting the commercial incentives of the companies building them. billion parameters) — using ServiceNow’s in-house graphics card cluster.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. ” Generating DNA sequences.
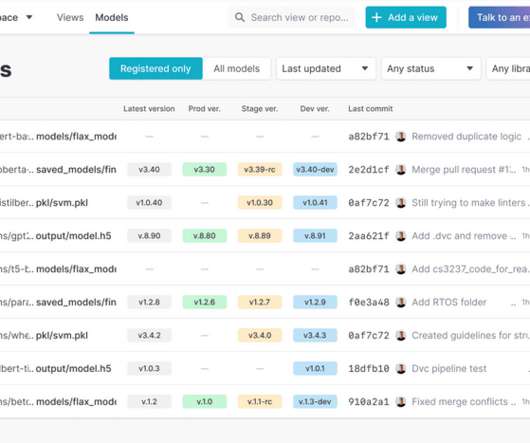
MLOps platform Iterative , which announced a $20 million Series A round almost exactly a year ago, today launched MLEM, an open-source git-based machinelearningmodel management and deployment tool. Using MLEM, developers can store and track their ML models throughout their lifecycle.
OctoML , a Seattle-based startup that offers a machinelearning acceleration platform build on top of the open-source Apache TVM compiler framework project , today announced that it has raised a $28 million Series B funding round led by Addition.
Reasons for using RAG are clear: largelanguagemodels (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost.
The nonpartisan think tank Brookings this week published a piece decrying the bloc’s regulation of opensource AI, arguing it would create legal liability for general-purpose AI systems while simultaneously undermining their development. “In the end, the [E.U.’s] “In the end, the [E.U.’s]
It seems anyone can make an AI model these days. Even if you don’t have the training data or programming chops, you can take your favorite opensourcemodel, tweak it, and release it under a new name. But don’t underestimate the value of getting in there and playing with these models,” he says.
Activeloop , a member of the Y Combinator summer 2018 cohort , is building a database specifically designed for media-focused artificialintelligence applications. He says that there are 55 contributors to the opensource project and 700 community members overall. Activeloop image database. Image Credits: Activeloop.
Our results indicate that, for specialized healthcare tasks like answering clinical questions or summarizing medical research, these smaller models offer both efficiency and high relevance, positioning them as an effective alternative to larger counterparts within a RAG setup. The prompt is fed into the LLM.
Union AI , a Bellevue, Washington–based opensource startup that helps businesses build and orchestrate their AI and data workflows with the help of a cloud-native automation platform, today announced that it has raised a $19.1 At the time, Lyft had to glue together various opensource systems to put these models into production.
With Together, Prakash, Zhang, Re and Liang are seeking to create opensource generative AI models and services that, in their words, “help organizations incorporate AI into their production applications.” The number of opensourcemodels both from community groups and large labs grows by the day , practically.
AI Little LanguageModels is an educational program that teaches young children about probability, artificialintelligence, and related topics. It’s fun and playful and can enable children to build simple models of their own. Unlike many of Mistral’s previous small models, these are not opensource.
Heartex, a startup that bills itself as an “opensource” platform for data labeling, today announced that it landed $25 million in a Series A funding round led by Redpoint Ventures. When asked, Heartex says that it doesn’t collect any customer data and opensources the core of its labeling platform for inspection.
The study, Careless Whisper: Speech-to-Text Hallucination Harms, found that Whisper often inserted phrases during moments of silence in medical conversations, particularly when transcribing patients with aphasia, a condition that affects language and speech patterns. With over 4.2
That quote aptly describes what Dell Technologies and Intel are doing to help our enterprise customers quickly, effectively, and securely deploy generative AI and largelanguagemodels (LLMs).Many That makes it impractical to train an LLM from scratch. Training GPT-3 was heralded as an engineering marvel.
The use of largelanguagemodels (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. top_p=0.95) # Create an LLM. choices[0].text'
Co-founder and CEO Matt Welsh describes it as the first enterprise-focused platform-as-a-service for building experiences with largelanguagemodels (LLMs). “The core of Fixie is its LLM-powered agents that can be built by anyone and run anywhere.” Fixie agents can interact with databases, APIs (e.g.
Largelanguagemodels (LLMs) are hard to beat when it comes to instantly parsing reams of publicly available data to generate responses to general knowledge queries. The key to this approach is developing a solid data foundation to support the GenAI model.
Alignment AI alignment refers to a set of values that models are trained to uphold, such as safety or courtesy. There’s only so much you can do with a prompt if the model has been heavily trained to go against your interests.” This is a significant problem for enterprises today, especially with commercial models. “If
In this post, we explore the new Container Caching feature for SageMaker inference, addressing the challenges of deploying and scaling largelanguagemodels (LLMs). You’ll learn about the key benefits of Container Caching, including faster scaling, improved resource utilization, and potential cost savings.
Sovereign AI refers to a national or regional effort to develop and control artificialintelligence (AI) systems, independent of the large non-EU foreign private tech platforms that currently dominate the field. The Data Act framework creates new possibilities to access data that could be used for AI training and development.
That’s what a number of IT leaders are learning of late, as the AI market and enterprise AI strategies continue to evolve. But purpose-built small languagemodels (SLMs) and other AI technologies also have their place, IT leaders are finding, with benefits such as fewer hallucinations and a lower cost to deploy.
startup that specializes in the rarified world of development tools to optimize machinelearning. More accurately, Seldon is a cloud-agnostic machinelearning (ML) deployment specialist which works in partnership with industry leaders such as Google, Red Hat, IBM and Amazon Web Services. Seldon is a U.K. ”
To help alleviate the complexity and extract insights, the foundation, using different AI models, is building an analytics layer on top of this database, having partnered with DataBricks and DataRobot. Some of the models are traditional machinelearning (ML), and some, LaRovere says, are gen AI, including the new multi-modal advances.
Artificialintelligence promises to help, and maybe even replace, humans to carry out everyday tasks and solve problems that humans have been unable to tackle, yet ironically, building that AI faces a major scaling problem. It has effectively built trainingmodels to automate the training of those models.
On top of that, Gen AI, and the largelanguagemodels (LLMs) that power it, are super-computing workloads that devour electricity.Estimates vary, but Dr. Sajjad Moazeni of the University of Washington calculates that training an LLM with 175 billion+ parameters takes a year’s worth of energy for 1,000 US households.
ArtificialIntelligence (AI) is revolutionizing software development by enhancing productivity, improving code quality, and automating routine tasks. It uses OpenAI’s Codex, a languagemodeltrained on a vast amount of code from public repositories on GitHub.
Inferencing has emerged as among the most exciting aspects of generative AI largelanguagemodels (LLMs). A quick explainer: In AI inferencing , organizations take a LLM that is pretrained to recognize relationships in large datasets and generate new content based on input, such as text or images.
Universities have been pumping out Data Science grades in rapid pace and the OpenSource community made ML technology easy to use and widely available. Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available. Big part of the reason lies in collaboration between teams.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content