This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world has known the term artificialintelligence for decades. Developing AI When most people think about artificialintelligence, they likely imagine a coder hunched over their workstation developing AI models. Today, integrating AI into your workflow isn’t hypothetical, it’s MANDATORY.
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. Predicting protein structures.
and the Live API Google continues to push the boundaries of AI with their latest “thinking model” Gemini 2.5. Thinking refers to an internal reasoning process using the first output tokens, allowing it to solve more complex tasks. offers a scikit-learn-like API for ML. Gemini 2.5 BigFrames 2.0
As the tech world inches a closer to the idea of artificial general intelligence, we’re seeing another interesting theme emerging in the ongoing democratization of AI: a wave of startups building tech to make AI technologies more accessible overall by a wider range of users and organizations.
I really enjoyed reading ArtificialIntelligence – A Guide for Thinking Humans by Melanie Mitchell. The author is a professor of computer science and an artificialintelligence (AI) researcher. I don’t have any experience working with AI and machinelearning (ML). The bottle.
As businesses large and small migrate en masse from monolithic to highly distributed cloud-native applications, APIs are now a critical service component for digital business processes, transactions, and data flows,” Bansal told TechCrunch in an email interview. Businesses need machinelearning here. ”
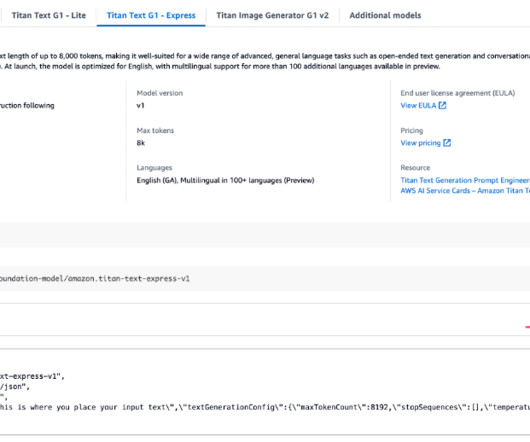
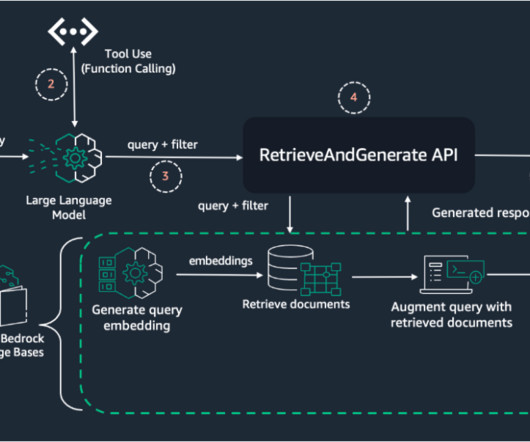
The introduction of Amazon Nova models represent a significant advancement in the field of AI, offering new opportunities for largelanguagemodel (LLM) optimization. In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline.
In this post, we explore the new Container Caching feature for SageMaker inference, addressing the challenges of deploying and scaling largelanguagemodels (LLMs). You’ll learn about the key benefits of Container Caching, including faster scaling, improved resource utilization, and potential cost savings.
The rise of largelanguagemodels (LLMs) and foundation models (FMs) has revolutionized the field of natural language processing (NLP) and artificialintelligence (AI). He is passionate about cloud and machinelearning.
After months of crunching data, plotting distributions, and testing out various machinelearning algorithms you have finally proven to your stakeholders that your model can deliver business value. Serving a model cannot be too hard, right? Many different factors influence the architecture around a machinelearningmodel.
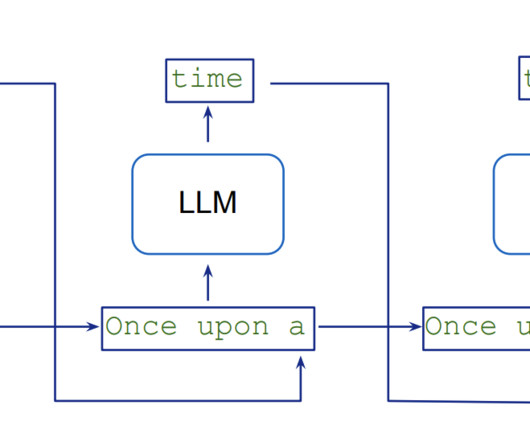
Largelanguagemodels (LLMs) have revolutionized the field of natural language processing with their ability to understand and generate humanlike text. Researchers developed Medusa , a framework to speed up LLM inference by adding extra heads to predict multiple tokens simultaneously.
The effectiveness of RAG heavily depends on the quality of context provided to the largelanguagemodel (LLM), which is typically retrieved from vector stores based on user queries. The relevance of this context directly impacts the model’s ability to generate accurate and contextually appropriate responses.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced largelanguagemodel (LLM) distinguished by its innovative, multi-stage training process. Instead of relying solely on traditional pre-training and fine-tuning, DeepSeek-R1 integrates reinforcement learning to achieve more refined outputs.
In this blog post, we discuss how Prompt Optimization improves the performance of largelanguagemodels (LLMs) for intelligent text processing task in Yuewen Group. Evolution from Traditional NLP to LLM in Intelligent Text Processing Yuewen Group leverages AI for intelligent analysis of extensive web novel texts.
The use of largelanguagemodels (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. top_p=0.95) # Create an LLM. choices[0].text'
National Laboratory has implemented an AI-driven document processing platform that integrates named entity recognition (NER) and largelanguagemodels (LLMs) on Amazon SageMaker AI. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
Out-of-the-box models often lack the specific knowledge required for certain domains or organizational terminologies. To address this, businesses are turning to custom fine-tuned models, also known as domain-specific largelanguagemodels (LLMs). You have the option to quantize the model.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained largelanguagemodels (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available. So then let me re-iterate: why, still, are teams having troubles launching MachineLearningmodels into production? Graph refers to Gartner hype cycle. So what is MLOps comprised of?
The time taken to determine the root cause is referred to as mean time to detect (MTTD). Amazon SageMaker HyperPod resilient training infrastructure SageMaker HyperPod is a compute environment optimized for large-scale frontier model training. SageMaker HyperPod runs health monitoring agents in the background for each instance.
One of the most exciting and rapidly-growing fields in this evolution is ArtificialIntelligence (AI) and MachineLearning (ML). Simply put, AI is the ability of a computer to learn and perform tasks that ordinarily require human intelligence, such as understanding natural language and recognizing objects in pictures.
As policymakers across the globe approach regulating artificialintelligence (AI), there is an emerging and welcomed discussion around the importance of securing AI systems themselves. These models are increasingly being integrated into applications and networks across every sector of the economy.
At the heart of this shift are AI (ArtificialIntelligence), ML (MachineLearning), IoT, and other cloud-based technologies. The intelligence generated via MachineLearning. There are also significant cost savings linked with artificialintelligence in health care.
The following were some initial challenges in automation: Language diversity – The services host both Dutch and English shows. Some local shows feature Flemish dialects, which can be difficult for some largelanguagemodels (LLMs) to understand. The secondary LLM is used to evaluate the summaries on a large scale.
In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing largelanguagemodels (LLMs) in-context sample data with features and labels in the prompt. Here are some key observations: 1.
Reasons for using RAG are clear: largelanguagemodels (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost.
Post-training is a set of processes and techniques for refining and optimizing a machinelearningmodel after its initial training on a dataset. It is intended to improve a models performance and efficiency and sometimes includes fine-tuning a model on a smaller, more specific dataset.
Largelanguagemodels (LLMs) have witnessed an unprecedented surge in popularity, with customers increasingly using publicly available models such as Llama, Stable Diffusion, and Mistral. Solution overview We can use SMP with both Amazon SageMaker Model training jobs and Amazon SageMaker HyperPod.
Shared components refer to the functionality and features shared by all tenants. You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures. Prompt catalog – Crafting effective prompts is important for guiding largelanguagemodels (LLMs) to generate the desired outputs.
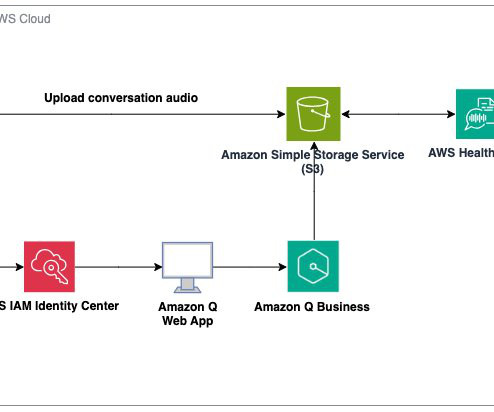
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. Evidence mapping that references the original transcript for each sentence in the AI-generated notes. This can lead to more personalized and effective care.
To learn more details about these service features, refer to Generative AI foundation model training on Amazon SageMaker. This design simplifies the complexity of distributed training while maintaining the flexibility needed for diverse machinelearning (ML) workloads, making it an ideal solution for enterprise AI development.
For example, Whisper correctly transcribed a speaker’s reference to “two other girls and one lady” but added “which were Black,” despite no such racial context in the original conversation. Whisper is not the only AI model that generates such errors.
This application allows users to ask questions in natural language and then generates a SQL query for the users request. Largelanguagemodels (LLMs) are trained to generate accurate SQL queries for natural language instructions. However, off-the-shelf LLMs cant be used without some modification.
In contrast, the fulfillment Region is the Region that actually services the largelanguagemodel (LLM) invocation request. Refer to the following considerations related to AWS Control Tower upgrades from 2.x You pay the same price per token of the individual models in your source Region.
The solution integrates largelanguagemodels (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. Which LLM you want to use in Amazon Bedrock for text generation.
Because JSON is a widely used data exchange standard, this functionality streamlines the process of working with the models outputs, making it more accessible and practical for developers across different industries and use cases. Additionally, Pixtral Large supports the Converse API and tool usage. Curious to explore further?
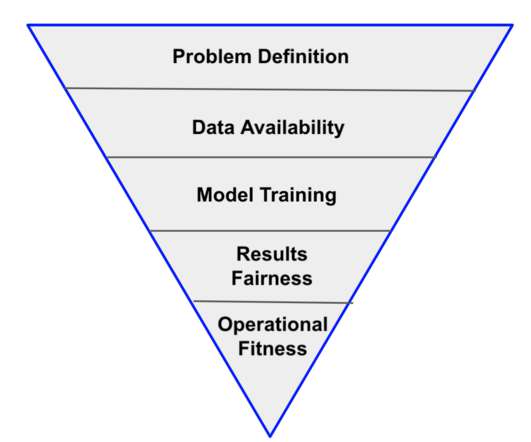
Right quality refers to the fact that the data samples are an accurate reflection of the phenomenon we are trying to model? The right quantity refers to the amount of data that needs to be available. The right quantity refers to the amount of data that needs to be available. This is not always true.
These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned largelanguagemodels (LLMs), or a combination of these techniques. To learn more about FMEval, see Evaluate largelanguagemodels for quality and responsibility of LLMs.
But a particular category of startup stood out: those applying AI and machinelearning to solve problems, especially for business-to-business clients. The platform is powered by largelanguagemodels (think GPT-3) that reference several sources to find the most likely answers, according to co-founder Michael Royzen.
Finally, use the generated images as reference material for 3D artists to create fully realized game environments. For instructions, refer to Clean up Amazon SageMaker notebook instance resources. Shes passionate about machinelearning technologies and environmental sustainability.
“The major challenges we see today in the industry are that machinelearning projects tend to have elongated time-to-value and very low access across an organization. “Given these challenges, organizations today need to choose between two flawed approaches when it comes to developing machinelearning. .
Introduction to Multiclass Text Classification with LLMs Multiclass text classification (MTC) is a natural language processing (NLP) task where text is categorized into multiple predefined categories or classes. Traditional approaches rely on training machinelearningmodels, requiring labeled data and iterative fine-tuning.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machinelearnedmodels each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content