This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations building and deploying AI applications, particularly those using largelanguagemodels (LLMs) with Retrieval Augmented Generation (RAG) systems, face a significant challenge: how to evaluate AI outputs effectively throughout the application lifecycle.
Organizations can use these models securely, and for models that are compatible with the Amazon Bedrock Converse API, you can use the robust toolkit of Amazon Bedrock, including Amazon Bedrock Agents , Amazon Bedrock KnowledgeBases , Amazon Bedrock Guardrails , and Amazon Bedrock Flows. You can find him on LinkedIn.
The introduction of Amazon Nova models represent a significant advancement in the field of AI, offering new opportunities for largelanguagemodel (LLM) optimization. In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. This scalability allows for more frequent and comprehensive reviews.
Generative artificialintelligence (AI) has gained significant momentum with organizations actively exploring its potential applications. As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions.
The use of a multi-agent system, rather than relying on a single largelanguagemodel (LLM) to handle all tasks, enables more focused and in-depth analysis in specialized areas. The primary agent can also consult attached knowledgebases or trigger action groups before or after subagent involvement.
Chatbots also offer valuable data-driven insights into customer behavior while scaling effortlessly as the user base grows; therefore, they present a cost-effective solution for engaging customers. Chatbots use the advanced natural language capabilities of largelanguagemodels (LLMs) to respond to customer questions.
The solution integrates largelanguagemodels (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. Which LLM you want to use in Amazon Bedrock for text generation.
In the realm of generative artificialintelligence (AI) , Retrieval Augmented Generation (RAG) has emerged as a powerful technique, enabling foundation models (FMs) to use external knowledge sources for enhanced text generation. Latest innovations in Amazon Bedrock KnowledgeBase provide a resolution to this issue.
Organizations strive to implement efficient, scalable, cost-effective, and automated customer support solutions without compromising the customer experience. Amazon Bedrock simplifies the process of developing and scaling generative AI applications powered by largelanguagemodels (LLMs) and other foundation models (FMs).
Amazon Bedrock provides a broad range of models from Amazon and third-party providers, including Anthropic, AI21, Meta, Cohere, and Stability AI, and covers a wide range of use cases, including text and image generation, embedding, chat, high-level agents with reasoning and orchestration, and more.
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. Largelanguagemodels (LLMs) are generally proficient in responding to user queries, but they sometimes generate overly broad or inaccurate responses.
The fast growth of artificialintelligence (AI) has created new opportunities for businesses to improve and be more creative. A key development in this area is intelligent agents. This helps them depend less on manual work and be more efficient and scalable.
Organizations need to prioritize their generative AI spending based on business impact and criticality while maintaining cost transparency across customer and user segments. This visibility is essential for setting accurate pricing for generative AI offerings, implementing chargebacks, and establishing usage-based billing models.
Whether youre an experienced AWS developer or just getting started with cloud development, youll discover how to use AI-powered coding assistants to tackle common challenges such as complex service configurations, infrastructure as code (IaC) implementation, and knowledgebase integration.
The map functionality in Step Functions uses arrays to execute multiple tasks concurrently, significantly improving performance and scalability for workflows that involve repetitive operations. Furthermore, our solutions are designed to be scalable, ensuring that they can grow alongside your business.
Introduction to Multiclass Text Classification with LLMs Multiclass text classification (MTC) is a natural language processing (NLP) task where text is categorized into multiple predefined categories or classes. Traditional approaches rely on training machinelearningmodels, requiring labeled data and iterative fine-tuning.
Traditionally, transforming raw data into actionable intelligence has demanded significant engineering effort. It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats.
And so we are thrilled to introduce our latest applied ML prototype (AMP) — a largelanguagemodel (LLM) chatbot customized with website data using Meta’s Llama2 LLM and Pinecone’s vector database.
We have built a custom observability solution that Amazon Bedrock users can quickly implement using just a few key building blocks and existing logs using FMs, Amazon Bedrock KnowledgeBases , Amazon Bedrock Guardrails , and Amazon Bedrock Agents.
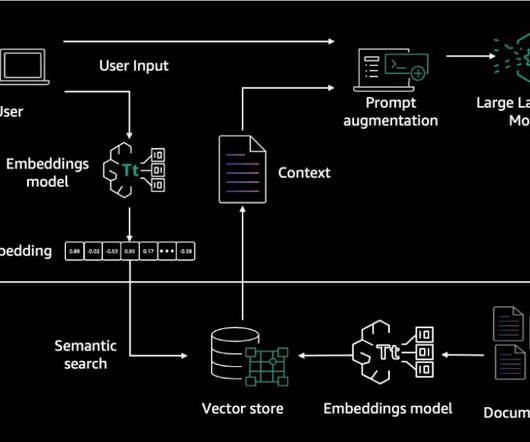
In November 2023, we announced KnowledgeBases for Amazon Bedrock as generally available. Knowledgebases allow Amazon Bedrock users to unlock the full potential of Retrieval Augmented Generation (RAG) by seamlessly integrating their company data into the languagemodel’s generation process.
KnowledgeBases for Amazon Bedrock is a fully managed service that helps you implement the entire Retrieval Augmented Generation (RAG) workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows, pushing the boundaries for what you can do in your RAG workflows.
AI agents , powered by largelanguagemodels (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses. Amazon Bedrock Agents coordinates interactions between foundation models (FMs), knowledgebases, and user conversations.
However, even in a decentralized model, often LOBs must align with central governance controls and obtain approvals from the CCoE team for production deployment, adhering to global enterprise standards for areas such as access policies, model risk management, data privacy, and compliance posture, which can introduce governance complexities.
Finding relevant content usually requires searching through text-based metadata such as timestamps, which need to be manually added to these files. Included with Amazon Bedrock is KnowledgeBases for Amazon Bedrock. With KnowledgeBases for Amazon Bedrock, we first set up a vector database on AWS.
When Amazon Q Business became generally available in April 2024, we quickly saw an opportunity to simplify our architecture, because the service was designed to meet the needs of our use caseto provide a conversational assistant that could tap into our vast (sales) domain-specific knowledgebases.
An end-to-end RAG solution involves several components, including a knowledgebase, a retrieval system, and a generation system. Building and deploying these components can be complex and error-prone, especially when dealing with large-scale data and models. Choose Sync to initiate the data ingestion job.
Depending on the use case and data isolation requirements, tenants can have a pooled knowledgebase or a siloed one and implement item-level isolation or resource level isolation for the data respectively. You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures.
Now I’d like to turn to a slightly more technical, but equally important differentiator for Bedrock—the multiple techniques that you can use to customize models and meet your specific business needs. Customization unlocks the transformative potential of largelanguagemodels.
As Principal grew, its internal support knowledgebase considerably expanded. Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. 2024, Principal Financial Services, Inc.
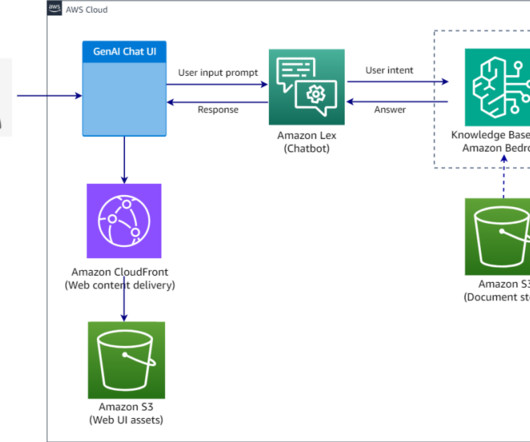
When users pose questions through the natural language interface, the chat agent determines whether to query the structured data in Amazon Athena through the Amazon Bedrock IDE function, search the Amazon Bedrock knowledgebase, or combine both sources for comprehensive insights.
Their DeepSeek-R1 models represent a family of largelanguagemodels (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency.
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. I want to provide an easy and secure outlet that’s genuinely production-ready and scalable. Gen AI is quite different because the models are pre-trained,” Beswick explains.
These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned largelanguagemodels (LLMs), or a combination of these techniques. To learn more about FMEval, see Evaluate largelanguagemodels for quality and responsibility of LLMs.
The following screenshot shows an example of the event filters (1) and time filters (2) as seen on the filter bar (source: Cato knowledgebase ). Retrieval Augmented Generation (RAG) Retrieve relevant context from a knowledgebase, based on the input query. This context is augmented to the original query.
Generative artificialintelligence (AI) is rapidly emerging as a transformative force, poised to disrupt and reshape businesses of all sizes and across industries. However, their knowledge is static and tied to the data used during the pre-training phase. User interface – A conversational chatbot enables interaction with users.
In part 1 of this blog series, we discussed how a largelanguagemodel (LLM) available on Amazon SageMaker JumpStart can be fine-tuned for the task of radiology report impression generation. Evaluating LLMs is an undervalued part of the machinelearning (ML) pipeline.
The Asure team was manually analyzing thousands of call transcripts to uncover themes and trends, a process that lacked scalability. Staying ahead in this competitive landscape demands agile, scalable, and intelligent solutions that can adapt to changing demands.
It also enables operational capabilities including automated testing, conversation analytics, monitoring and observability, and LLM hallucination prevention and detection. “We An optional CloudFormation stack to enable an asynchronous LLM hallucination detection feature. seconds or less.
During the solution design process, Verisk also considered using Amazon Bedrock KnowledgeBases because its purpose built for creating and storing embeddings within Amazon OpenSearch Serverless. In the future, Verisk intends to use the Amazon Titan Embeddings V2 model. Tarik Makota is a Sr.
We use Anthropic’s Claude 3 Sonnet model in Amazon Bedrock and Streamlit for building the application front-end. Solution overview This solution uses the Amazon Bedrock KnowledgeBases chat with document feature to analyze and extract key details from your invoices, without needing a knowledgebase. endswith('.pdf'):
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. I want to provide an easy and secure outlet that’s genuinely production-ready and scalable. Gen AI is quite different because the models are pre-trained,” Beswick explains.
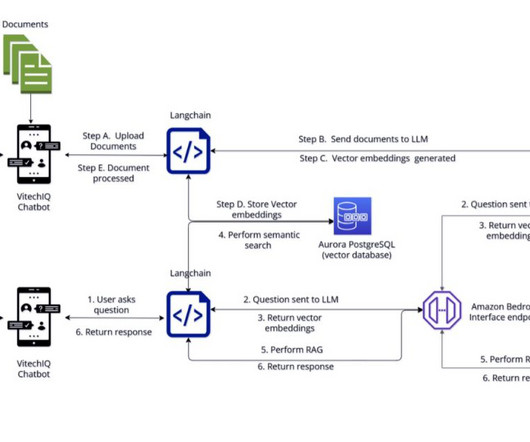
Hosting largelanguagemodels Vitech explored the option of hosting LargeLanguageModels (LLMs) models using Amazon Sagemaker. Vitech needed a fully managed and secure experience to host LLMs and eliminate the undifferentiated heavy lifting associated with hosting 3P models.
The complexity of developing and deploying an end-to-end RAG solution involves several components, including a knowledgebase, retrieval system, and generative languagemodel. Building and deploying these components can be complex and error-prone, especially when dealing with large-scale data and models.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content