This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For MCP implementation, you need a scalable infrastructure to host these servers and an infrastructure to host the largelanguagemodel (LLM), which will perform actions with the tools implemented by the MCP server. You ask the agent to Book a 5-day trip to Europe in January and we like warm weather.
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generativeAI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
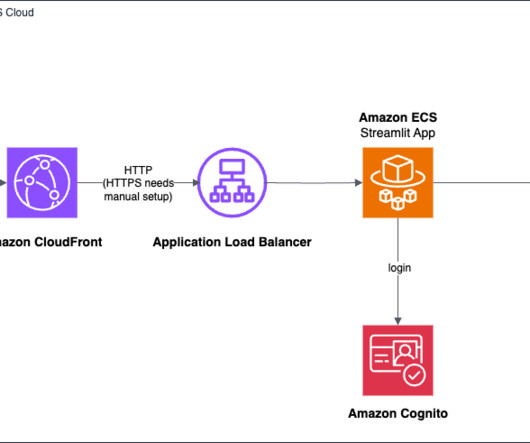
The emergence of generativeAI has ushered in a new era of possibilities, enabling the creation of human-like text, images, code, and more. Solution overview For this solution, you deploy a demo application that provides a clean and intuitive UI for interacting with a generativeAImodel, as illustrated in the following screenshot.
In this post, we explore a generativeAI solution leveraging Amazon Bedrock to streamline the WAFR process. We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices.
While organizations continue to discover the powerful applications of generativeAI , adoption is often slowed down by team silos and bespoke workflows. To move faster, enterprises need robust operating models and a holistic approach that simplifies the generativeAI lifecycle.
This engine uses artificialintelligence (AI) and machinelearning (ML) services and generativeAI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Many commercial generativeAI solutions available are expensive and require user-based licenses.
Recently, we’ve been witnessing the rapid development and evolution of generativeAI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. Multiple programming language support – The GitHub repository provides the observability solution in both Python and Node.js
AWS offers powerful generativeAI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. Which LLM you want to use in Amazon Bedrock for text generation.
GenerativeAI can revolutionize organizations by enabling the creation of innovative applications that offer enhanced customer and employee experiences. In this post, we evaluate different generativeAI operating model architectures that could be adopted.
This is where AWS and generativeAI can revolutionize the way we plan and prepare for our next adventure. With the significant developments in the field of generativeAI , intelligent applications powered by foundation models (FMs) can help users map out an itinerary through an intuitive natural conversation interface.
Companies across all industries are harnessing the power of generativeAI to address various use cases. Cloud providers have recognized the need to offer model inference through an API call, significantly streamlining the implementation of AI within applications.
Building generativeAI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. Building a generativeAI application SageMaker Unified Studio offers tools to discover and build with generativeAI.
At the forefront of using generativeAI in the insurance industry, Verisks generativeAI-powered solutions, like Mozart, remain rooted in ethical and responsible AI use. In the future, Verisk intends to use the Amazon Titan Embeddings V2 model. The new Mozart companion is built using Amazon Bedrock.
Today, we are excited to announce the general availability of Amazon Bedrock Flows (previously known as Prompt Flows). With Bedrock Flows, you can quickly build and execute complex generativeAI workflows without writing code. Key benefits include: Simplified generativeAI workflow development with an intuitive visual interface.
GenerativeAI is rapidly reshaping industries worldwide, empowering businesses to deliver exceptional customer experiences, streamline processes, and push innovation at an unprecedented scale. Specifically, we discuss Data Replys red teaming solution, a comprehensive blueprint to enhance AI safety and responsible AI practices.
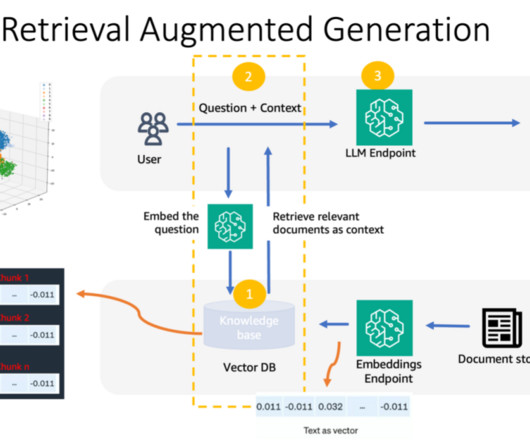
GenerativeAI question-answering applications are pushing the boundaries of enterprise productivity. These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned largelanguagemodels (LLMs), or a combination of these techniques.
In this post, we share how Hearst , one of the nation’s largest global, diversified information, services, and media companies, overcame these challenges by creating a self-service generativeAI conversational assistant for business units seeking guidance from their CCoE. Steven has been AWS Professionally certified for over 8 years.
These services use advanced machinelearning (ML) algorithms and computer vision techniques to perform functions like object detection and tracking, activity recognition, and text and audio recognition. These prompts are crucial in determining the quality, relevance, and coherence of the output generated by the AI.
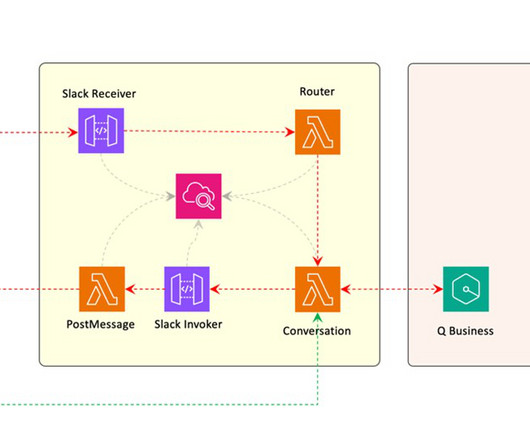
National Laboratory has implemented an AI-driven document processing platform that integrates named entity recognition (NER) and largelanguagemodels (LLMs) on Amazon SageMaker AI. To address these challenges, a U.S. The following diagram illustrates the solution architecture.
In December, we announced the preview availability for Amazon Bedrock Intelligent Prompt Routing , which provides a single serverless endpoint to efficiently route requests between different foundation models within the same model family. Lets dive in!
With the advent of generativeAI solutions, a paradigm shift is underway across industries, driven by organizations embracing foundation models (FMs) to unlock unprecedented opportunities. With advancement in AI technology, the time is right to address such complexities with largelanguagemodels (LLMs).
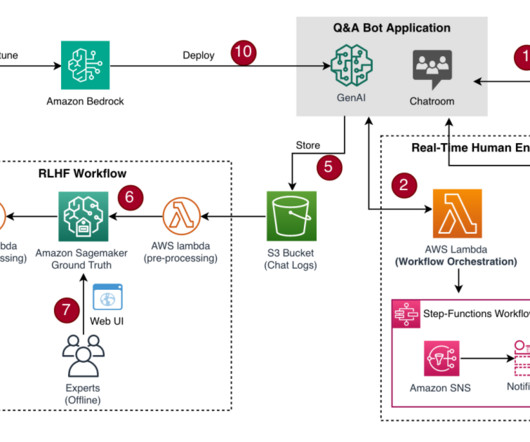
Open foundation models (FMs) have become a cornerstone of generativeAI innovation, enabling organizations to build and customize AI applications while maintaining control over their costs and deployment strategies. The following diagram illustrates the end-to-end flow.
Asure anticipated that generativeAI could aid contact center leaders to understand their teams support performance, identify gaps and pain points in their products, and recognize the most effective strategies for training customer support representatives using call transcripts. Yasmine Rodriguez, CTO of Asure.
GenerativeAI is a type of artificialintelligence (AI) that can be used to create new content, including conversations, stories, images, videos, and music. Like all AI, generativeAI works by using machinelearningmodels—very largemodels that are pretrained on vast amounts of data called foundation models (FMs).
More than 170 tech teams used the latest cloud, machinelearning and artificialintelligence technologies to build 33 solutions. The fundamental objective is to build a manufacturer-agnostic database, leveraging generativeAI’s ability to standardize sensor outputs, synchronize data, and facilitate precise corrections.
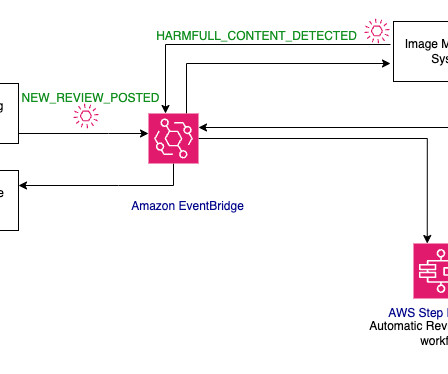
GenerativeAI agents offer a powerful solution by automatically interfacing with company systems, executing tasks, and delivering instant insights, helping organizations scale operations without scaling complexity. The following diagram illustrates the generativeAI agent solution workflow.
Nearly every enterprise is experimenting with AI, but an overwhelming90% of AI projects never scale beyond the proof-of-concept stage,and more than 97% of organizations experience difficulties demonstrating the business value of generativeAI (genAI),according to an Informatica survey. [i]
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generativeartificialintelligence (AI) capabilities. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models.
In Part 3 , we demonstrate how business analysts and citizen data scientists can create machinelearning (ML) models, without code, in Amazon SageMaker Canvas and deploy trained models for integration with Salesforce Einstein Studio to create powerful business applications.
For several years, we have been actively using machinelearning and artificialintelligence (AI) to improve our digital publishing workflow and to deliver a relevant and personalized experience to our readers. Storm serves as the front end for Nova, our serverless content management system (CMS).
In part 1 of this blog series, we discussed how a largelanguagemodel (LLM) available on Amazon SageMaker JumpStart can be fine-tuned for the task of radiology report impression generation. It’s serverless, so you don’t have to manage any infrastructure. It is time-consuming but, at the same time, critical.
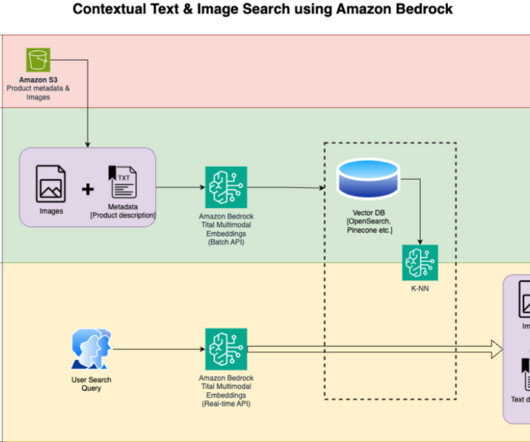
In the context of generativeAI , significant progress has been made in developing multimodal embedding models that can embed various data modalities—such as text, image, video, and audio data—into a shared vector space. Generate embeddings : Use Amazon Titan Multimodal Embeddings to generate embeddings for the stored images.
Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization. This post explains a generativeartificialintelligence (AI) technique to extract insights from business emails and attachments. These samples demonstrate using various LLMs.
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generativeAI. This way, when a user asks a question of the tool, the answer will be generated using only information that the user is permitted to access.
AWS was delighted to present to and connect with over 18,000 in-person and 267,000 virtual attendees at NVIDIA GTC, a global artificialintelligence (AI) conference that took place March 2024 in San Jose, California, returning to a hybrid, in-person experience for the first time since 2019.
Generativeartificialintelligence (AI) can be vital for marketing because it enables the creation of personalized content and optimizes ad targeting with predictive analytics. Use case overview Vidmob aims to revolutionize its analytics landscape with generativeAI.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, such as AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generativeAI applications with security, privacy, and responsible AI.
Recent advances in artificialintelligence have led to the emergence of generativeAI that can produce human-like novel content such as images, text, and audio. These models are pre-trained on massive datasets and, to sometimes fine-tuned with smaller sets of more task specific data.
The financial service (FinServ) industry has unique generativeAI requirements related to domain-specific data, data security, regulatory controls, and industry compliance standards. RAG is a framework for improving the quality of text generation by combining an LLM with an information retrieval (IR) system.
Search engines and recommendation systems powered by generativeAI can improve the product search experience exponentially by understanding natural language queries and returning more accurate results. A multimodal embeddings model is designed to learn joint representations of different modalities like text, images, and audio.
Leveraging Serverless and GenerativeAI for Image Captioning on GCP In today’s age of abundant data, especially visual data, it’s imperative to understand and categorize images efficiently. In our system, it’s the powerhouse behind generating the captions.
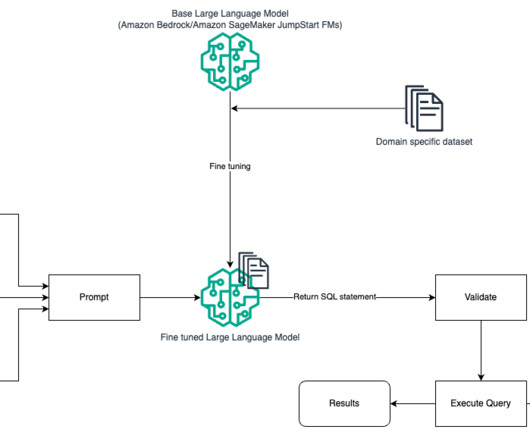
GenerativeAI has opened up a lot of potential in the field of AI. We are seeing numerous uses, including text generation, code generation, summarization, translation, chatbots, and more. These LLMs can be leveraged to understand the natural language question and generate a corresponding SQL query as an output.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon Web Services available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. On the WorkMail console, navigate to the organization gaesas-stk-org-.
Imagine this—all employees relying on generativeartificialintelligence (AI) to get their work done faster, every task becoming less mundane and more innovative, and every application providing a more useful, personal, and engaging experience. That’s why we are investing in a comprehensive generativeAI stack.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content