This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world has known the term artificialintelligence for decades. Developing AI When most people think about artificialintelligence, they likely imagine a coder hunched over their workstation developing AI models. In some cases, the data ingestion comes from cameras or recording devices connected to the model.
But how do companies decide which largelanguagemodel (LLM) is right for them? LLM benchmarks could be the answer. They provide a yardstick that helps user companies better evaluate and classify the major languagemodels. LLM benchmarks are the measuring instrument of the AI world.
For MCP implementation, you need a scalable infrastructure to host these servers and an infrastructure to host the largelanguagemodel (LLM), which will perform actions with the tools implemented by the MCP server. To create an MCP server, we use the official Model Context Protocol Python SDK.
Generative artificialintelligence ( genAI ) and in particular largelanguagemodels ( LLMs ) are changing the way companies develop and deliver software. Instead of manually entering specific parameters, users will increasingly be able to describe their requirements in natural language.
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
In the race to build the smartest LLM, the rallying cry has been more data! After all, if more data leads to better LLMs , shouldnt the same be true for AI business solutions? The urgency of now The rise of artificialintelligence has forced businesses to think much more about how they store, maintain, and use large quantities of data.
“Hippocratic has created the first safety-focused largelanguagemodel (LLM) designed specifically for healthcare,” Shah told TechCrunch in an email interview. But can a languagemodel really replace a healthcare worker? on a hospital safety training compliance quiz.
Largelanguagemodels (LLMs) just keep getting better. In just about two years since OpenAI jolted the news cycle with the introduction of ChatGPT, weve already seen the launch and subsequent upgrades of dozens of competing models. From Llama3.1 to Gemini to Claude3.5 In fact, business spending on AI rose to $13.8
To capitalize on the enormous potential of artificialintelligence (AI) enterprises need systems purpose-built for industry-specific workflows. Enterprise technology leaders discussed these issues and more while sharing real-world examples during EXLs recent virtual event, AI in Action: Driving the Shift to Scalable AI.
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 0.06% of the time.
As insurance companies embrace generative AI (genAI) to address longstanding operational inefficiencies, theyre discovering that general-purpose largelanguagemodels (LLMs) often fall short in solving their unique challenges. Claims adjudication, for example, is an intensive manual process that bogs down insurers.
Small languagemodels (SLMs) are giving CIOs greater opportunities to develop specialized, business-specific AI applications that are less expensive to run than those reliant on general-purpose largelanguagemodels (LLMs). Microsofts Phi, and Googles Gemma SLMs. Googles Gemma 3, based on Gemini 2.0,
While NIST released NIST-AI- 600-1, ArtificialIntelligence Risk Management Framework: Generative ArtificialIntelligence Profile on July 26, 2024, most organizations are just beginning to digest and implement its guidance, with the formation of internal AI Councils as a first step in AI governance.So
Data scientists and AI engineers have so many variables to consider across the machinelearning (ML) lifecycle to prevent models from degrading over time. It guides users through training and deploying an informed chatbot, which can often take a lot of time and effort.
Recent research shows that 67% of enterprises are using generative AI to create new content and data based on learned patterns; 50% are using predictive AI, which employs machinelearning (ML) algorithms to forecast future events; and 45% are using deep learning, a subset of ML that powers both generative and predictive models.
Largelanguagemodels (LLMs) have witnessed an unprecedented surge in popularity, with customers increasingly using publicly available models such as Llama, Stable Diffusion, and Mistral. To maximize performance and optimize training, organizations frequently need to employ advanced distributed training strategies.
In particular, it is essential to map the artificialintelligence systems that are being used to see if they fall into those that are unacceptable or risky under the AI Act and to do training for staff on the ethical and safe use of AI, a requirement that will go into effect as early as February 2025.
Global competition is heating up among largelanguagemodels (LLMs), with the major players vying for dominance in AI reasoning capabilities and cost efficiency. OpenAI is leading the pack with ChatGPT and DeepSeek, both of which pushed the boundaries of artificialintelligence.
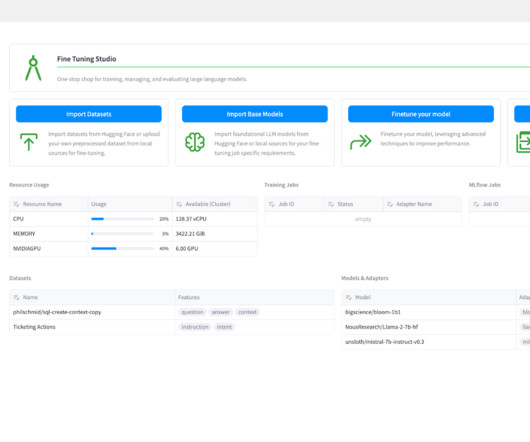
LargeLanguageModels (LLMs) will be at the core of many groundbreaking AI solutions for enterprise organizations. Here are just a few examples of the benefits of using LLMs in the enterprise for both internal and external use cases: Optimize Costs. The Need for Fine Tuning Fine tuning solves these issues.
It could be used to improve the experience for individual users, for example, with smarter analysis of receipts, or help corporate clients by spotting instances of fraud. Take for example the simple job of reading a receipt and accurately classifying the expenses. Its possible to opt-out, but there are caveats.
Bob Ma of Copec Wind Ventures AI’s eye-popping potential has given rise to numerous enterprise generative AI startups focused on applying largelanguagemodel technology to the enterprise context. First, LLM technology is readily accessible via APIs from large AI research companies such as OpenAI.
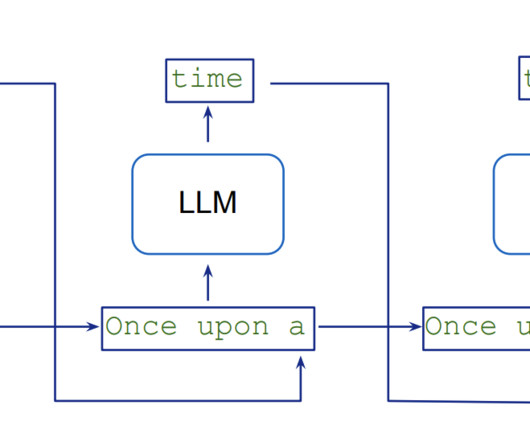
Largelanguagemodels (LLMs) have revolutionized the field of natural language processing with their ability to understand and generate humanlike text. Researchers developed Medusa , a framework to speed up LLM inference by adding extra heads to predict multiple tokens simultaneously.
Much of the AI work prior to agentic focused on largelanguagemodels with a goal to give prompts to get knowledge out of the unstructured data. For example, in the digital identity field, a scientist could get a batch of data and a task to show verification results. So its a question-and-answer process.
Whether it’s a financial services firm looking to build a personalized virtual assistant or an insurance company in need of ML models capable of identifying potential fraud, artificialintelligence (AI) is primed to transform nearly every industry.
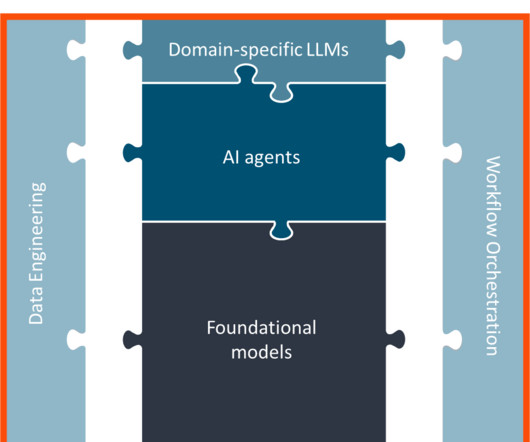
The rise of largelanguagemodels (LLMs) and foundation models (FMs) has revolutionized the field of natural language processing (NLP) and artificialintelligence (AI). We walk through a Python example in this post. For this example, we use a Jupyter notebook (Kernel: Python 3.12.0).
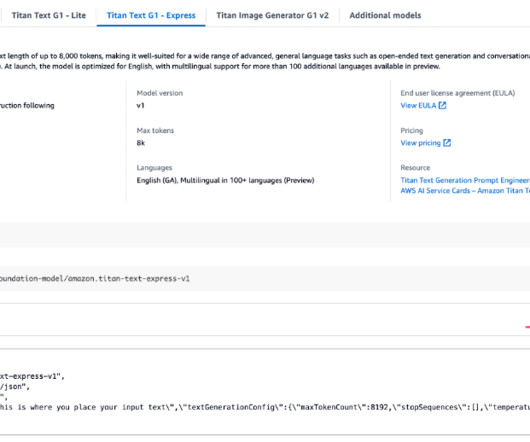
The introduction of Amazon Nova models represent a significant advancement in the field of AI, offering new opportunities for largelanguagemodel (LLM) optimization. In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline.
Understanding the Value Proposition of LLMsLargeLanguageModels (LLMs) have quickly become a powerful tool for businesses, but their true impact depends on how they are implemented. The key is determining where LLMs provide value without sacrificing business-critical quality.
Reasons for using RAG are clear: largelanguagemodels (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost.
Media outlets and entertainers have already filed several AI copyright cases in US courts, with plaintiffs accusing AI vendors of using their material to train AI models or copying their material in outputs, notes Jeffrey Gluck, a lawyer at IP-focused law firm Panitch Schwarze. How was the AI trained?
In this blog post, we discuss how Prompt Optimization improves the performance of largelanguagemodels (LLMs) for intelligent text processing task in Yuewen Group. Evolution from Traditional NLP to LLM in Intelligent Text Processing Yuewen Group leverages AI for intelligent analysis of extensive web novel texts.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trainedlargelanguagemodels (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
The use of largelanguagemodels (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. model. , "temperature":0, "max_tokens": 128}' | jq '.choices[0].text'
For example, because they generally use pre-trainedlargelanguagemodels (LLMs), most organizations aren’t spending exorbitant amounts on infrastructure and the cost of training the models. You use a model and then inject the content at the last minute when you need it,” Gualtieri explains.
One is going through the big areas where we have operational services and look at every process to be optimized using artificialintelligence and largelanguagemodels. And the second is deploying what we call LLM Suite to almost every employee. You need people who are trained to see that.
Out-of-the-box models often lack the specific knowledge required for certain domains or organizational terminologies. To address this, businesses are turning to custom fine-tuned models, also known as domain-specific largelanguagemodels (LLMs). You have the option to quantize the model.
They want to expand their use of artificialintelligence, deliver more value from those AI investments, further boost employee productivity, drive more efficiencies, improve resiliency, expand their transformation efforts, and more. I am excited about the potential of generative AI, particularly in the security space, she says.
On April 22, 2022, I received an out-of-the-blue text from Sam Altman inquiring about the possibility of training GPT-4 on OReilly books. And now, of course, given reports that Meta has trained Llama on LibGen, the Russian database of pirated books, one has to wonder whether OpenAI has done the same. We chose one called DE-COP.
In this post, we explore the new Container Caching feature for SageMaker inference, addressing the challenges of deploying and scaling largelanguagemodels (LLMs). You’ll learn about the key benefits of Container Caching, including faster scaling, improved resource utilization, and potential cost savings.
As policymakers across the globe approach regulating artificialintelligence (AI), there is an emerging and welcomed discussion around the importance of securing AI systems themselves. These models are increasingly being integrated into applications and networks across every sector of the economy.
Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs. Tool specification format requirements For agent function calling distillation, Amazon Bedrock requires that tool specifications be provided as part of your training data.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced largelanguagemodel (LLM) distinguished by its innovative, multi-stage training process. Instead of relying solely on traditional pre-training and fine-tuning, DeepSeek-R1 integrates reinforcement learning to achieve more refined outputs.
To help address the problem, he says, companies are doing a lot of outsourcing, depending on vendors and their client engagement engineers, or sending their own people to training programs. In the Randstad survey, for example, 35% of people have been offered AI training up from just 13% in last years survey.
In the era of generative AI , new largelanguagemodels (LLMs) are continually emerging, each with unique capabilities, architectures, and optimizations. Among these, Amazon Nova foundation models (FMs) deliver frontier intelligence and industry-leading cost-performance, available exclusively on Amazon Bedrock.
For example, AI can detect when a system atypically accesses sensitive data. We're seeing the largemodels and machinelearning being applied at scale," Josh Schmidt, partner in charge of the cybersecurity assessment services team at BPM, a professional services firm, told TechTarget. Source: “Oh, Behave!
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content