This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It’s important to understand the differences between a dataengineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data. I think some of these misconceptions come from the diagrams that are used to describe data scientists and dataengineers.
And we recognized as a company that we needed to start thinking about how we leverage advancements in technology and tremendous amounts of data across our ecosystem, and tie it with machinelearning technology and other things advancing the field of analytics. But we have to bring in the right talent. But whatâ??s
” It currently has a database of some 180,000 engineers covering around 100 or so engineering skills, including React, Node, Python, Agular, Swift, Android, Java, Rails, Golang, PHP, Vue, DevOps, machinelearning, dataengineering and more. It starts with an AI platform to source and vet candidates.
ArtificialIntelligence (AI) systems are becoming ubiquitous: from self-driving cars to risk assessments to largelanguagemodels (LLMs). ArtificialIntelligence (AI) and MachineLearning (ML) systems are becoming ubiquitous: from self-driving cars to risk assessments to largelanguagemodels (LLMs).
Sharing features across teams in an organization reduces the time to production for models. This becomes more important when a company scales and runs more machinelearningmodels in production. Computing features differently across models can create issues. How your model will receive its features?
Fast checkout, personalized recommendations, or instant access to customer care at any time are a few services that can be implemented with the help of artificialintelligence. X-Mart visitors can choose from a wide range of items, including beauty products and fast-moving consumer goods, as well as fashion and apparel.
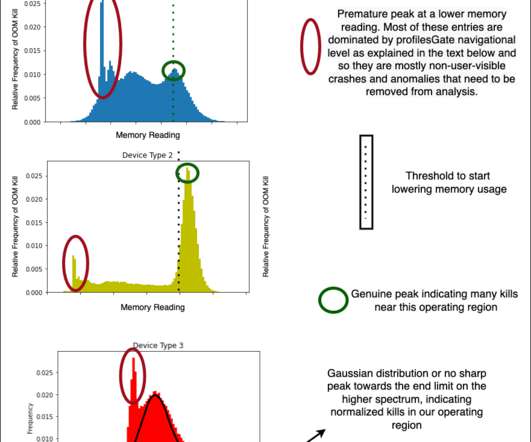
Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the dataengineering that goes along with it. Some nuances while creating this dataset come from the on-field domain knowledge of our engineers.
As critical elements in supplying trusted, curated, and usable data for end-to-end analytic and machinelearning workflows, the role of data pipelines is becoming indispensable. To keep up, data pipelines are being vigorously reshaped with modern tools and techniques.
MachineLearning, alongside a mature Data Science, will help to bring IT and business closer together. By leveraging data for actionable insights, IT will increasingly drive business value. The Role of Data. The reason for this is the central role that data plays in machinelearning.
The three components of the data science iron triangle all have their challenges and strife. Only when organizations understand these challenges will they begin to harmonize and put them to work in a seamless fashion. Below we deconstruct three data science iron triangle dilemmas. How do I wrangle in my data science community?
This post is based on a tutorial given at EuroPython 2023 in Prague: How to MLOps: Experiment tracking & deployment and a Code Breakfast given at Xebia Data together with Jeroen Overschie. Machinelearning operations: what and why MLOps, what the fuzz? MLOps stands for machinelearning (ML) operations.
In the digital communities that we live in, storage is virtually free and our garrulous species is generating and storing data like never before. And, with exponentially increasing computing power and newer chip architectures, MachineLearning (ML) has emerged as a powerful technique for building models over Big Data to predict outcomes.
Prior the introduction of CDP Public Cloud, many organizations that wanted to leverage CDH, HDP or any other on-prem Hadoop runtime in the public cloud had to deploy the platform in a lift-and-shift fashion, commonly known as “Hadoop-on-IaaS” or simply the IaaS model. MachineLearning Prototypes. Not available.
Hybrid clouds must bond together the two clouds through fundamental technology, which will enable the transfer of data and applications. REAN Cloud is a global cloud systems integrator, managed services provider and solutions developer of cloud-native applications across big data, machinelearning and emerging internet of things (IoT) spaces.
But what do the gas and oil corporation, the computer software giant, the luxury fashion house, the top outdoor brand, and the multinational pharmaceutical enterprise have in common? The answer is simple: They use the same technology to make the most of data. How dataengineering works in 14 minutes.
Providing a comprehensive set of diverse analytical frameworks for different use cases across the data lifecycle (data streaming, dataengineering, data warehousing, operational database and machinelearning) while at the same time seamlessly integrating data content via the Shared Data Experience (SDX), a layer that separates compute and storage.
Berg , Romain Cledat , Kayla Seeley , Shashank Srikanth , Chaoying Wang , Darin Yu Netflix uses data science and machinelearning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding.
In today’s rapidly evolving business landscape, establishing robust GenAI and machinelearning capabilities is of the utmost importance, especially for enterprises managing substantial data volumes. She asks the IT team to connect to relevant data sources and help her with required data extraction.
Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machinelearning—your relational database might not be enough. Building an indexing pipeline at scale with Kafka Connect.
1pm-2pm NFX 207 Benchmarking stateful services in the cloud Vinay Chella , Data Platform Engineering Manager Abstract : AWS cloud services make it possible to achieve millions of operations per second in a scalable fashion across multiple regions. We explore all the systems necessary to make and stream content from Netflix.
The Cloudera Data Platform comprises a number of ‘data experiences’ each delivering a distinct analytical capability using one or more purposely-built Apache open source projects such as Apache Spark for DataEngineering and Apache HBase for Operational Database workloads.
You need to have consistent security and governance that allows you to not only control who has access to data, but also have full insights into lineage, metadata and cataloging throughout your environment. I would reiterate that you’ve got to be really careful here, because this is such a huge part of your data and analytics strategy.
It is recommended that a pragmatic approach is taken here and that access control changes are handled in a simple and transparent fashion with clear expectations set around timescales. DataEngineering. Dataengineering involves getting the right data, to the right place, at the right time and in the right format.
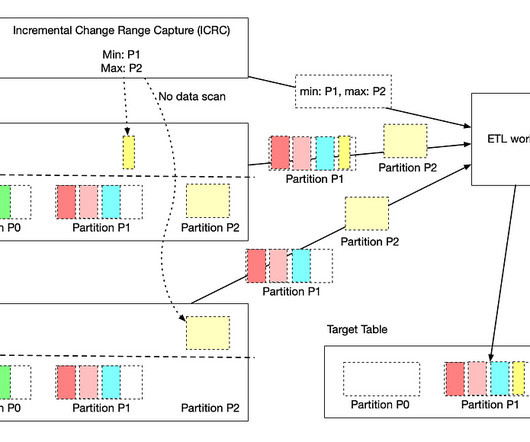
These challenges are currently addressed in suboptimal and less cost efficient ways by individual local teams to fulfill the needs, such as Lookback: This is a generic and simple approach that dataengineers use to solve the data accuracy problem. Users configure the workflow to read the data in a window (e.g.
1pm-2pm NFX 207 Benchmarking stateful services in the cloud Vinay Chella , Data Platform Engineering Manager Abstract : AWS cloud services make it possible to achieve millions of operations per second in a scalable fashion across multiple regions. We explore all the systems necessary to make and stream content from Netflix.
1pm-2pm NFX 207 Benchmarking stateful services in the cloud Vinay Chella , Data Platform Engineering Manager Abstract : AWS cloud services make it possible to achieve millions of operations per second in a scalable fashion across multiple regions. We explore all the systems necessary to make and stream content from Netflix.
Traditional statistical methods use mainly internal, historical data to predict trends within relatively stable markets. Meanwhile, machinelearning (ML) techniques are capable of processing a wide range of both historical and current data from multiple external and internal sources. Extract data. Consolidate data.
The current ArtificialIntelligence (AI) fascination is unfortunately completely biased on Deep Neural Networks (DNN) and MachineLearning (ML) for everything. Companies will start demanding that their investments in Predictive Analytics, MachineLearning and AI show a real ROI. Denis Gagne Trisotech [link].
A quick look at bigram usage (word pairs) doesn’t really distinguish between “data science,” “dataengineering,” “data analysis,” and other terms; the most common word pair with “data” is “data governance,” followed by “data science.” AI, ML, and Data. That’s not what our data shows.
Content about software development was the most widely used (31% of all usage in 2022), which includes software architecture and programming languages. Software development is followed by IT operations (18%), which includes cloud, and by data (17%), which includes machinelearning and artificialintelligence.
It’s often difficult for businesses without a mature data or machinelearning practice to define and agree on metrics. For example, an AI product that helps a clothing manufacturer understand which materials to buy will become stale as fashions change. Data Quality and Standardization. Agreeing on metrics.
Sometimes they’re only apparent if you look carefully at the data; sometimes it’s just a matter of keeping your ear to the ground. Trendy, fashionable things are often a flash in the pan, forgotten or regretted a year or two later (like Pet Rocks or Chia Pets ). We aren’t advocating for Python, Java, or any other language.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content