This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Largelanguagemodels (LLMs) just keep getting better. In just about two years since OpenAI jolted the news cycle with the introduction of ChatGPT, weve already seen the launch and subsequent upgrades of dozens of competing models. From Llama3.1 to Gemini to Claude3.5 In fact, business spending on AI rose to $13.8
Recent research shows that 67% of enterprises are using generative AI to create new content and data based on learned patterns; 50% are using predictive AI, which employs machinelearning (ML) algorithms to forecast future events; and 45% are using deep learning, a subset of ML that powers both generative and predictive models.
It’s important to understand the differences between a dataengineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data. I think some of these misconceptions come from the diagrams that are used to describe data scientists and dataengineers.
Data is a key component when it comes to making accurate and timely recommendations and decisions in real time, particularly when organizations try to implement real-time artificialintelligence. Real-time AI involves processing data for making decisions within a given time frame. It isn’t easy.
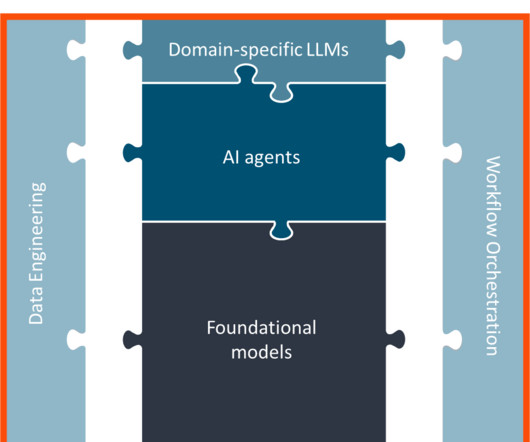
It was not alive because the business knowledge required to turn data into value was confined to individuals minds, Excel sheets or lost in analog signals. We are now deciphering rules from patterns in data, embedding business knowledge into ML models, and soon, AI agents will leverage this data to make decisions on behalf of companies.
Strata Data London will introduce technologies and techniques; showcase use cases; and highlight the importance of ethics, privacy, and security. The growing role of data and machinelearning cuts across domains and industries. Data Science and MachineLearning sessions will cover tools, techniques, and case studies.
John Snow Labs’ Medical LanguageModels library is an excellent choice for leveraging the power of largelanguagemodels (LLM) and natural language processing (NLP) in Azure Fabric due to its seamless integration, scalability, and state-of-the-art accuracy on medical tasks.
Right now, we are thinking about, how do we leverage artificialintelligence more broadly? For example, I was trying to understand underwriting in our Canadian operations. In that example, it was better to just go and understand what is happening locally. Many times it means going and seeing for yourself.
There Are Top Seven Tips for Scaling Your ArtificialIntelligence Strategy. In just the last few years, a large number of enterprises have started to work on incorporating an artificialintelligence strategy into their business. Include Responsibility and Accountability. Start Small and Experiment.
Confidence from business leaders is often focused on the AI models or algorithms, Erolin adds, not the messy groundwork like data quality, integration, or even legacy systems. For example, one of BairesDevs clients was surprised when it spent 30% of an AI project timeline integrating legacy systems, Erolin says.
Gen AI-related job listings were particularly common in roles such as data scientists and dataengineers, and in software development. Training and development Many companies are growing their own AI talent pools by having employees learn on their own, as they build new projects, or from their peers. Thomas, based in St.
For AI, there’s no universal standard for when data is ‘clean enough.’ Google suggests pizza recipes with glue because that’s how food photographers make images of melted mozzarella look enticing, and that should probably be sanitized out of a generic LLM. That’s a classic example of too much good is wasted.”
Universities have been pumping out Data Science grades in rapid pace and the Open Source community made ML technology easy to use and widely available. Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available. Big part of the reason lies in collaboration between teams.
In this short talk, I describe some interesting trends in how data is valued, collected, and shared. Economic value of data. It’s no secret that companies place a lot of value on data and the data pipelines that produce key features. But if data is precious, how do we go about estimating its value?
On a different project, we’d just used a LargeLanguageModel (LLM) - in this case OpenAI’s GPT - to provide users with pre-filled text boxes, with content based on choices they’d previously made. For example, let’s consider Mark. It’s this collaboration between the user and the LLM that drives good results.
Registered investment advisors, for example, have to jump over a few hurdles when deploying new technologies. For example, a faculty member might want to teach a new section of a course. The most common pattern Im seeing is custom-building capabilities and leveraging other systems for data, she says.
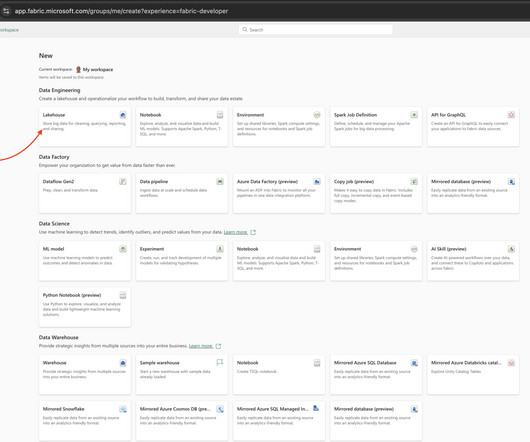
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
But to achieve Henkel’s digital vision, Nilles would need to attract data scientists, dataengineers, and AI experts to an industry they might not otherwise have their eye on. The key account manager or the salesperson is looking at the trade promotion data and it’s giving really great hints.
Machinelearning can provide companies with a competitive advantage by using the data they’re collecting — for example, purchasing patterns — to generate predictions that power revenue-generating products (e.g. e-commerce recommendations). ” Tecton’s monitoring dashboard.
As head of transformation, artificialintelligence, and delivery at Guardian Life, John Napoli is ramping up his company’s AI initiatives. Moreover, many need deeper AI-related skills, too, such as for building machinelearningmodels to serve niche business requirements. Here’s how IT leaders are coping.
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera MachineLearning (CML) projects. RAPIDS on the Cloudera Data Platform comes pre-configured with all the necessary libraries and dependencies to bring the power of RAPIDS to your projects. Project Setup.
Job titles like dataengineer, machinelearningengineer, and AI product manager have supplanted traditional software developers near the top of the heap as companies rush to adopt AI and cybersecurity professionals remain in high demand. An example of the new reality comes from Salesforce.
Faculty , a VC-backed artificialintelligence startup, has won a tender to work with the NHS to make better predictions about its future requirements for patients, based on data drawn from how it handled the COVID-19 pandemic. Palantir doesn’t really do AI, they do dataengineering in a big way.
This application allows users to ask questions in natural language and then generates a SQL query for the users request. Largelanguagemodels (LLMs) are trained to generate accurate SQL queries for natural language instructions. However, off-the-shelf LLMs cant be used without some modification.
You know the one, the mathematician / statistician / computer scientist / dataengineer / industry expert. Some companies are starting to segregate the responsibilities of the unicorn data scientist into multiple roles (dataengineer, ML engineer, ML architect, visualization developer, etc.),
Building a scalable, reliable and performant machinelearning (ML) infrastructure is not easy. It takes much more effort than just building an analytic model with Python and your favorite machinelearning framework. Impedance mismatch between data scientists, dataengineers and production engineers.
In a world fueled by disruptive technologies, no wonder businesses heavily rely on machinelearning. For example, Netflix takes advantage of ML algorithms to personalize and recommend movies for clients, saving the tech giant billions. The role of a machinelearningengineer in the data science team.
An example of this are tasks once viewed as too complicated for the layperson, such as sending an attachment or cropping a photo, have become effortless as digital-productivity tools kept improving and getting easier to use. Those who use the technology are mostly dataengineers, software engineers and business analysts.
As the data community begins to deploy more machinelearning (ML) models, I wanted to review some important considerations. We recently conducted a survey which garnered more than 11,000 respondents—our main goal was to ascertain how enterprises were using machinelearning. Model lifecycle management.
A great example of this is the semiconductor industry. Educating and training our team With generative AI, for example, its adoption has surged from 50% to 72% in the past year, according to research by McKinsey. For example, when we evaluate third-party vendors, we now ask: Does this vendor comply with AI-related data protections?
In thinking about features, it can be helpful to visualize a table, where the data used by AI systems is organized into rows of examples (data from which the system learns to make predictions) and columns of attributes (data describing those examples).
Sharing features across teams in an organization reduces the time to production for models. This becomes more important when a company scales and runs more machinelearningmodels in production. Computing features differently across models can create issues. How your model will receive its features?
Generative AI models (for example, Amazon Titan) hosted on Amazon Bedrock were used for query disambiguation and semantic matching for answer lookups and responses. Model monitoring of key NLP metrics was incorporated and controls were implemented to prevent unsafe, unethical, or off-topic responses. 3778998-082024
Increasingly, conversations about big data, machinelearning and artificialintelligence are going hand-in-hand with conversations about privacy and data protection. “But now we are running into the bottleneck of the data. But humans are not meant to be mined.”
More companies in every industry are adopting artificialintelligence to transform business processes. But the success of their AI initiatives depends on more than just data and technology — it’s also about having the right people on board. Data scientists are the core of any AI team. Dataengineer.
Being at the top of data science capabilities, machinelearning and artificialintelligence are buzzing technologies many organizations are eager to adopt. If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering.
Organizations don’t want to fall behind the competition, but they also want to avoid embarrassments like going to court, only to discover the legal precedent cited is made up by a largelanguagemodel (LLM) prone to generating a plausible rather than factual answer.
We are excited by the endless possibilities of machinelearning (ML). We recognise that experimentation is an important component of any enterprise machinelearning practice. Organizations need to usher their ML models out of the lab (i.e., COPML accounts for the fact that true production machinelearning (i.e.,
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machinelearningmodels, requiring significant compute resources.
Python is used extensively among DataEngineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machinelearningmodels. Apache HBase is an effective data storage system for many workflows but accessing this data specifically through Python can be a struggle.
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificialintelligence (AI) capabilities. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models.
After the data is transcribed, MaestroQA uses technology they have developed in combination with AWS services such as Amazon Comprehend to run various types of analysis on the customer interaction data. For example, Can I speak to your manager? To start developing this product, MaestroQA first rolled out a product called AskAI.
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machinelearningmodels, requiring significant compute resources.
“There were no purpose-built machinelearningdata tools in the market, so [we] started Galileo to build the machinelearningdata tooling stack, beginning with a [specialization in] unstructured data,” Chatterji told TechCrunch via email. ” To date, Galileo has raised $5.1
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content