This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For MCP implementation, you need a scalable infrastructure to host these servers and an infrastructure to host the largelanguagemodel (LLM), which will perform actions with the tools implemented by the MCP server. You ask the agent to Book a 5-day trip to Europe in January and we like warm weather.
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
With serverless components, there is no need to manage infrastructure, and the inbuilt tracing, logging, monitoring and debugging make it easy to run these workloads in production and maintain service levels. Financial services unique challenges However, it is important to understand that serverless architecture is not a silver bullet.
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machinelearning. Access to Amazon Bedrock foundation models is not granted by default.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
With rapid progress in the fields of machinelearning (ML) and artificialintelligence (AI), it is important to deploy the AI/ML model efficiently in production environments. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. You can use AWS services such as Application Load Balancer to implement this approach.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. With the significant developments in the field of generative AI , intelligent applications powered by foundation models (FMs) can help users map out an itinerary through an intuitive natural conversation interface.
National Laboratory has implemented an AI-driven document processing platform that integrates named entity recognition (NER) and largelanguagemodels (LLMs) on Amazon SageMaker AI. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions. It will be marked for deletion and will be deleted when all executions are stopped.
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
In December, we announced the preview availability for Amazon Bedrock Intelligent Prompt Routing , which provides a single serverless endpoint to efficiently route requests between different foundation models within the same model family. We reduced overhead of added components by over 20% to approximately 85 ms (P90).
Seamless integration of latest foundation models (FMs), Prompts, Agents, Knowledge Bases, Guardrails, and other AWS services. Reduced time and effort in testing and deploying AI workflows with SDK APIs and serverless infrastructure. To learn more, see the AWS user guide for Guardrails integration and Traceability.
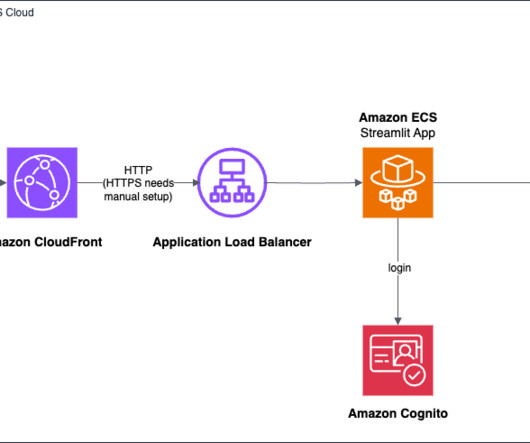
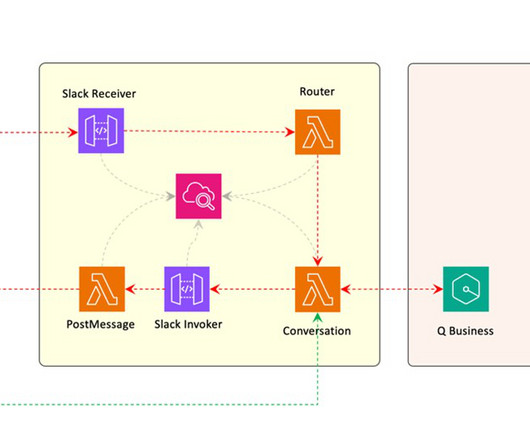
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
With advancement in AI technology, the time is right to address such complexities with largelanguagemodels (LLMs). Amazon Bedrock has helped democratize access to LLMs, which have been challenging to host and manage. The following diagram illustrates the architecture using AWS services.
Organizations are increasingly turning to cloud providers, like Amazon Web Services (AWS), to address these challenges and power their digital transformation initiatives. However, the vastness of AWS environments and the ease of spinning up new resources and services can lead to cloud sprawl and ongoing security risks.
This engine uses artificialintelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. This post provides guidance on how you can create a video insights and summarization engine using AWS AI/ML services.
Their DeepSeek-R1 models represent a family of largelanguagemodels (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. For more information, see Create a service role for model import.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. Post-authentication, users access the UI Layer, a gateway to the Red Teaming Playground built on AWS Amplify and React.
Amazon Web Services (AWS) provides an expansive suite of tools to help developers build and manage serverless applications with ease. By abstracting the complexities of infrastructure, AWS enables teams to focus on innovation. Why Combine AI, ML, and Serverless Computing?
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services. However, some components may incur additional usage-based costs.
We discuss the unique challenges MaestroQA overcame and how they use AWS to build new features, drive customer insights, and improve operational inefficiencies. Its serverless architecture allowed the team to rapidly prototype and refine their application without the burden of managing complex hardware infrastructure.
AWS was delighted to present to and connect with over 18,000 in-person and 267,000 virtual attendees at NVIDIA GTC, a global artificialintelligence (AI) conference that took place March 2024 in San Jose, California, returning to a hybrid, in-person experience for the first time since 2019.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned largelanguagemodels (LLMs), or a combination of these techniques. To learn more about FMEval, see Evaluate largelanguagemodels for quality and responsibility of LLMs.
Imagine this—all employees relying on generative artificialintelligence (AI) to get their work done faster, every task becoming less mundane and more innovative, and every application providing a more useful, personal, and engaging experience. That’s another reason why hundreds of thousands of customers are now using our AI services.
The computer use agent demo powered by Amazon Bedrock Agents provides the following benefits: Secure execution environment Execution of computer use tools in a sandbox environment with limited access to the AWS ecosystem and the web. Prerequisites AWS Command Line Interface (CLI), follow instructions here. Require Python 3.11
That’s right, folks; I replaced the Xebia leadership with artificialintelligence! The magic happens through a combination of Serverless, user input, a CloudFront distribution, a Lambda function, and the OpenAI API. provider: name: aws runtime: python3.9 Please try again later.';
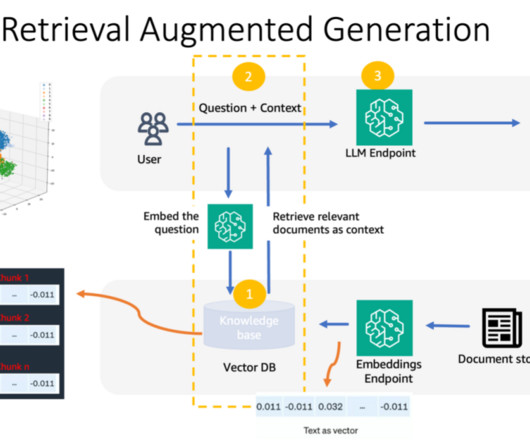
In addition, customers are looking for choices to select the most performant and cost-effective machinelearning (ML) model and the ability to perform necessary customization (fine-tuning) to fit their business use cases. The LLM generated text, and the IR system retrieves relevant information from a knowledge base.
AI agents , powered by largelanguagemodels (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses. Generative AI has transformed customer support, offering businesses the ability to respond faster, more accurately, and with greater personalization.
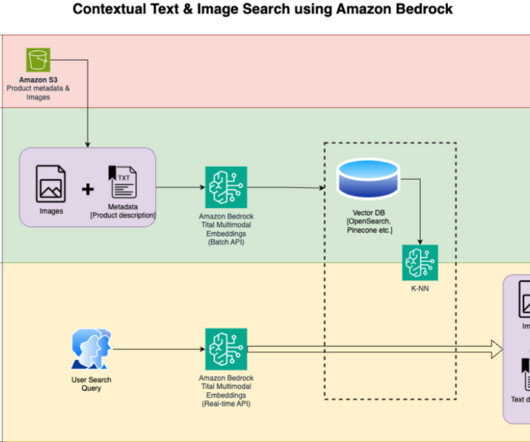
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model , available in Amazon Bedrock , with Amazon OpenSearch Serverless. Amazon SageMaker Studio – It is an integrated development environment (IDE) for machinelearning (ML).
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificialintelligence (AI) capabilities. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models.
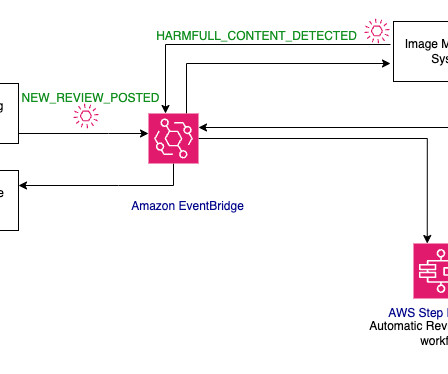
These services use advanced machinelearning (ML) algorithms and computer vision techniques to perform functions like object detection and tracking, activity recognition, and text and audio recognition. An EventBridge rule then triggers the AWS Step Functions workflow to begin processing the video recording into a transcript.
Generative AI is a type of artificialintelligence (AI) that can be used to create new content, including conversations, stories, images, videos, and music. Like all AI, generative AI works by using machinelearningmodels—very largemodels that are pretrained on vast amounts of data called foundation models (FMs).
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. This is done to optimize performance and minimize cost of LLM invocation.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
It uses Amazon Bedrock , AWS Health , AWS Step Functions , and other AWS services. Some examples of AWS-sourced operational events include: AWS Health events — Notifications related to AWS service availability, operational issues, or scheduled maintenance that might affect your AWS resources.
Recent advances in artificialintelligence have led to the emergence of generative AI that can produce human-like novel content such as images, text, and audio. These models are pre-trained on massive datasets and, to sometimes fine-tuned with smaller sets of more task specific data.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon Web Services available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Deploy the AWS CDK project to provision the required resources in your AWS account.
From deriving insights to powering generative artificialintelligence (AI) -driven applications, the ability to efficiently process and analyze large datasets is a vital capability. That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help.
In this post, we demonstrate how we used Amazon Bedrock , a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Presently, his main area of focus is state-of-the-art natural language processing.
An AWS Batch job reads these documents, chunks them into smaller slices, then creates embeddings of the text chunks using the Amazon Titan Text Embeddings model through Amazon Bedrock and stores them in an Amazon OpenSearch Service vector database. In the future, Verisk intends to use the Amazon Titan Embeddings V2 model.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content