This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machinelearning. Access to Amazon Bedrock foundation models is not granted by default.
With rapid progress in the fields of machinelearning (ML) and artificialintelligence (AI), it is important to deploy the AI/ML model efficiently in production environments. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
Generative and agentic artificialintelligence (AI) are paving the way for this evolution. AI practitioners and industry leaders discussed these trends, shared best practices, and provided real-world use cases during EXLs recent virtual event, AI in Action: Driving the Shift to Scalable AI. The EXLerate.AI
The use of largelanguagemodels (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. xlarge instances are only available in these AWS Regions.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This scalability allows for more frequent and comprehensive reviews.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. This a revolutionary new capability within Amazon Bedrock that serves as a centralized hub for discovering, testing, and implementing foundation models (FMs).
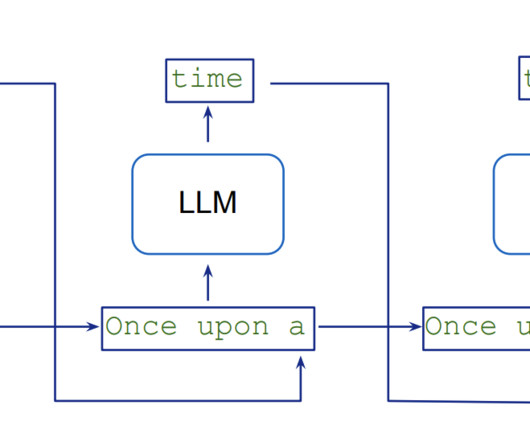
LargeLanguageModels (LLMs) have revolutionized the field of natural language processing (NLP), improving tasks such as language translation, text summarization, and sentiment analysis. Monitoring the performance and behavior of LLMs is a critical task for ensuring their safety and effectiveness.
The introduction of Amazon Nova models represent a significant advancement in the field of AI, offering new opportunities for largelanguagemodel (LLM) optimization. In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. Although batch inference offers numerous benefits, it’s limited to 10 batch inference jobs submitted per model per Region. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
For MCP implementation, you need a scalable infrastructure to host these servers and an infrastructure to host the largelanguagemodel (LLM), which will perform actions with the tools implemented by the MCP server. We will deep dive into the MCP architecture later in this post.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. It supports a wide range of popular open source LLMs, making it a popular choice for diverse AI applications.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. It consists of one or more components depending on the number of FM providers and number and types of custom models used.
Largelanguagemodels (LLMs) have revolutionized the field of natural language processing with their ability to understand and generate humanlike text. Researchers developed Medusa , a framework to speed up LLM inference by adding extra heads to predict multiple tokens simultaneously.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. With the significant developments in the field of generative AI , intelligent applications powered by foundation models (FMs) can help users map out an itinerary through an intuitive natural conversation interface.
In this blog post, we discuss how Prompt Optimization improves the performance of largelanguagemodels (LLMs) for intelligent text processing task in Yuewen Group. Evolution from Traditional NLP to LLM in Intelligent Text Processing Yuewen Group leverages AI for intelligent analysis of extensive web novel texts.
In this post, we illustrate how EBSCOlearning partnered with AWS Generative AI Innovation Center (GenAIIC) to use the power of generative AI in revolutionizing their learning assessment process. The evaluation process includes three phases: LLM-based guideline evaluation, rule-based checks, and a final evaluation.
As DPG Media grows, they need a more scalable way of capturing metadata that enhances the consumer experience on online video services and aids in understanding key content characteristics. The following were some initial challenges in automation: Language diversity – The services host both Dutch and English shows.
ArtificialIntelligence Average salary: $130,277 Expertise premium: $23,525 (15%) AI tops the list as the skill that can earn you the highest pay bump, earning tech professionals nearly an 18% premium over other tech skills. Read on to find out how such expertise can make you stand out in any industry.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
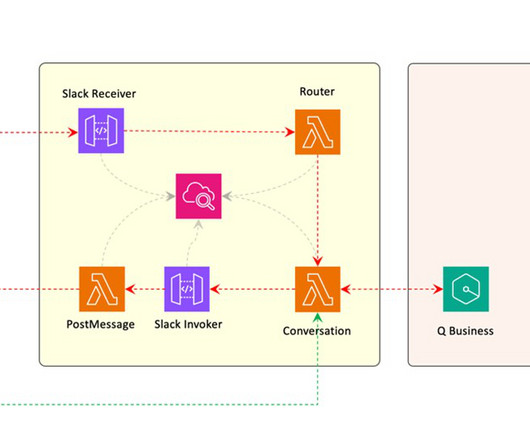
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
With the rise of largelanguagemodels (LLMs) like Meta Llama 3.1, there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.
Out-of-the-box models often lack the specific knowledge required for certain domains or organizational terminologies. To address this, businesses are turning to custom fine-tuned models, also known as domain-specific largelanguagemodels (LLMs). Why LoRAX for LoRA deployment on AWS?
National Laboratory has implemented an AI-driven document processing platform that integrates named entity recognition (NER) and largelanguagemodels (LLMs) on Amazon SageMaker AI. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
This visibility is essential for setting accurate pricing for generative AI offerings, implementing chargebacks, and establishing usage-based billing models. Without a scalable approach to controlling costs, organizations risk unbudgeted usage and cost overruns. anthropic.claude-3-sonnet-20240229-v1:0", "inferenceProfileId": "us-1.anthropic.claude-3-sonnet-20240229-v1:0",
Some examples include extracting players and positions in an NFL game summary, products mentioned in an AWS keynote transcript, or key names from an article on a favorite tech company. This process must be repeated for every new document and entity type, making it impractical for processing large volumes of documents at scale.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced largelanguagemodel (LLM) distinguished by its innovative, multi-stage training process. Instead of relying solely on traditional pre-training and fine-tuning, DeepSeek-R1 integrates reinforcement learning to achieve more refined outputs.
Amazon Web Services (AWS) is committed to supporting the development of cutting-edge generative artificialintelligence (AI) technologies by companies and organizations across the globe. Let’s dive in and explore how these organizations are transforming what’s possible with generative AI on AWS.
This engine uses artificialintelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. This post provides guidance on how you can create a video insights and summarization engine using AWS AI/ML services.
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machinelearning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
This post explores key insights and lessons learned from AWS customers in Europe, Middle East, and Africa (EMEA) who have successfully navigated this transition, providing a roadmap for others looking to follow suit. For more information, you can watch the AWS Summit Milan 2024 presentation.
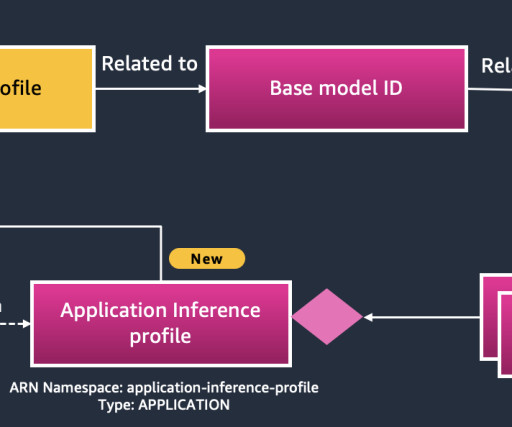
Amazon Bedrock cross-Region inference capability that provides organizations with flexibility to access foundation models (FMs) across AWS Regions while maintaining optimal performance and availability. We provide practical examples for both SCP modifications and AWS Control Tower implementations.
Organizations are increasingly turning to cloud providers, like Amazon Web Services (AWS), to address these challenges and power their digital transformation initiatives. However, the vastness of AWS environments and the ease of spinning up new resources and services can lead to cloud sprawl and ongoing security risks.
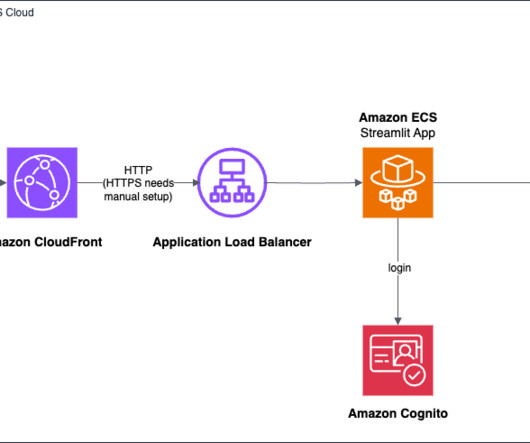
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. Post-authentication, users access the UI Layer, a gateway to the Red Teaming Playground built on AWS Amplify and React.
Amazon Web Services (AWS) provides an expansive suite of tools to help developers build and manage serverless applications with ease. By abstracting the complexities of infrastructure, AWS enables teams to focus on innovation. Why Combine AI, ML, and Serverless Computing?
During his one hour forty minute-keynote, Thomas Kurian, CEO of Google Cloud showcased updates around most of the companys offerings, including new largelanguagemodels (LLMs) , a new AI accelerator chip, new open source frameworks around agents, and updates to its data analytics, databases, and productivity tools and services among others.
Advancements in multimodal artificialintelligence (AI), where agents can understand and generate not just text but also images, audio, and video, will further broaden their applications. Conversely, asynchronous event-driven systems offer greater flexibility and scalability through their distributed nature.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
Their DeepSeek-R1 models represent a family of largelanguagemodels (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. For more information, see Create a service role for model import.
SageMaker HyperPod recipes help data scientists and developers of all skill sets to get started training and fine-tuning popular publicly available generative AI models in minutes with state-of-the-art training performance. You can run these recipes using SageMaker HyperPod or as SageMaker training jobs.
Add to this the escalating costs of maintaining legacy systems, which often act as bottlenecks for scalability. The latter option had emerged as a compelling solution, offering the promise of enhanced agility, reduced operational costs, and seamless scalability. Scalability. Scalability. Cost forecasting. The results?
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content