This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For MCP implementation, you need a scalable infrastructure to host these servers and an infrastructure to host the largelanguagemodel (LLM), which will perform actions with the tools implemented by the MCP server. You ask the agent to Book a 5-day trip to Europe in January and we like warm weather.
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
LargeLanguageModels (LLMs) have revolutionized the field of natural language processing (NLP), improving tasks such as language translation, text summarization, and sentiment analysis. Monitoring the performance and behavior of LLMs is a critical task for ensuring their safety and effectiveness.
It also uses a number of other AWS services such as Amazon API Gateway , AWSLambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. It consists of one or more components depending on the number of FM providers and number and types of custom models used.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
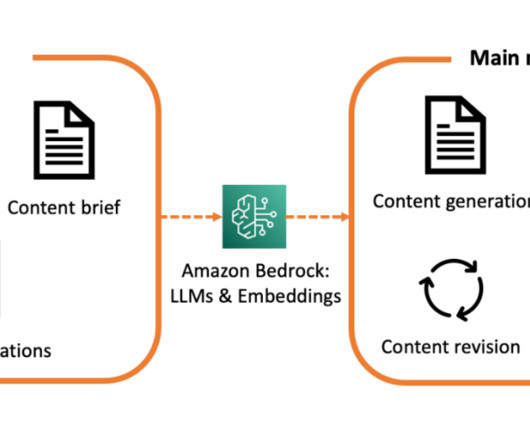
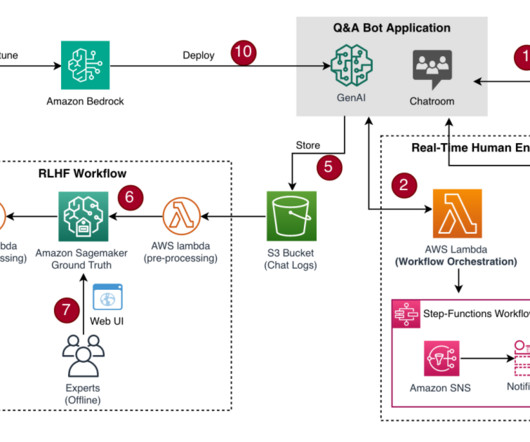
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
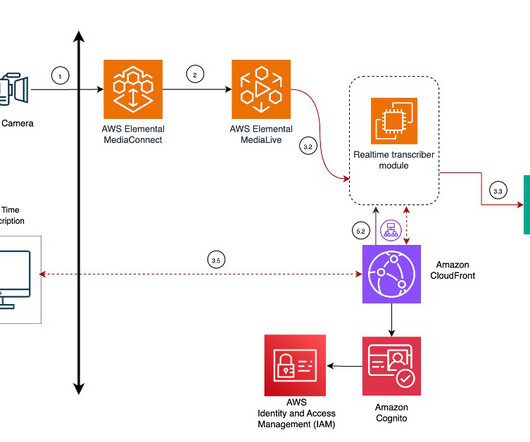
However, as the reach of live streams expands globally, language barriers and accessibility challenges have emerged, limiting the ability of viewers to fully comprehend and participate in these immersive experiences. The extension delivers a web application implemented using the AWS SDK for JavaScript and the AWS Amplify JavaScript library.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. With the significant developments in the field of generative AI , intelligent applications powered by foundation models (FMs) can help users map out an itinerary through an intuitive natural conversation interface.
David Copland, from QARC, and Scott Harding, a person living with aphasia, used AWS services to develop WordFinder, a mobile, cloud-based solution that helps individuals with aphasia increase their independence through the use of AWS generative AI technology. The following diagram illustrates the solution architecture on AWS.
This is where the integration of cutting-edge technologies, such as audio-to-text translation and largelanguagemodels (LLMs), holds the potential to revolutionize the way patients receive, process, and act on vital medical information. These insights can include: Potential adverse event detection and reporting.
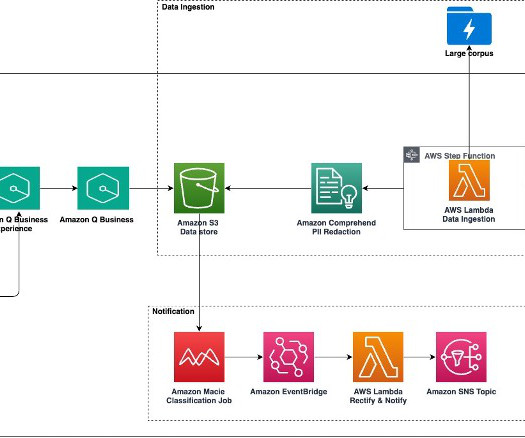
This engine uses artificialintelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. This post provides guidance on how you can create a video insights and summarization engine using AWS AI/ML services.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. Although batch inference offers numerous benefits, it’s limited to 10 batch inference jobs submitted per model per Region. We walk you through our solution, detailing the core logic of the Lambda functions.
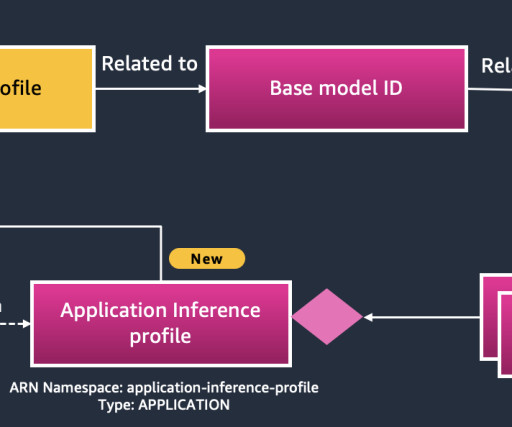
To address these challenges, Amazon Bedrock has launched a capability that organization can use to tag on-demand models and monitor associated costs. Organizations can now label all Amazon Bedrock models with AWS cost allocation tags , aligning usage to specific organizational taxonomies such as cost centers, business units, and applications.
National Laboratory has implemented an AI-driven document processing platform that integrates named entity recognition (NER) and largelanguagemodels (LLMs) on Amazon SageMaker AI. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
Some examples include extracting players and positions in an NFL game summary, products mentioned in an AWS keynote transcript, or key names from an article on a favorite tech company. This process must be repeated for every new document and entity type, making it impractical for processing large volumes of documents at scale.
AI agents , powered by largelanguagemodels (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses. The Lambda function processes the OpenSearch Service results and formats them for the Amazon Bedrock agent.
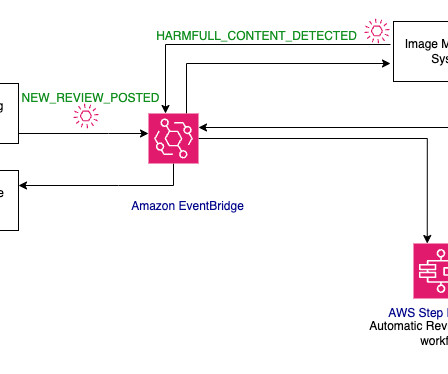
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions. It will be marked for deletion and will be deleted when all executions are stopped.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
With advancement in AI technology, the time is right to address such complexities with largelanguagemodels (LLMs). Amazon Bedrock has helped democratize access to LLMs, which have been challenging to host and manage. The following diagram illustrates the architecture using AWS services.
Advancements in multimodal artificialintelligence (AI), where agents can understand and generate not just text but also images, audio, and video, will further broaden their applications. If the model determines that one of the tools can help generate a response, it returns a request to use the tool.
This is where intelligent document processing (IDP), coupled with the power of generative AI , emerges as a game-changing solution. Enhancing the capabilities of IDP is the integration of generative AI, which harnesses largelanguagemodels (LLMs) and generative techniques to understand and generate human-like text.
AI agents extend largelanguagemodels (LLMs) by interacting with external systems, executing complex workflows, and maintaining contextual awareness across operations. In the first flow, a Lambda-based action is taken, and in the second, the agent uses an MCP server.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
In this blog post, we examine the relative costs of different language runtimes on AWSLambda. Many languages can be used with AWSLambda today, so we focus on four interesting ones. Rust just came to AWSLambda in November 2023 , so probably a lot of folks are wondering whether to try it out.
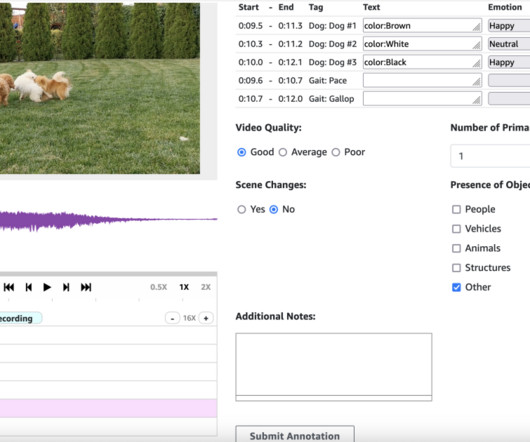
This granular input helps modelslearn how to produce speech that sounds natural, with appropriate pacing and emotional consistency. We guide you through deploying the necessary infrastructure using AWS CloudFormation , creating an internal labeling workforce, and setting up your first labeling job.
The use of a multi-agent system, rather than relying on a single largelanguagemodel (LLM) to handle all tasks, enables more focused and in-depth analysis in specialized areas. The initial step involves creating an AWSLambda function that will integrate with the Amazon Bedrock agents CreatePortfolio action group.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. Deploy the AWS CDK project to provision the required resources in your AWS account.
Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. This tutorial assumes you have the necessary AWS Identity and Access Management (IAM) permissions. or later on your local machine. Install Python 3.7
Welcome to our tutorial on deploying a machinelearning (ML) model on Amazon Web Services (AWS) Lambda using Docker. In this tutorial, we will walk you through the process of packaging an ML model as a Docker container and deploying it on AWSLambda, a serverless computing service.
Generative AI and transformer-based largelanguagemodels (LLMs) have been in the top headlines recently. These models demonstrate impressive performance in question answering, text summarization, code, and text generation. Amazon Lambda : to run the backend code, which encompasses the generative logic.
Recent advances in artificialintelligence have led to the emergence of generative AI that can produce human-like novel content such as images, text, and audio. These models are pre-trained on massive datasets and, to sometimes fine-tuned with smaller sets of more task specific data.
These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned largelanguagemodels (LLMs), or a combination of these techniques. To learn more about FMEval, see Evaluate largelanguagemodels for quality and responsibility of LLMs.
It integrates with existing applications and includes key Amazon Bedrock features like foundation models (FMs), prompts, knowledge bases, agents, flows, evaluation, and guardrails. Organization administrators can control member access to Amazon Bedrock models and features, maintaining secure identity management and granular access control.
That’s right, folks; I replaced the Xebia leadership with artificialintelligence! The magic happens through a combination of Serverless, user input, a CloudFront distribution, a Lambda function, and the OpenAI API. You’ve heard of the age-old saying: "If you can’t beat them, join them," right?
CBRE is unlocking the potential of artificialintelligence (AI) to realize value across the entire commercial real estate lifecycle—from guiding investment decisions to managing buildings. CBRE wanted to enable clients to quickly query existing data using natural language prompts, all in a user-friendly environment.
Generative AI is a type of artificialintelligence (AI) that can be used to create new content, including conversations, stories, images, videos, and music. Like all AI, generative AI works by using machinelearningmodels—very largemodels that are pretrained on vast amounts of data called foundation models (FMs).
They often find themselves struggling with language barriers when it comes to setting up reminders for events like business gatherings and customer meetings. It understands the incoming messages, translates them to the preferred language, and automatically sets up calendar reminders.
This solution demonstrates how to create an AI-powered virtual meteorologist that can answer complex weather-related queries in natural language. We use various AWS services to deploy a complete solution that you can use to interact with an API providing real-time weather information. In this solution, we use Amazon Bedrock Agents.
To address these challenges, Infosys partnered with Amazon Web Services (AWS) to develop the Infosys Event AI to unlock the insights generated during events. The services used in the solution are granted least-privilege permissions through AWS Identity and Access Management (IAM) policies for security purposes.
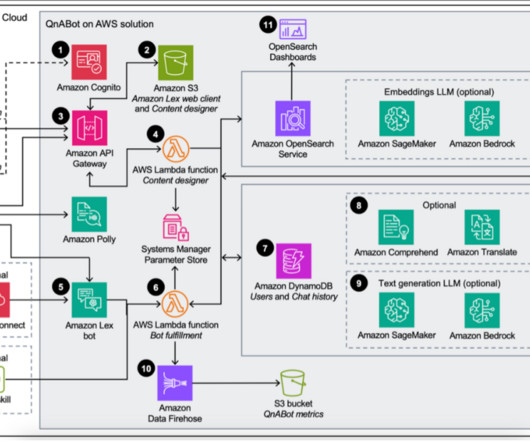
QnABot on AWS (an AWS Solution) now provides access to Amazon Bedrock foundational models (FMs) and Knowledge Bases for Amazon Bedrock , a fully managed end-to-end Retrieval Augmented Generation (RAG) workflow. Deploying the QnABot solution builds the following environment in the AWS Cloud.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificialintelligence (AI) capabilities. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models.
Fortunately, with the advent of generative AI and largelanguagemodels (LLMs) , it’s now possible to create automated systems that can handle natural language efficiently, and with an accelerated on-ramping timeline. This can be done with a Lambda layer or by using a specific AMI with the required libraries.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content