This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
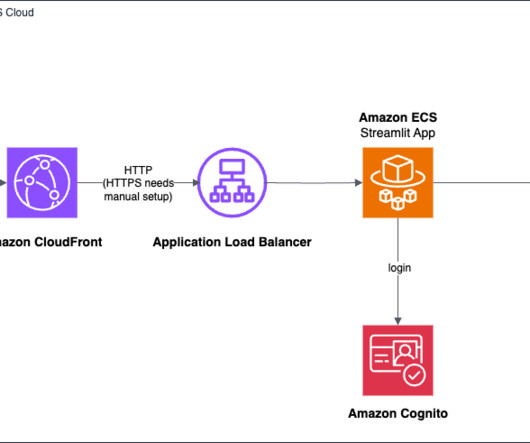
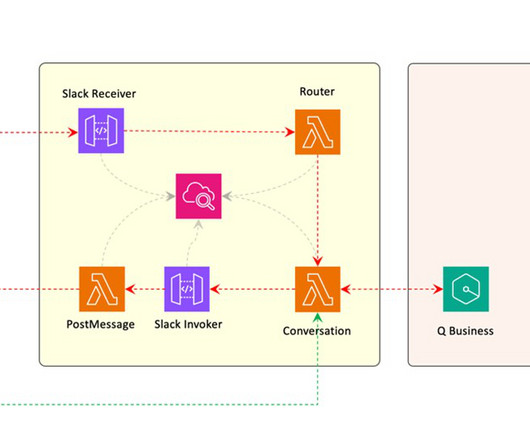
For MCP implementation, you need a scalable infrastructure to host these servers and an infrastructure to host the largelanguagemodel (LLM), which will perform actions with the tools implemented by the MCP server. You ask the agent to Book a 5-day trip to Europe in January and we like warm weather.
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machinelearning. Access to Amazon Bedrock foundation models is not granted by default.
Tecton.ai , the startup founded by three former Uber engineers who wanted to bring the machinelearning feature store idea to the masses, announced a $35 million Series B today, just seven months after announcing their $20 million Series A. “We help organizations put machinelearning into production.
Learn how to streamline productivity and efficiency across your organization with machinelearning and artificialintelligence! How you can leverage innovations in technology and machinelearning to improve your customer experience and bottom line.
The use of largelanguagemodels (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. xlarge instances are only available in these AWS Regions.
Generative and agentic artificialintelligence (AI) are paving the way for this evolution. Built on top of EXLerate.AI, EXLs AI orchestration platform, and Amazon Web Services (AWS), Code Harbor eliminates redundant code and optimizes performance, reducing manual assessment, conversion and testing effort by 60% to 80%.
As a company founded by data scientists, Streamlit may be in a unique position to develop tooling to help companies build machinelearning applications. Data scientists can download the open-source project and build a machinelearning application, but it requires a certain level of technical aptitude to make all the parts work.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
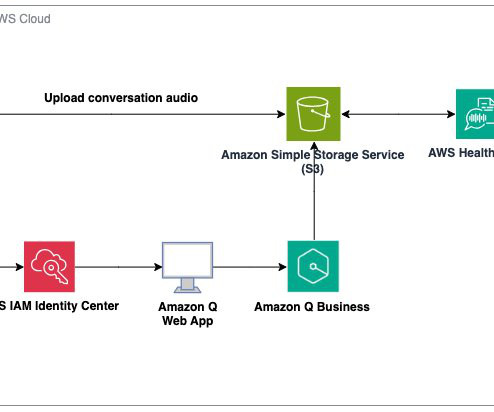
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. AWS HealthScribe combines speech recognition and generative AI trained specifically for healthcare documentation to accelerate clinical documentation and enhance the consultation experience.
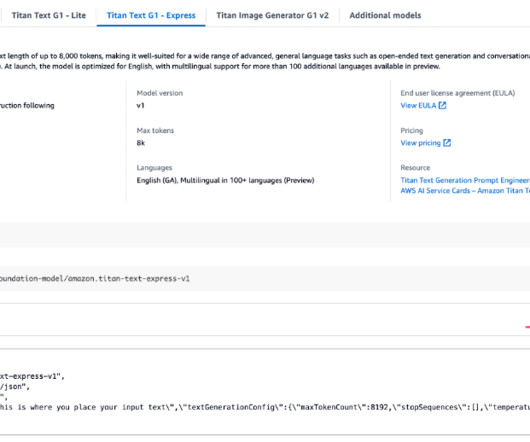
The introduction of Amazon Nova models represent a significant advancement in the field of AI, offering new opportunities for largelanguagemodel (LLM) optimization. In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline.
Amazon Web Services (AWS) has extended the reach of its generative artificialintelligence (AI) platform for application development to include a set of plug-in extensions, that make it possible to launch natural language queries against data residing in platforms from Datadog and Wiz.
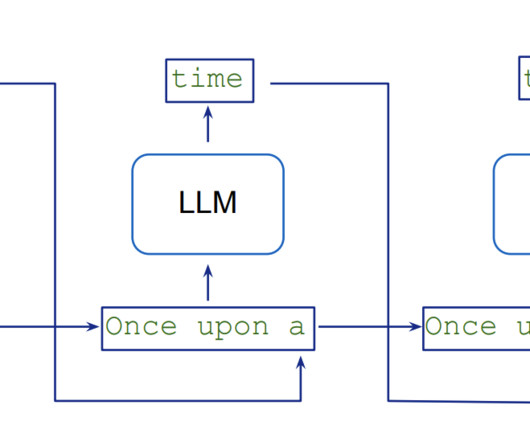
Largelanguagemodels (LLMs) have revolutionized the field of natural language processing with their ability to understand and generate humanlike text. Researchers developed Medusa , a framework to speed up LLM inference by adding extra heads to predict multiple tokens simultaneously.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. It consists of one or more components depending on the number of FM providers and number and types of custom models used.
With the core architectural backbone of the airlines gen AI roadmap in place, including United Data Hub and an AI and ML platform dubbed Mars, Birnbaum has released a handful of models into production use for employees and customers alike.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. This a revolutionary new capability within Amazon Bedrock that serves as a centralized hub for discovering, testing, and implementing foundation models (FMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
Like many innovative companies, Camelot looked to artificialintelligence for a solution. Camelot has the flexibility to run on any selected GenAI LLM across cloud providers like AWS, Microsoft Azure, and GCP (Google Cloud Platform), ensuring that the company meets compliance regulations for data security.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. It supports a wide range of popular open source LLMs, making it a popular choice for diverse AI applications.
The rise of largelanguagemodels (LLMs) and foundation models (FMs) has revolutionized the field of natural language processing (NLP) and artificialintelligence (AI). Development environment – Set up an integrated development environment (IDE) with your preferred coding language and tools.
Training largelanguagemodels (LLMs) models has become a significant expense for businesses. For many use cases, companies are looking to use LLM foundation models (FM) with their domain-specific data. To learn more about Trainium chips and the Neuron SDK, see Welcome to AWS Neuron.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. With the significant developments in the field of generative AI , intelligent applications powered by foundation models (FMs) can help users map out an itinerary through an intuitive natural conversation interface.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
This unification of analytics and AI services is perhaps best exemplified by a new offering inside Amazon SageMaker, Unified Studio , a preview of which AWS CEO Matt Garman unveiled at the companys annual re:Invent conference this week.
In this blog post, we discuss how Prompt Optimization improves the performance of largelanguagemodels (LLMs) for intelligent text processing task in Yuewen Group. Evolution from Traditional NLP to LLM in Intelligent Text Processing Yuewen Group leverages AI for intelligent analysis of extensive web novel texts.
With rapid progress in the fields of machinelearning (ML) and artificialintelligence (AI), it is important to deploy the AI/ML model efficiently in production environments. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
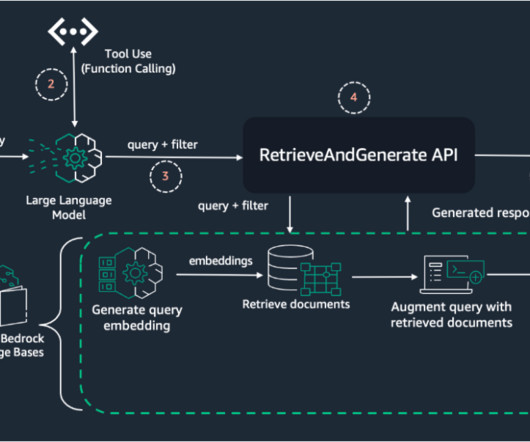
The effectiveness of RAG heavily depends on the quality of context provided to the largelanguagemodel (LLM), which is typically retrieved from vector stores based on user queries. The relevance of this context directly impacts the model’s ability to generate accurate and contextually appropriate responses.
The following were some initial challenges in automation: Language diversity – The services host both Dutch and English shows. Some local shows feature Flemish dialects, which can be difficult for some largelanguagemodels (LLMs) to understand. The secondary LLM is used to evaluate the summaries on a large scale.
However, as the reach of live streams expands globally, language barriers and accessibility challenges have emerged, limiting the ability of viewers to fully comprehend and participate in these immersive experiences. The extension delivers a web application implemented using the AWS SDK for JavaScript and the AWS Amplify JavaScript library.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
National Laboratory has implemented an AI-driven document processing platform that integrates named entity recognition (NER) and largelanguagemodels (LLMs) on Amazon SageMaker AI. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
Over the past several months, we drove several improvements in intelligent prompt routing based on customer feedback and extensive internal testing. In GA, you can configure your own router by selecting any two models from the same model family and then configuring the response quality difference of your router.
Out-of-the-box models often lack the specific knowledge required for certain domains or organizational terminologies. To address this, businesses are turning to custom fine-tuned models, also known as domain-specific largelanguagemodels (LLMs). Why LoRAX for LoRA deployment on AWS?
This is where the integration of cutting-edge technologies, such as audio-to-text translation and largelanguagemodels (LLMs), holds the potential to revolutionize the way patients receive, process, and act on vital medical information. These insights can include: Potential adverse event detection and reporting.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions. It will be marked for deletion and will be deleted when all executions are stopped.
In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing largelanguagemodels (LLMs) in-context sample data with features and labels in the prompt.
In this post, we illustrate how EBSCOlearning partnered with AWS Generative AI Innovation Center (GenAIIC) to use the power of generative AI in revolutionizing their learning assessment process. The evaluation process includes three phases: LLM-based guideline evaluation, rule-based checks, and a final evaluation.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced largelanguagemodel (LLM) distinguished by its innovative, multi-stage training process. Instead of relying solely on traditional pre-training and fine-tuning, DeepSeek-R1 integrates reinforcement learning to achieve more refined outputs.
With the rise of largelanguagemodels (LLMs) like Meta Llama 3.1, there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. Prerequisites Before you begin, make sure you have the following utilities installed on your local machine or development environment.
We are all talking about the business gains from using largelanguagemodels, but there are lot of known issues with these models and finding ways to constrain the answers that a model could give is one way to apply some control to these powerful technologies. All rights reserved.
Prerequisites For a successful implementation of Amazon Bedrock Model Distillation, youll need to meet several requirements. We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. 70B and Llama 3.1
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. Predicting protein structures.
The failed instance also needs to be isolated and terminated manually, either through the AWS Management Console , AWS Command Line Interface (AWS CLI), or tools like kubectl or eksctl. About the Authors Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference.
At its re:Invent conference today, Amazon’s AWS cloud arm announced the launch of SageMaker HyperPod, a new purpose-built service for training and fine-tuning largelanguagemodels (LLMs). SageMaker HyperPod is now generally available.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content