This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The New York Times is suing OpenAI and its close collaborator (and investor), Microsoft, for allegedly violating copyright law by training generative AI models on Times’ content. All rights reserved.
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
Strong Compute , a Sydney, Australia-based startup that helps developers remove the bottlenecks in their machine learning training pipelines, today announced that it has raised a $7.8 ” Strong Compute wants to speed up your ML model training. . ” Strong Compute wants to speed up your ML model training.
But she’s identified a problem that most people managers will all too clearly understand: training and tools to be a great manager are at a shortage. Dulski explained that there are some tools for managers, like surveys from Gallup and Glint, and there are training options, like executive coaches.
The recent terms & conditions controversy sequence goes like this: A clause added to Zoom’s legalese back in March 2023 grabbed attention on Monday after a post on Hacker News claimed it allowed the company to use customer data to train AI models “with no opt out” Cue outrage on social media.
Frustrated, she decided to try training engineers to meet her team’s hiring standards by mentoring at a local coding bootcamp. For one, they wanted to offer personalized training to help people not just learn to code, but to become “exceptional” software engineers. 13 investors say lifelong learning is taking edtech mainstream.
Unfortunately, the blog post only focuses on train-serve skew. Feature stores solve more than just train-serve skew. In a naive setup features are (re-)computed each time you train a new model. This lets your teams train models without repeating data preparation steps each time. You train a model with these features.
Delta Lake: Fueling insurance AI Centralizing data and creating a Delta Lakehouse architecture significantly enhances AI model training and performance, yielding more accurate insights and predictive capabilities. This article was made possible by our partnership with the IASA Chief Architect Forum.
What was once a preparatory task for training AI is now a core part of a continuous feedback and improvement cycle. Training compact, domain-specialized models that outperform general-purpose LLMs in areas like healthcare, legal, finance, and beyond. Todays annotation tools are no longer just for labeling datasets.
Or instead of writing one article for the company knowledge base on a topic that matters most to them, they might submit a dozen articles, on less worthwhile topics. You need people who are trained to see that. We had to figure this out and get our team trained,” she says.
The enterprise is about to get hit by the generative AI hype train, as Salesforce prepares to invest in startups developing what it calls “responsible generative AI.” This includes a new ChatGPT app for Slack , promising conversation summaries and writing assistance directly inside the enterprise communications app.
These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is a complex and resource-intensive process, often requiring specialized expertise and significant computational resources.
And to ensure a strong bench of leaders, Neudesic makes a conscious effort to identify high performers and give them hands-on leadership training through coaching and by exposing them to cross-functional teams and projects. “But for practical learning of the same technologies, we rely on the internal learning academy we’ve established.”
This article explores this shift signaling a new era for leadership — one where those who understand both the business landscape and the technical ecosystem are best positioned to lead. This article was made possible by our partnership with the IASA Chief Architect Forum. Invest in leadership development.
In that article, we talked about Andrej Karpathy’s concept of Software 2.0. We can collect many examples of what we want the program to do and what not to do (examples of correct and incorrect behavior), label them appropriately, and train a model to perform correctly on new inputs. Yes, but so far, they’re only small steps.
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., at Facebook—both from 2020. What is GraphRAG?
Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources. Unlike fine-tuning, in RAG, the model doesnt undergo any training and the model weights arent updated to learn the domain knowledge.
This article proposes a methodology for organizations to implement a modern data management function that can be tailored to meet their unique needs. This shift necessitates a new type of engineering-infused data organization, as described by the five pillars in this article.
I thought, OK, theres got to be some catch, and he did reveal that he could provide a development team to make my twin at a price or I could take some training and do it myself. So, I went to the website and discovered I could skip the training, subscribe and mess around with it. But I did write this article for you.
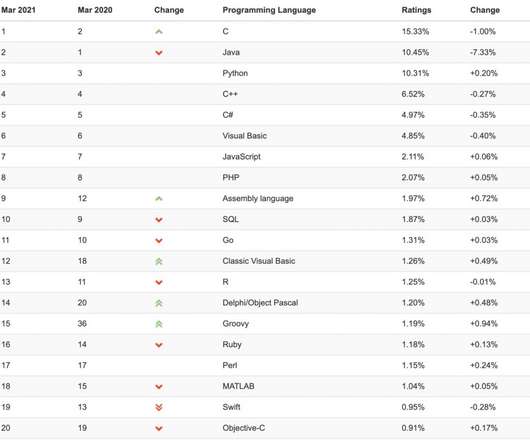
In this article, we will explore the top programming languages, their scope, market demand, and the expected average income when using these languages. Based on this data, we shall explore some of the top results in this article. Programming languages are constantly and rapidly evolving in the current world of technology. Conclusion.
Natural language processing definition Natural language processing (NLP) is the branch of artificial intelligence (AI) that deals with training computers to understand, process, and generate language. Every time you look something up in Google or Bing, you’re helping to train the system. It consists of 11.5
Making emissions estimations visible to architects and engineers, such as the metrics based on the Green Software Foundation Software Carbon Intensity , along with green systems design training gives them the tools to make sustainability optimizations early in the design process. Long-term value creation.
The 2024 State of the Tech Workforce from IT training and certification association CompTIA noted a similar gender gap in the field, finding that women make up just 27% of tech occupations. Worse, a significant percentage of women in tech want to leave.
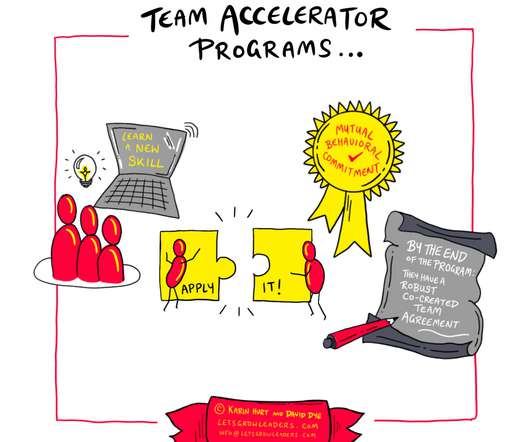
You need leaders at every level engaged with your training as leader coaches to facilitate application and learning. Imagine they were to kick off the training with a powerful story, then stay and engage with the team? Your training for ten just turned into impact for one hundred. The Power of Leaders as Coaches.
Companies use gen AI to create synthetic data, find and remove sensitive information from training data sets, add meaning and context to data, and perform other higher-level functions where traditional ML approaches fall short. We’re validating whether the training data we’re receiving actually increments the model,” he says.
and enterprise architects need to be cognizant of the persona impact, any organizational shifts, training, disruption (particularly when urgent changes like vulnerability patches cause conflicts) and the pace of change that businesses are capable of absorbing. Technology can stretch deep into the business (including IT!)
LLM or large language models are deep learning models trained on vast amounts of linguistic data so they understand and respond in natural language (human-like texts). USE CASES: Text/summary/article generation, chatbots, virtual assistants, custom AI solution development.
Workshops and pitch training: SB 200 founders will be invited to exclusive workshops and masterclasses in the weeks running up to Disrupt. They’ll receive special pitch training from TechCrunch staff and one free year of TechCrunch+ membership. The ultimate winner takes home the $100,000 equity-free prize.
The platform, produced by Vivendi, includes documentaries, podcasts, articles and interviews between experts and known players in the chess community. The premium product also grants users access to a database of 50,000 manually created puzzles that allows players to train certain skills. A popular competitor already exists: Chess.com.
This article is meant to be a short, relatively technical primer on what model debugging is, what you should know about it, and the basics of how to debug models in practice. 8] Data about individuals can be decoded from ML models long after they’ve trained on that data (through what’s known as inversion or extraction attacks, for example).
ChatGPT correctly, in my view said it could help by enhancing job opportunities and workforce training, including personalized job coaching and interview prep. What are 10 empathic ways generative AI could help them in their day-to-day lives? Notably, a Google search confirms that practice interviewing is recommended by the U.S.
Investment in training and change management is critical to the success. The CoE in this phase has to proactively engage ALL stakeholders, making them aware of the change in the mode of operation and guiding the team through training, coffee chats, and CoE sessions during this period of transformation.
Sports Illustrated and its CEO found this out recently when it was revealed the magazine published articles written by fake authors with AI-generated images. Researchers have predicted that high-quality text data used for training LLM models will run out before 2026 if current trends continue.
And psst… Dear Leader …if work without human-centered practical leadership training is getting a bit too edgy for your liking – or your strategies just aren’t working like you need them to – visit our Live (online or hybrid) Leadership Training page to learn how to build and sustain company-wide change.
Perhaps they could use training on how to effectively and efficiently lead their remote teams. First, make the decision on which approach you will take, and what success looks like BEFORE you start talking about what training partner to use, or best practices for time-off policies. Should it be in-person or live virtual training?
This article provides a detailed overview of the best AI programming tools in 2024. It uses OpenAI’s Codex, a language model trained on a vast amount of code from public repositories on GitHub. Cons Privacy Concerns : Since it is trained on public repositories, there may be concerns about code privacy and intellectual property.
This article delves into the transformative potential of AI, genAI and blockchain to drive sustainable innovation. Training large AI models, for example, can consume vast computing power, leading to significant energy consumption and carbon emissions.
The source of this disparity may be partly attributed to a lack of diversity in the datasets used to train these systems. This type of collection is a bit of a grey area, since no one explicitly consented to have their podcast used to train someone’s commercial speech recognition engine. for black speakers compared with 0.19
Workshops and pitch training: SB 200 founders will be invited to exclusive workshops and master classes in the weeks running up to Disrupt. They’ll receive special pitch training from TechCrunch staff and one free year of TechCrunch+ membership. The ultimate winner takes home the $100,000 equity-free prize.
But an article in the tech press said the academic field was amid a resurgence. As a result of 100x larger training data sets and 100x higher compute power becoming available by reprogramming GPUs (graphics cards), a huge leap in predictive performance had been attained in image classification a year earlier.
The article explains how some groups use LLMs to simulate human participants. Since these models are trained on human-generated data, they can emulate human responses across diverse psychological and behavioral experiments. Its mostly trained on data created by humans, so it picks up our natural tendencies.
Intelligent assistants are already changing how we search, analyze information, and do everything from creating code to securing networks and writing articles. So, does every enterprise need to build a dedicated AI development team and a supercomputer to train their own AI models? Not at all. But do be careful.
Once the common reasons are identified via the new mining feature, enterprises can develop a knowledge article or train an Einstein Bot to handle the common requests, the company said in a statement.
Addressing the challenges contact center agents face, such as stress from call volume and insufficient tech training, will be crucial in ensuring that customer-facing teams are equipped to deliver the high-quality service that customers expect, especially in times of crisis. To learn more, visit us here.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content