This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the rise of big data and data science, storage and retrieval have become a critical pipeline component for data use and analysis. Recently, new datastorage technologies have emerged. Which one is best suited for dataengineering? But the question is: Which one should you choose?
A cloud architect has a profound understanding of storage, servers, analytics, and many more. Big DataEngineer. Another highest-paying job skill in the IT sector is big dataengineering. And as a big dataengineer, you need to work around the big data sets of the applications. Conclusion.
A few months ago, I wrote about the differences between dataengineers and data scientists. An interesting thing happened: the data scientists started pushing back, arguing that they are, in fact, as skilled as dataengineers at dataengineering. Dataengineering is not in the limelight.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. This article will explore the technical details and steps to configure and use Azure Key Vault Secrets with Azure Synapse Analytics. This will store your Synapse workspaces data files.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. This greatly increases data processing capabilities.
So, along with data scientists who create algorithms, there are dataengineers, the architects of data platforms. In this article we’ll explain what a dataengineer is, the field of their responsibilities, skill sets, and general role description. What is a dataengineer?
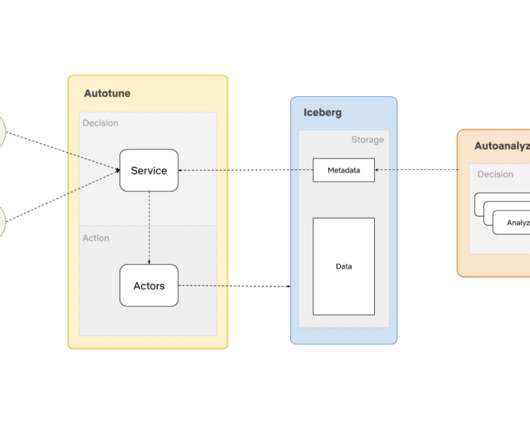
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Data Science and Machine Learning sessions will cover tools, techniques, and case studies. This year’s sessions on DataEngineering and Architecture showcases streaming and real-time applications, along with the data platforms used at several leading companies. Data platforms. Data Platforms sessions.
Are you a dataengineer or seeking to become one? This is the first entry of a series of articles about skills you’ll need in your everyday life as a dataengineer. This blog post is for you. So let’s begin with the first and, in my opinion, the most useful tool in your technical tool belt, SQL.
The idea that telemetry data needs to be managed, or needs a strategy, draws a lot of inspiration from the data world (as in, BI and DataEngineering). Your company most likely has a data team that manages the data warehouse(s), data pipelines, data sources, and reporting tools.
Decades ago, software engineering was hard because you had to build everything from scratch and solve all these foundational problems. You need storage to build something to serve 1M concurrent users? The counterpoint is that with increased decentralization, engineers will increasingly develop subject-matter experience.
Microsoft Fabric encompasses data movement, datastorage, dataengineering, data integration, data science, real-time analytics, and business intelligence, along with data security, governance, and compliance. To read this article in full, please click here
Organizations have balanced competing needs to make more efficient data-driven decisions and to build the technical infrastructure to support that goal. The features can be raw data that has been processed or analyzed or derived. The ML workflow for creating these features is referred to as feature engineering.
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Is it still so?
LinkedIn has decided to open source its data management tool, OpenHouse, which it says can help dataengineers and related data infrastructure teams in an enterprise to reduce their product engineering effort and decrease the time required to deploy products or applications.
Data obsession is all the rage today, as all businesses struggle to get data. But, unlike oil, data itself costs nothing, unless you can make sense of it. Dedicated fields of knowledge like dataengineering and data science became the gold miners bringing new methods to collect, process, and store data.
Let’s break them down: A data source layer is where the raw data is stored. Those are any of your databases, cloud-storages, and separate files filled with unstructured data. These are both a unified storage for all the corporate data and tools performing Extraction, Transformation, and Loading (ETL).
Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store. Storage costs. using list pricing of $0.72/hour hour using a r5d.4xlarge
While there is much to be said about cloud costs and performance , I want to focus this article primarily on reliability. More than anything, reliability becomes the principal challenge for network engineers working in and with the cloud. What is cloud network reliability?
However, when it comes to analyzing large volumes of data from different angles, the logic of OLTP has serious limitations. So, we need a solution that’s capable of representing data from multiple dimensions. In this article, we’ll talk about such a solution —- Online Analytical Processing , or OLAP technology.
This suggests that today, there are many companies that face the need to make their data easily accessible, cleaned up, and regularly updated. Hiring a well-skilled data architect can be very helpful for that purpose. What is a data architect? What is the main difference between a data architect and a dataengineer?
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. Impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
However, in today's era, what's more, important than the data itself is the ability to locate your wanted information among all the overflowing data quickly. So in this article, I will talk about how I improved overall data processing efficiency by optimizing the choice and usage of data warehouses.
This is the final blog in a series that explains how organizations can prevent their Data Lake from becoming a Data Swamp, with insights and strategy from Perficient’s Senior Data Strategist and Solutions Architect, Dr. Chuck Brooks. Once data is in the Data Lake, the data can be made available to anyone.
Windows Storage. Windows Storage Spaces Controller. Windows Task Flow DataEngine. Windows Tile Data Repository. Main Article Image. Windows Remote Procedure Call Runtime. Windows Resilient File System (ReFS). Windows Secure Boot. Windows Security Center. Windows StateRepository API. Windows System Launcher.
However, extracting valuable insights from the vast amount of data stored in ServiceNow often requires manual effort and building specialized tooling. A data source connector is a component of Amazon Q that helps integrate and synchronize data from multiple repositories into one index.
It builds on a foundation of technologies from CDH (Cloudera Data Hub) and HDP (Hortonworks Data Platform) technologies and delivers a holistic, integrated data platform from Edge to AI helping clients to accelerate complex data pipelines and democratize data assets. query failures, cost overruns).
Today’s general availability announcement covers Iceberg running within key data services in the Cloudera Data Platform (CDP) — including Cloudera Data Warehousing ( CDW ), Cloudera DataEngineering ( CDE ), and Cloudera Machine Learning ( CML ).
Moreover, the MicroStrategy Global Analytics Study reports that access to data is extremely limited, taking 60 percent of employees hours or even days to get the information they need. To generalize and describe the basic maturity path of an organization, in this article we will use the model based on the most common one suggested by Gartner.
Along with thousands of other data-driven organizations from different industries, the above-mentioned leaders opted for Databrick to guide strategic business decisions. In this article, we’ll highlight the reasoning behind this choice and the challenges related to it. How dataengineering works in 14 minutes.
” Deployments of large data hubs have only resulted in more data silos that are not easily understood, related, or shared. More focus will be on the operational aspects of data rather than the fundamentals of capturing, storing and protecting data.
Mark Huselid and Dana Minbaeva in Big Data and HRM call these measures the understanding of the workforce quality. In this article, we’ll discuss the purpose of people analytics, its common use cases, and provide a roadmap of implementing HR analytics into an organization. So, dataengineers make data pipelines work.
Please note: this topic requires some general understanding of analytics and dataengineering, so we suggest you read the following articles if you’re new to the topic: Dataengineering overview. Data visualization as a part of data representation and analytics. Time-period: 1st quarter of 2019.
Otherwise, let’s start from the most basic question: What is data migration? What is data migration? In general terms, data migration is the transfer of the existing historical data to new storage, system, or file format. What makes companies migrate their data assets. Main types of data migration.
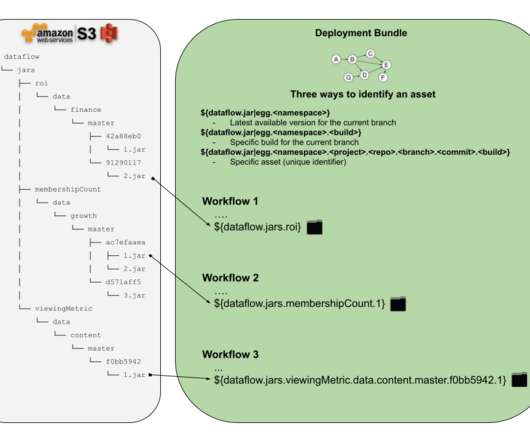
The answers to these questions is something we would like to address in this article and propose a clean solution to this problem. Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Storage provisioning.
With offerings spanning the many ways organizations can extract value from data from data pipelines to machine learning and even LLM training Databricks is often a critical component of modern data infrastructure. It operates on a cloud-native architecture , leveraging distributed computing to process large-scale data.
Which Big Data tasks does Spark solve most effectively? This article gives you all the answers — one by one. Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. Virtually, Hadoop puts no limits on the storage capacity. HDFS: a storage layer.
But while state and local governments seek to improve policies, decision making, and the services constituents rely upon, data silos create accessibility and sharing challenges that hinder public sector agencies from transforming their data into a strategic asset and leveraging it for the common good. .
In this article, we explore model governance, a function of ML Operations (MLOps). In the case of CDP Public Cloud, this includes virtual networking constructs and the data lake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Model Visibility. Model Explainability.
Similar to humans companies generate and collect tons of data about the past. And this data can be used to support decision making. While our brain is both the processor and the storage, companies need multiple tools to work with data. And one of the most important ones is a data warehouse. Subject-oriented data.
With CDP, customers can deploy storage, compute, and access, all with the freedom offered by the cloud, avoiding vendor lock-in and taking advantage of best-of-breed solutions. Multi-cloud capability is now available for Apache Iceberg in CDP. Enhanced multi-function analytics.
In most digital spheres, especially in fintech, where all business processes are tied to data processing, a good big dataengineer is worth their weight in gold. In this article, we’ll discuss the role of an ETL engineer in data processing and why businesses need such experts nowadays. Manage ETL processes.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content