This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Step 1: Data ingestion Identify your data sources. First, list out all the insurance data sources. These include older systems (like underwriting, claims processing and billing) as well as newer streams (like telematics, IoT devices and external APIs). Collect your data in one place.
IoT Architect. Learning about IoT or the Internet of Things can be significant if you want to learn one of the most popular IT skills. It is the technology that helps in transforming current technology in terms of communication and data sharing. Currently, the IoT architects are paid up to Rs20,00,000 per annum.
In the rapidly evolving landscape of the Internet of Things ( IoT ), achieving seamless interoperability among a myriad of devices and systems is paramount. To tackle this challenge head-on, software-based architectures are emerging as powerful solutions.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. Big data processing. maintaining data pipeline.
For data warehouses, it can be a wide column analytical table. Many companies reach a point where the rate of complexity exceeds the ability of dataengineers and architects to support the data change management speed required for the business.
They also launched a plan to train over a million data scientists and dataengineers on Spark. As data and analytics are embedded into the fabric of business and society –from popular apps to the Internet of Things (IoT) –Spark brings essential advances to large-scale data processing. Related articles.
Titanium Intelligent Solutions, a global SaaS IoT organization, even saved one customer over 15% in energy costs across 50 distribution centers , thanks in large part to AI. An enterprise data ecosystem architected to optimize data flowing in both directions. Learn how DataStax enables real-time AI.
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. Impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
With the uprise of internet-of-things (IoT) devices, overall data volume increase, and engineering advancements in this field led to new ways of collecting, processing, and analysing data. As a result, it became possible to provide real-time analytics by processing streamed data. Source: www.oracle.com.
CIO.com’s 2023 State of the CIO survey recently zeroed in on the technology roles that IT leaders find the most difficult to fill, with cybersecurity, data science and analytics, and AI topping the list. S&P Global also needs complementary skills in software architecture, multicloud, and dataengineering to achieve its AI aims. “It
Ronald van Loon has been recognized among the top 10 global influencers in Big Data, analytics, IoT, BI, and data science. As the director of Advertisement, he works to help data-driven businesses be more successful. He regularly publishes articles on Big Data and Analytics on Forbes. Bernard Marr.
These challenges can be addressed by intelligent management supported by data analytics and business intelligence (BI) that allow for getting insights from available data and making data-informed decisions to support company development. Supply chain management process. Cost control. Shipment tracking and vehicle maintenance.
This article. It facilitates collaboration between a data science team and IT professionals, and thus combines skills, techniques, and tools used in dataengineering, machine learning, and DevOps — a predecessor of MLOps in the world of software development. Data validation. Data preparation.
” Deployments of large data hubs have only resulted in more data silos that are not easily understood, related, or shared. In order to utilize the wealth of data that they already have, companies will be looking for solutions that will give comprehensive access to data from many sources.
In this article, we´ll be your guide to the must-attend tech conferences set to unfold in October. This tech conference is a great opportunity for all professionals and organizations working with the utilization of Data Science, Machine, and Deep Learning to innovate and improve their businesses. Interested in attending?
Moreover, the MicroStrategy Global Analytics Study reports that access to data is extremely limited, taking 60 percent of employees hours or even days to get the information they need. To generalize and describe the basic maturity path of an organization, in this article we will use the model based on the most common one suggested by Gartner.
This article will explore the topic and its importance, how some insurers are already implementing it as their business model, how to approach personalization, and the challenges companies may encounter trying to implement it. You’ll need a dataengineering team for that. How dataengineers and data platforms work.
Finally, IaaS deployments required substantial manual effort for configuration and ongoing management that, in a way, accentuated the complexities that clients faced deploying legacy Hadoop implementations in the data center. Experience configuration / use case deployment: At the data lifecycle experience level (e.g.,
This blog will focus more on providing a high level overview of what a data mesh architecture is and the particular CDF capabilities that can be used to enable such an architecture, rather than detailing technical implementation nuances that are beyond the scope of this article. Introduction to the Data Mesh Architecture.
From emerging trends to hiring a data consultancy, this article has everything you need to navigate the data analytics landscape in 2024. What is a data analytics consultancy? Big data consulting services 5. 4 types of data analysis 6. Data analytics use cases by industry 7. Table of contents 1.
If your business generates tons of data and you’re looking for ways to organize it for storage and further use, you’re at the right place. Read the article to learn what components data management consists of and how to implement a data management strategy in your business. Key disciplines and roles in data management.
Similar to Google in web browsing and Photoshop in image processing, it became a gold standard in data streaming, preferred by 70 percent of Fortune 500 companies. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka? Kafka cluster and brokers. Red Hat , acquired by IBM.
Transferring data from one computer environment to another is a time-consuming, multi-step process involving such activities as planning, data profiling, testing, to name a few. You can read more about it in our previous articleData Migration: Process, Types, and Golden Rules to Follow. Data sources and destinations.
In this article, I want to underscore why NetOps has an integral role (and more responsibility) in delivering on the promise of reliability and highlight a few examples of how engineering for reliability can make networks less reliable. I wrote an article a while ago addressing latency.
As we discussed in one of our previous articles, there are three main types of maintenance policies : reactive, preventive, and predictive (the two latter categories are referred to as proactive maintenance). Data is gathered from connected sensors and analyzed so that predictions of possible failures can be generated.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Make sure to check out our dedicated article.
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore data collection approaches and tools for analytics and machine learning projects. What is data collection?
Whether your goal is data analytics or machine learning , success relies on what data pipelines you build and how you do it. But even for experienced dataengineers, designing a new data pipeline is a unique journey each time. Dataengineering in 14 minutes. Data availability. Please note!
She formulated the thesis in 2018 and published her first article “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh” in 2019. Since that time, the data mesh concept has received a lot of attention and appreciation from companies pioneering this idea. Decentralized data ownership by domain.
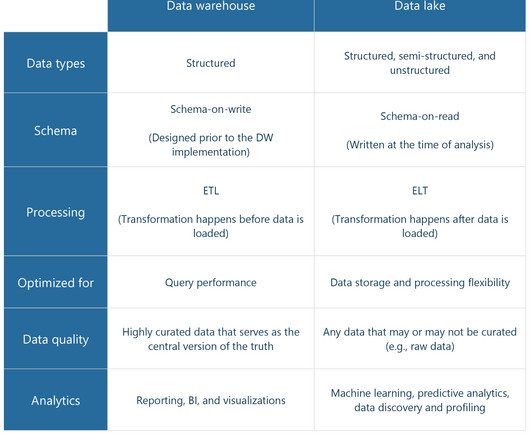
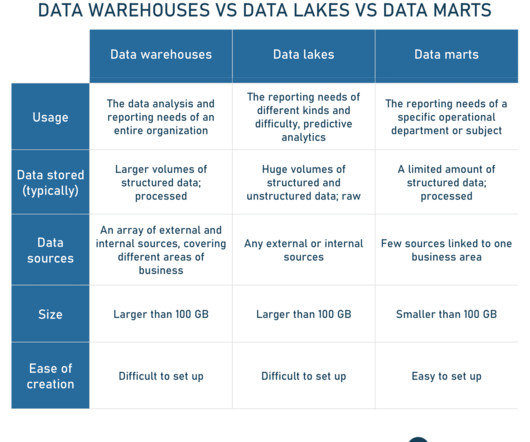
And this data can be used to support decision making. While our brain is both the processor and the storage, companies need multiple tools to work with data. And one of the most important ones is a data warehouse. Reflects the source data. And this is what makes a data warehouse different from a Data Lake.
Which Big Data tasks does Spark solve most effectively? This article gives you all the answers — one by one. No real-time data processing. MapReduce performs batch processing only and doesn’t fit time-sensitive data or real-time analytics jobs. Owing to this fact, Spark doesn’t perfectly suit IoT solutions.
These seemingly unrelated terms unite within the sphere of big data, representing a processing engine that is both enduring and powerfully effective — Apache Spark. Before diving into the world of Spark, we suggest you get acquainted with dataengineering in general. How dataengineering works in a nutshell.
Information often resides across countless distributed data sources, resulting in data silos. To get a single unified view of all information, companies opt for data integration. What is data integration and why is it important? These systems can be hosted on-premises, in the cloud, and on IoT devices, etc.
In the past year or so, various folks at Kentik have been blogging, podcasting , and writing articles about the need for cloud-based Network Performance Monitoring (NPM). By creating a distributed big data backend that’s purpose-built for the scale and speed of today’s network traffic.
Due to extensive usage of connected IoT devices and advanced processing technologies, SCCTs not only gather data and build operational reports but also create predictions, define the impact of various macro- and microeconomic factors on the supply chain, and run “what-if” scenarios to find the best course of action. Data siloes.
A data lake is a repository to store huge amounts of raw data in its native formats ( structured, unstructured, and semi-structured ) and in open file formats such as Apache Parquet for further big data processing, analysis, and machine learning purposes. Moreover, they support real-time data, e.g., streams from IoT devices.
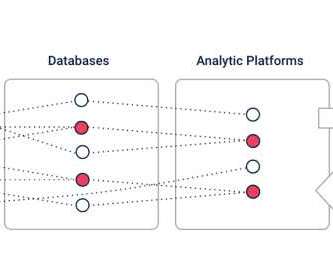
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , data warehouses , data lakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
This development has paved the way for a suite of cloud-native data tools that are user-friendly, scalable, and affordable. Known as the Modern Data Stack (MDS) , this suite of tools and technologies has transformed how businesses approach data management and analysis. Data democratization.
Read the article. In 2010, they launched Windows Azure, the PaaS, positioning it as an alternative to Google App Engine and Amazon EC2. Along with meeting customer needs for computing and storage, they continued extending services by presenting products dealing with analytics, Big Data, and IoT. Read the article.
But what happens to all the massive amounts of data from all these wearables and other medical and non-medical devices? In this article, we will explain the concept and usage of Big Data in the healthcare industry and talk about its sources, applications, and implementation challenges. Big Data infrastructure in healthcare.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































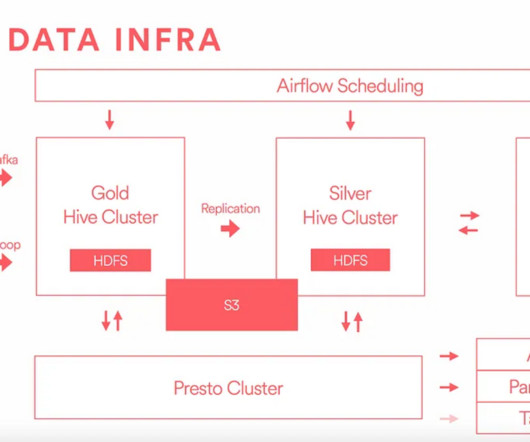










Let's personalize your content