This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can use these agents through a process called chaining, where you break down complex tasks into manageable tasks that agents can perform as part of an automated workflow. It’s important to break it down this way so you can see beyond the hype and understand what is specifically being referred to. Do you see any issues?
The company says it can achieve PhD-level performance in challenging benchmark tests in physics, chemistry, and biology. In these uses case, we have enough reference implementations to point to and say, Theres value to be had here.' Now, it will evolve again, says Malhotra. Agents are the next phase, he says.
In todays digital-first economy, enterprise architecture must also evolve from a control function to an enablement platform. This transformation requires a fundamental shift in how we approach technology delivery moving from project-based thinking to product-oriented architecture. The stakes have never been higher.
Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements. In contrast, more complex questions might require the application to summarize a lengthy dissertation by performing deeper analysis, comparison, and evaluation of the research results.
It prevents vendor lock-in, gives a lever for strong negotiation, enables business flexibility in strategy execution owing to complicated architecture or regional limitations in terms of security and legal compliance if and when they rise and promotes portability from an application architecture perspective.
Thinking refers to an internal reasoning process using the first output tokens, allowing it to solve more complex tasks. Native Multi-Agent Architecture: Build scalable applications by composing specialized agents in a hierarchy. Built-in Evaluation: Systematically assess agent performance. Gemini 2.5
Because of the adoption of containers, microservices architectures, and CI/CD pipelines, these environments are increasingly complex and noisy. These changes can cause many more unexpected performance and availability issues.
By implementing this architectural pattern, organizations that use Google Workspace can empower their workforce to access groundbreaking AI solutions powered by Amazon Web Services (AWS) and make informed decisions without leaving their collaboration tool. In the following sections, we explain how to deploy this architecture.
With this in mind, we embarked on a digital transformation that enables us to better meet customer needs now and in the future by adopting a lightweight, microservices architecture. We found that being architecturally led elevates the customer and their needs so we can design the right solution for the right problem.
Tech roles are rarely performed in isolation. Example: A candidate might perform well in a calm, structured interview environment but struggle to collaborate effectively in high-pressure, real-world scenarios like product launches or tight deadlines. Why interpersonal skills matter in tech hiring ?
Their DeepSeek-R1 models represent a family of large language models (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. 70B-Instruct ), offer different trade-offs between performance and resource requirements.
Infinidat added cyber resilience on its InfiniGuard ® secondary storage system during the past year and, at the end of April 2022, across its primary storage platforms with the InfiniSafe ReferenceArchitecture, encompassing Infinidat’s complete portfolio.
Shared components refer to the functionality and features shared by all tenants. You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures. If it leads to better performance, your existing default prompt in the application is overridden with the new one.
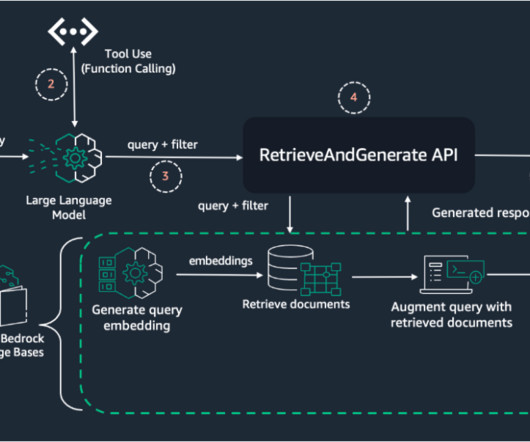
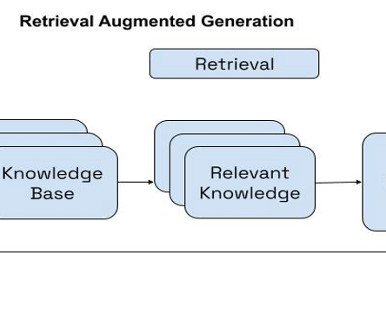
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. The solution incorporates the following key features: Using a Retrieval Augmented Generation (RAG) architecture, the system generates a context-aware detailed assessment.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. For instructions on how to start your Amazon Bedrock batch inference job, refer to Enhance call center efficiency using batch inference for transcript summarization with Amazon Bedrock.
Private cloud architecture is an increasingly popular approach to cloud computing that offers organizations greater control, security, and customization over their cloud infrastructure. What is Private Cloud Architecture? Why is Private Cloud Architecture important for Businesses?
Model Variants The current DeepSeek model collection consists of the following models: DeepSeek-V3 An LLM that uses a Mixture-of-Experts (MoE) architecture. These models retain their existing architecture while gaining additional reasoning capabilities through a distillation process.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline. Model customization refers to adapting a pre-trained language model to better fit specific tasks, domains, or datasets. Optimized for cost-effective performance, they are trained on data in over 200 languages.
It arrives alongside the announcement of SAP’s Open ReferenceArchitecture project as part of the EU’s IPCEI-CIS initiative. Organizations are choosing these platforms based on effective cost, performance, and scalability.”
Security and compliance regulations require that security teams audit the actions performed by systems administrators using privileged credentials. Video recordings cant be easily parsed like log files, requiring security team members to playback the recordings to review the actions performed in them.
These models are tailored to perform specialized tasks within specific domains or micro-domains. They can host the different variants on a single EC2 instance instead of a fleet of model endpoints, saving costs without impacting performance. The following diagram is the solution architecture.
For more on MuleSofts journey to cloud computing, refer to Why a Cloud Operating Model? The following diagram shows the referencearchitecture for various personas, including developers, support engineers, DevOps, and FinOps to connect with internal databases and the web using Amazon Q Business.
Increasingly, as Moore’s law rears its ugly head, computer chip developers are adopting “chiplet” architectures to scale their hardware’s processing power. “Process” in chip lingo refers to an architectural platform; TSMC began mass-producing 5 nm chips in 2020.
To achieve optimal performance for specific use cases, customers are adopting and adapting these FMs to their unique domain requirements. Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Evaluation, on the other hand, involves assessing the quality and relevance of the generated outputs, enabling continual improvement. versions, catering to different programming preferences.
Seamlessly integrate with APIs – Interact with existing business APIs to perform real-time actions such as transaction processing or customer data updates directly through email. Solution overview This section outlines the architecture designed for an email support system using generative AI.
While multi-cloud generally refers to the use of multiple cloud providers, hybrid encompasses both cloud and on-premises integrations, as well as multi-cloud setups. A leading meal kit provider migrated its data architecture to Cloudera on AWS, utilizing Cloudera’s Open Data Lakehouse capabilities.
To maximize performance and optimize training, organizations frequently need to employ advanced distributed training strategies. In a transformer architecture, such layers are the embedding layers and the multilayer perceptron (MLP) layers. and prior Llama models) and Mistral model architectures for context parallelism.
However, enabling external users to access raw data while maintaining security and lineage integrity requires a well-thought-out architecture. This blog outlines a referencearchitecture to achieve this balance. Recommended Architecture 1. Allow external users to access raw data without compromising governance.
In this post, we evaluate different generative AI operating model architectures that could be adopted. Governance in the context of generative AI refers to the frameworks, policies, and processes that streamline the responsible development, deployment, and use of these technologies.
How does High-Performance Computing on AWS differ from regular computing? For this HPC will bring massive parallel computing, cluster and workload managers and high-performance components to the table. Each job references a job definition. Today’s server hardware is powerful enough to execute most compute tasks.
Its improved architecture, based on the Multimodal Diffusion Transformer (MMDiT), combines multiple pre-trained text encoders for enhanced text understanding and uses QK-normalization to improve training stability. The model demonstrates improved performance in image quality, typography, and complex prompt understanding.
CBRE, in parallel, completed UAT testing to confirm it performed as expected. The following figure illustrates the core architecture for the NLQ capability. Following steps 5 and 6 in the architecture, the relevant tables schema is sent as input context to the model to generate a SQL query according to the input NLQ.
Amazon Bedrock cross-Region inference capability that provides organizations with flexibility to access foundation models (FMs) across AWS Regions while maintaining optimal performance and availability. Instead, the system dynamically routes traffic across multiple Regions, maintaining optimal resource utilization and performance.
RAG is an approach that combines information retrieval techniques with natural language processing (NLP) to enhance the performance of text generation or language modeling tasks. This is a reference notebook, and it cannot run unless you make changes suggested in the notebook. Refrain from using full access in production environments.
Event-driven operations management Operational events refer to occurrences within your organization’s cloud environment that might impact the performance, resilience, security, or cost of your workloads. The following diagram illustrates the solution architecture.
For some content, additional screening is performed to generate subtitles and captions. The general architecture of the metadata pipeline consists of two primary steps: Generate transcriptions of audio tracks: use speech recognition models to generate accurate transcripts of the audio content.
The following diagram illustrates the architecture of the application. Authentication is performed against the Amazon Cognito user pool. For more details about the authentication and authorization flows, refer to Accessing AWS services using an identity pool after sign-in.
When possible, refer all matters to committees for “further study and consideration” Attempt to make committees as large as possible — never less than five. Refer back to matters decided upon at the last meeting and attempt to re-open the question of the advisability of that decision.
Most of the manufacturing companies of CPU processors are working hard to improve the performance of CPUs. And to increase the performance at a high level, they used various techniques and enhanced the technology they used. Hyper-threading technology is used to increase the speed and performance of the CPU. Hyperthreading.
This capability enables Anthropics Claude models to identify whats on a screen, understand the context of UI elements, and recognize actions that should be performed such as clicking buttons, typing text, scrolling, and navigating between applications. The following diagram illustrates the solution architecture.
As more enterprises migrate to cloud-based architectures, they are also taking on more applications (because they can) and, as a result of that, more complex workloads and storage needs. Machine learning and other artificial intelligence applications add even more complexity.
The visual reference tool is probably handy for set directors that want to visualize props for certain scenes. This includes animal handling, children’s safety, copyright law objects, stunt performance requirements and even COVID safety measures. For instance, what the feather will look like at the beginning of “Forrest Gump.”
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content