This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Among these signals, OpenTelemetry metrics are crucial in helping engineers understand their systems. In this blog, well explore OpenTelemetry metrics, how they work, and how to use them effectively to ensure your systems and applications run smoothly. What are OpenTelemetry metrics?
It prevents vendor lock-in, gives a lever for strong negotiation, enables business flexibility in strategy execution owing to complicated architecture or regional limitations in terms of security and legal compliance if and when they rise and promotes portability from an application architecture perspective.
phenomenon We’ve all heard the slogan, “metrics, logs, and traces are the three pillars of observability.” You probably use some subset (or superset) of tools including APM, RUM, unstructured logs, structured logs, infra metrics, tracing tools, profiling tools, product analytics, marketing analytics, dashboards, SLO tools, and more.
DeepSeek-R1 distilled variations From the foundation of DeepSeek-R1, DeepSeek AI has created a series of distilled models based on both Metas Llama and Qwen architectures, ranging from 1.570 billion parameters. Sufficient local storage space, at least 17 GB for the 8B model or 135 GB for the 70B model.
Designing software that is flexible and changeable is arguably the most important architectural property. However, if we optimise our architecture for change (evolvability), when we discover a performance issue or a security vulnerability we can change our system to help address it. Without mandating a specific architecture (e.g.
Our digital transformation has coincided with the strengthening of the B2C online sales activity and, from an architectural point of view, with a strong migration to the cloud,” says Vibram global DTC director Alessandro Pacetti. It’s a change fundamentally based on digital capabilities.
The Top Storage Trends for 2022. As 2021 heads to the finish line, we look at the storage market to see an exciting 2022 right around the corner. Understanding these enterprise storage trends will give you an advantage and help you formulate your strategic IT plan going forward. Adriana Andronescu. Thu, 12/16/2021 - 04:00.
The Model-View-ViewModel (MVVM) architectural pattern is widely adopted in Android app development. Unit testing each layer in an MVVM architecture offers numerous benefits: Early Bug Detection: Identify and fix issues before they propagate to other parts of the app. Data Storage: Test how the Repository stores and retrieves data.
Using Zero Trust Architecture (ZTA), we rely on continuous authentication, least privilege access, and micro-segmentation to limit data exposure. He also stands by DLP protocol, which monitors and restricts unauthorized data transfers, and prevents accidental exposure via email, cloud storage, or USB devices.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Evaluation, on the other hand, involves assessing the quality and relevance of the generated outputs, enabling continual improvement. versions, catering to different programming preferences.
In their thought-provoking presentation titled “Pragmatic Approach to ArchitectureMetrics” at GSAS’22 organized by Apiumhub , Sonya Natanzon, and Vlad Khononov delivered valuable insights. The success of software architecture hinges upon its adaptability to meet evolving business requirements. Code Coverage 2.
It seems like everyone is into microservices these days, and monolith architectures are slowly fading into obscurity. In monolithic applications, it is reflected in the separation of Presentation, Business and Data Layers in a typical 3-tier architecture. Editor’s Note: This post was originally published on May 5, 2016.
Model monitoring of key NLP metrics was incorporated and controls were implemented to prevent unsafe, unethical, or off-topic responses. The first data source connected was an Amazon Simple Storage Service (Amazon S3) bucket, where a 100-page RFP manual was uploaded for natural language querying by users.
Moreover, Amazon Bedrock offers integration with other AWS services like Amazon SageMaker , which streamlines the deployment process, and its scalable architecture makes sure the solution can adapt to increasing call volumes effortlessly. This is powered by the web app portion of the architecture diagram (provided in the next section).
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. We walk through the key components and services needed to build the end-to-end architecture, offering example code snippets and explanations for each critical element that help achieve the core functionality.
Essentially, Coralogix allows DevOps and other engineering teams a way to observe and analyze data streams before they get indexed and/or sent to storage, giving them more flexibility to query the data in different ways and glean more insights faster (and more cheaply because doing this pre-indexing results in less latency).
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
MaestroQA also offers a logic/keyword-based rules engine for classifying customer interactions based on other factors such as timing or process steps including metrics like Average Handle Time (AHT), compliance or process checks, and SLA adherence. The following architecture diagram demonstrates the request flow for AskAI.
The architecture seamlessly integrates multiple AWS services with Amazon Bedrock, allowing for efficient data extraction and comparison. The following diagram illustrates the solution architecture. These challenges highlighted the need for a more streamlined and efficient approach to the submission and review process.
You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures. A centralized service that exposes APIs for common prompt-chaining architectures to your tenants can accelerate development. As a result, building such a solution is often a significant undertaking for IT teams.
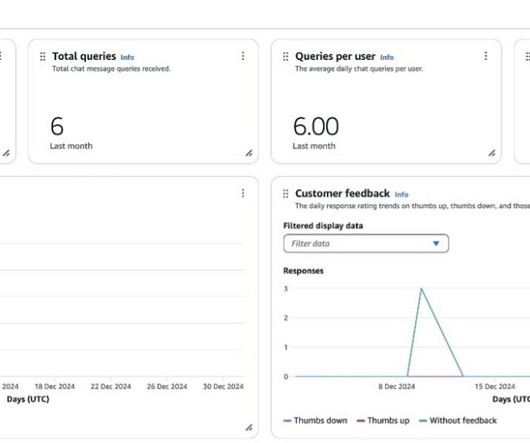
By monitoring utilization metrics, organizations can quantify the actual productivity gains achieved with Amazon Q Business. Tracking metrics such as time saved and number of queries resolved can provide tangible evidence of the services impact on overall workplace productivity.
The following diagram illustrates the solution architecture: The steps of the solution include: Upload data to Amazon S3 : Store the product images in Amazon Simple Storage Service (Amazon S3). Distance metric : Select Euclidean. In this post, you will use OpenSearch Serverless as the vector database for the image embeddings.
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. The following diagram illustrates the conceptual architecture of an AI assistant with Amazon Bedrock IDE.
In many companies, data is spread across different storage locations and platforms, thus, ensuring effective connections and governance is crucial. And data.world ([link] a company that we are particularly interested in because of their knowledge graph architecture. Poor data quality automatically results in poor decisions.
ZIRP was in full bloom, infrastructures were comparatively simpler (and thus cheaper), and a lot of people were pursuing a best of breed tooling strategy where they tried to pick the best tracing tool, best metrics tool, best APM, best RUM, etc., even if they were all from different vendors. All of which drove up costs.
But without enforceable standards and metrics, its difficult for IT and security leaders to assess whether and how vendors are carrying out this secure by design approach. You look at the solutions entire architecture and consider security in all areas, such as architecture design, storage, connectivity, usage, and so on.
The underlying large-scale metricsstorage technology they built was eventually open sourced as M3. Mao and co-founder Rob Skillington (CTO) founded Chronosphere on the back of early work that they started at Uber, where they built an observability platform very specific to Uber’s needs as a business.
Our proposed architecture provides a scalable and customizable solution for online LLM monitoring, enabling teams to tailor your monitoring solution to your specific use cases and requirements. Overview of solution The first thing to consider is that different metrics require different computation considerations.
According to a recent IDC whitepaper , leaders saw on average two and a half times better results than other organizations in many business metrics. Data formats and data architectures are often inconsistent, and data might even be incomplete. Most organizations don’t end up with data lakes, says Orlandini.
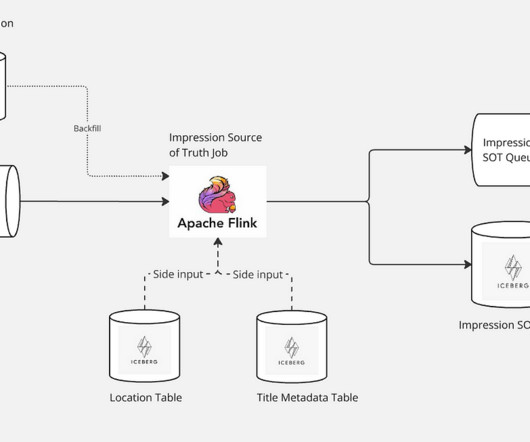
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
Model Variants The current DeepSeek model collection consists of the following models: DeepSeek-V3 An LLM that uses a Mixture-of-Experts (MoE) architecture. These models retain their existing architecture while gaining additional reasoning capabilities through a distillation process. meta-llama/Llama-3.2-11B-Vision-Instruct
With the paradigm shift from the on-premises data center to a decentralized edge infrastructure, companies are on a journey to build more flexible, scalable, distributed IT architectures, and they need experienced technology partners to support the transition.
Second, there is no one-size-fits-all SaaS architecture (the second principle is a corollary of the first). The challenge is to build common ground between business and architecture so as to translate business assumptions into critical technical solution inputs. This is known as a unit metric.
Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others. These recipes are processed through the HyperPod recipe launcher, which serves as the orchestration layer responsible for launching a job on the corresponding architecture.
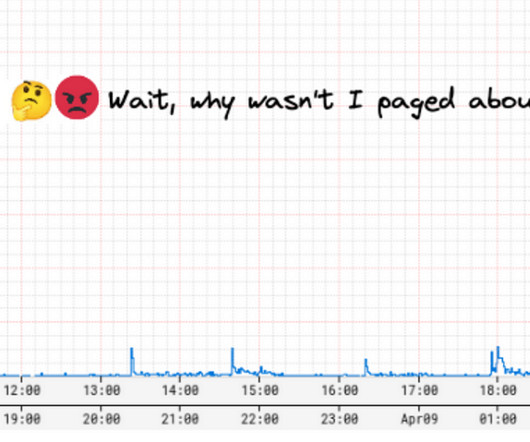
A few years ago, we were paged by our SRE team due to our Metrics Alerting System falling behind — critical application health alerts reached engineers 45 minutes late! Hence, we started down the path of alert evaluation via real-time streaming metrics.
A key challenge with organizational alignment is communicating across all departments the goals, metrics, and benefits of a process or function. The recognition of data’s value to a business has led to many metrics and measures focused on data and its quality. Departmental or individual recognition and rewards.
Introduction Ozone is an Apache Software Foundation project to build a distributed storage platform that caters to the demanding performance needs of analytical workloads, content distribution, and object storage use cases. Cisco has multiple reference architectures for running Ozone.
In this post, we describe the development journey of the generative AI companion for Mozart, the data, the architecture, and the evaluation of the pipeline. Solution overview The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage. The following diagram illustrates the solution architecture.
Honeycomb’s SLOs allow teams to define, measure, and manage reliability based on real user impact, rather than relying on traditional system metrics like CPU or memory usage. Instead, they consolidate logs, metrics, and traces into a unified workflow.
Metric tons of carbon dioxide equivalents (MTCO2e): The unit of measurement for calculating impact. Architecture Region selection: AWS regions are running datacenters on local grids. AWS Architecture Blog has a blog post on How to select a Region for your workload based on sustainability goals. This will reduce emissions.
Traditionally, documents from portals, email, or scans are stored in Amazon Simple Storage Service (Amazon S3) , requiring custom logic to split multi-document packages. This architecture enhances automated data processing, efficient retrieval, and seamless real-time access to insights.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. This is illustrated in the following figure.
The following diagram illustrates the solution architecture. Under Input data , enter the location of the source S3 bucket (training data) and target S3 bucket (model outputs and training metrics), and optionally the location of your validation dataset. For Job name , enter a name for the fine-tuning job.
Machine learning production pipeline architecture. Here we’ll look at the common architecture and the flow of such a system. This storage for features provides the model with a quick access to data that can’t be accessed from the client. We’ll break the process by the actions, outlining main tools used for specific operations.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content