This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By implementing this architectural pattern, organizations that use Google Workspace can empower their workforce to access groundbreaking AI solutions powered by Amazon Web Services (AWS) and make informed decisions without leaving their collaboration tool. This request contains the user’s message and relevant metadata.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Loadbalancer – Another option is to use a loadbalancer that exposes an HTTPS endpoint and routes the request to the orchestrator. API Gateway also provides a WebSocket API.
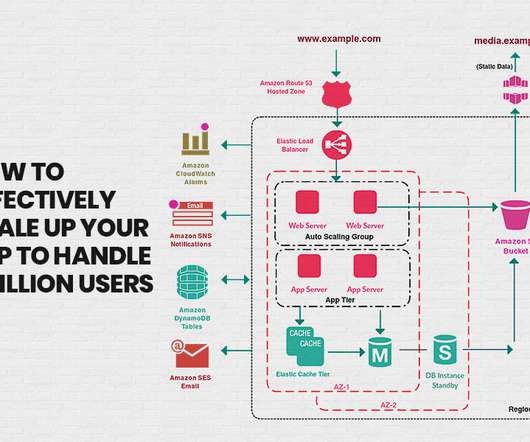
Architecture Overview The accompanying diagram visually represents our infrastructure’s architecture, highlighting the relationships between key components. We will also see how this new method can overcome most of the disadvantages we identified with the previous approach. Without further ado, let’s get into the business!
The goal is to deploy a highly available, scalable, and secure architecture with: Compute: EC2 instances with Auto Scaling and an Elastic LoadBalancer. In this architecture, Pulumi interacts with AWS to deploy multiple services. Components in the architecture. How Pulumi Works in This Architecture 1.
This resembles a familiar concept from Elastic LoadBalancing. A target group can refer to Instances, IP addresses, a Lambda function or an Application LoadBalancer. In a well-architected microservice architecture, there is a good chance this is true. However, it does have consequences.
This is done using ReAct prompting, which breaks down the task into a series of steps that are processed sequentially: For device metrics checks, we use the check-device-metrics action group, which involves an API call to Lambda functions that then query Amazon Athena for the requested data. It serves as the data source to the knowledge base.
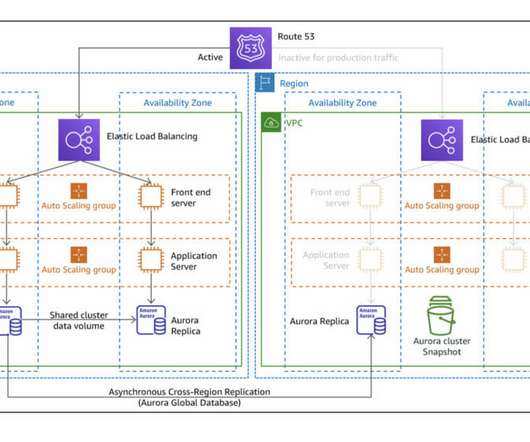
This post explores a proof-of-concept (PoC) written in Terraform , where one region is provisioned with a basic auto-scaled and load-balanced HTTP * basic service, and another recovery region is configured to serve as a plan B by using different strategies recommended by AWS. Pilot Light strategy diagram.
Event-driven compute with AWS Lambda is a good fit for compute-intensive, on-demand tasks such as document embedding and flexible large language model (LLM) orchestration, and Amazon API Gateway provides an API interface that allows for pluggable frontends and event-driven invocation of the LLMs.
AWS System Administration — Federico Lucifredi and Mike Ryan show developers and system administrators how to configure and manage AWS services, including EC2, CloudFormation, Elastic LoadBalancing, S3, and Route 53.
The work done by software we ourselves develop was both the easiest to move – because we control the build, and so could re-compile for the Arm architecture – and the highest-impact, as it makes up the bulk of our compute spend. Instances[]' | jq -cs '.[] | {arch: Architecture, type: InstanceType, tags: (.Tags//[])|from_entries|{name:
In an effort to avoid the pitfalls that come with monolithic applications, Microservices aim to break your architecture into loosely-coupled components (or, services) that are easier to update independently, improve, scale and manage. Key Features of Microservices Architecture. Microservices Architecture on AWS.
NoOps is supported by modern technologies such as Infrastructure as Code (IaC), AI-driven monitoring, and serverless architectures. Cost-Effectiveness through Serverless Computing: Utilizes serverless architectures (e.g., No manual oversight is required for routine traditional IT operations.
It’s also an architectural pattern, which was initially created to support microservices. A tool called loadbalancer (which in old days was a separate hardware device) would then route all the traffic it got between different instances of an application and return the response to the client. Loadbalancing.
Automated ETL trigger AWS EventBridge triggers the AWS Lambda based on events, which in turn initiates a job. Elastic LoadBalancing (ELB) ensures dynamic scaling to manage varying levels of traffic, enhancing app availability. AWS Lambda provides serverless computing & scales based on the number of requests.
Evaluating Public Access Across Cloud Providers Many architectural design questions arise when it comes to the use of serverless functions in cloud environments. AWS Cheat Sheet: Is my Lambda exposed? Security Considerations for AWS Lambda Functions AWS’ main serverless offering is Lambda functions. Already an expert?
You can also build automation using Lambda Functions with custom triggers like AutoScaling Lifecycle Hooks, have a LoadBalancer in front of your servers to balance the traffic as well as have DNS management in Route53.
But scaling is usually more about the application’s internals than about the high-level architecture and tooling. For instance, you can scale a monolith by deploying multiple instances with a loadbalancer that supports affinity flags. This is the point at which you probably need an orchestrator like Kubernetes.
Evaluate stability – A regular release schedule, continuous performance, dispersed platforms, and loadbalancing are key components of a successful and stable platform deployment. You want to remain on-premises while continuing to benefit from Azure development, you can choose Azure’s hybrid-cloud architecture.
With Honeycomb, the engineering team at IMO was able to find hidden architectural issues that were previously obscured in their logs. The primary hosting pattern to migrate was a.NET application running on a Windows instance behind a loadbalancer. Over 4,500 hospitals and 500,000 physicians use IMO products on a daily basis.
Use the Trusted Advisor Idle LoadBalancers Check to get a report of loadbalancers that have a request count of less than 100 over the past seven days. Then, you can delete these loadbalancers to reduce costs. Additionally, you can also review data transfer costs using Cost Explorer.
Serverless computing, or more simply “Serverless,” is not easy to define, but for the sake of this article, we can loosely define it as a software architecture trend that reduces the notion of infrastructure. The chosen platform manages the resources, allowing developers to just focus on their code.
Trusted Advisor (charged as a percentage of total AWS spend) makes recommendations to reduce cost, including identifying target EC2 instances to convert to RIs, underutilized EC2 resources such as instances, loadbalancers, EBS volumes and Elastic IP addresses. Lambda – Cost Optimization. Recommend alternate clouds.
Trusted Advisor (charged as a percentage of total AWS spend) makes recommendations to reduce cost, including identifying target EC2 instances to convert to RIs, underutilized EC2 resources such as instances, loadbalancers, EBS volumes and Elastic IP addresses. Lambda – Cost Optimization. Recommend alternate clouds.
In simple words, if you are already managing the workload on the cloud and still need to expand its efficiency then you need to use additional services to manage the load. This is where you need to expand your cloud architecture by adding more units of small capacity to spill the workload on multiple machines. Let’s get started….
For businesses scaling rapidly or managing complex cloud architectures, these inefficiencies can quickly escalate. Their expertise in optimizing EC2, S3, and Lambda confirms businesses particular expenses for the resources they indeed need, lowering costs while maximizing performance.
AWS Lambdas don’t let you do that. If you’re still using an Elastic Compute Cloud (EC2) Virtual Machine, enjoy this very useful tutorial on loadbalancing. That’s what I’m using AWS Application LoadBalancer (“ALB”) for, even though I have only a single instance at the moment so there’s no actual loadbalancing going on.
Basically you say “Get me an AWS EC instance with this base image” and “get me a lambda function” and “get me this API gateway with some special configuration”. Kubernetes does all the dirty details about machines, resilience, auto-scaling, load-balancing and so on. The client now does client side loadbalancing.
With serverless, you can lean on off-the-shelf cloud services resources for your application architecture, focus on business logic and application needs, while (mostly) ignoring infrastructure capacity and management. and patching, and scaling, and load-balancing, and orchestrating, and deploying, and… the list goes on!
The architecture of the solution is shown in the following diagram, showcasing the flow of data through the application. Behind the loadbalancer is a containerized Streamlit application running on Amazon Elastic Container Service (Amazon ECS). Solution overview The full code for this application is available on the GitHub repo.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content