This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
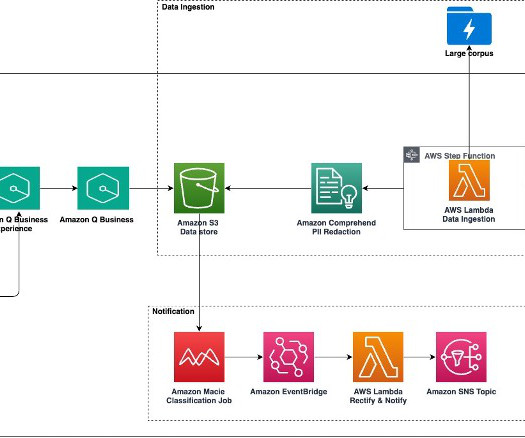
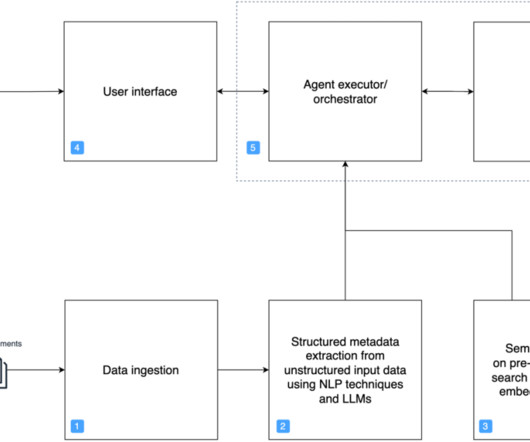
In this post, we propose an end-to-end solution using Amazon Q Business to simplify integration of enterprise knowledgebases at scale. Solution overview The following architecture diagram represents the high-level design of a solution proven effective in production environments for AWS Support Engineering.
In this post, we demonstrate how to create an automated email response solution using Amazon Bedrock and its features, including Amazon Bedrock Agents , Amazon Bedrock KnowledgeBases , and Amazon Bedrock Guardrails. Solution overview This section outlines the architecture designed for an email support system using generative AI.
By implementing this architectural pattern, organizations that use Google Workspace can empower their workforce to access groundbreaking AI solutions powered by Amazon Web Services (AWS) and make informed decisions without leaving their collaboration tool. This request contains the user’s message and relevant metadata.
Whether youre an experienced AWS developer or just getting started with cloud development, youll discover how to use AI-powered coding assistants to tackle common challenges such as complex service configurations, infrastructure as code (IaC) implementation, and knowledgebase integration.
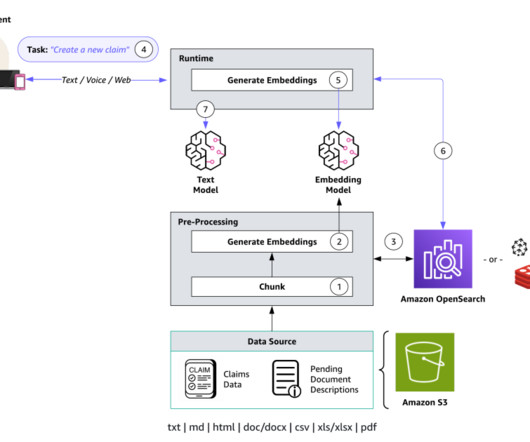
You can now use Agents for Amazon Bedrock and KnowledgeBases for Amazon Bedrock to configure specialized agents that seamlessly run actions based on natural language input and your organization’s data. The following diagram illustrates the solution architecture. The following are some example prompts: Create a new claim.
Building cloud infrastructure based on proven best practices promotes security, reliability and cost efficiency. To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This systematic approach leads to more reliable and standardized evaluations.
In November 2023, we announced KnowledgeBases for Amazon Bedrock as generally available. Knowledgebases allow Amazon Bedrock users to unlock the full potential of Retrieval Augmented Generation (RAG) by seamlessly integrating their company data into the language model’s generation process.
One way to enable more contextual conversations is by linking the chatbot to internal knowledgebases and information systems. Integrating proprietary enterprise data from internal knowledgebases enables chatbots to contextualize their responses to each user’s individual needs and interests.
Amazon Bedrock Agents enables this functionality by orchestrating foundation models (FMs) with data sources, applications, and user inputs to complete goal-oriented tasks through API integration and knowledgebase augmentation. In the first flow, a Lambda-based action is taken, and in the second, the agent uses an MCP server.
We have built a custom observability solution that Amazon Bedrock users can quickly implement using just a few key building blocks and existing logs using FMs, Amazon Bedrock KnowledgeBases , Amazon Bedrock Guardrails , and Amazon Bedrock Agents. versions, catering to different programming preferences.
Amazon Bedrock KnowledgeBases is a fully managed capability that helps you implement the entire RAG workflow—from ingestion to retrieval and prompt augmentation—without having to build custom integrations to data sources and manage data flows. Latest innovations in Amazon Bedrock KnowledgeBase provide a resolution to this issue.
The following diagram illustrates the conceptual architecture of an AI assistant with Amazon Bedrock IDE. Solution architecture The architecture in the preceding figure shows how Amazon Bedrock IDE orchestrates the data flow.
It integrates with existing applications and includes key Amazon Bedrock features like foundation models (FMs), prompts, knowledgebases, agents, flows, evaluation, and guardrails. Before we dive deep into the deployment of the AI agent, lets walk through the key steps of the architecture, as shown in the following diagram.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledgebase to provide personalized, context-aware responses tailored to your specific situation. These data sources provide contextual information and serve as a knowledgebase for the LLM.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Depending on the use case and data isolation requirements, tenants can have a pooled knowledgebase or a siloed one and implement item-level isolation or resource level isolation for the data respectively.
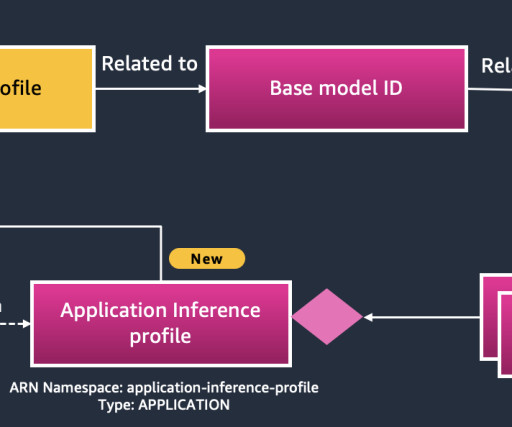
Although tagging is supported on a variety of Amazon Bedrock resources —including provisioned models, custom models, agents and agent aliases, model evaluations, prompts, prompt flows, knowledgebases, batch inference jobs, custom model jobs, and model duplication jobs—there was previously no capability for tagging on-demand foundation models.
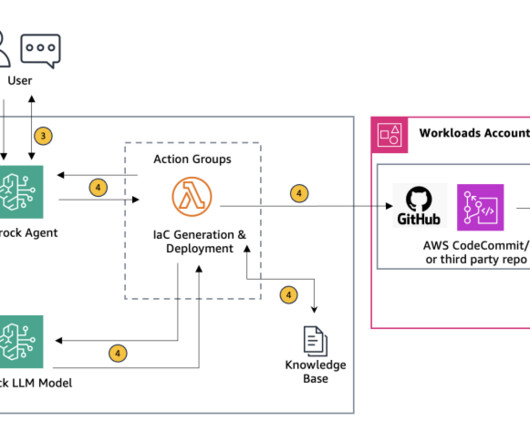
This solution shows how Amazon Bedrock agents can be configured to accept cloud architecture diagrams, automatically analyze them, and generate Terraform or AWS CloudFormation templates. Solution overview Before we explore the deployment process, let’s walk through the key steps of the architecture as illustrated in Figure 1.
It’s a fully serverless architecture that uses Amazon OpenSearch Serverless , which can run petabyte-scale workloads, without you having to manage the underlying infrastructure. The following diagram illustrates the solution architecture. This solution uses Amazon Bedrock LLMs to find answers to questions from your knowledgebase.
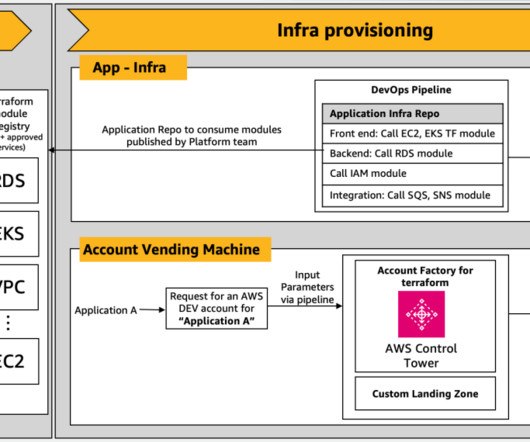
With Amazon Bedrock, teams can input high-level architectural descriptions and use generative AI to generate a baseline configuration of Terraform scripts. AWS Landing Zone architecture in the context of cloud migration AWS Landing Zone can help you set up a secure, multi-account AWS environment based on AWS best practices.
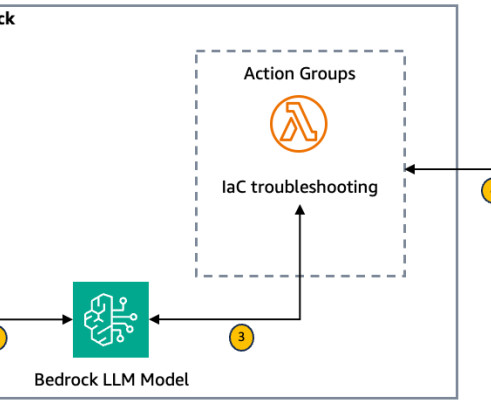
Solution overview Before we dive into the deployment process, lets walk through the key steps of the architecture as illustrated in the following figure. This function invokes another Lambda function (see the following Lambda function code ) which retrieves the latest error message from the specified Terraform Cloud workspace.
The assistant can filter out irrelevant events (based on your organization’s policies), recommend actions, create and manage issue tickets in integrated IT service management (ITSM) tools to track actions, and query knowledgebases for insights related to operational events. It has several key components.
It uses the provided conversation history, action groups, and knowledgebases to understand the context and determine the necessary tasks. This is based on the instructions that are interpreted by the assistant as per the system prompt and user’s input. Additionally, you can access device historical data or device metrics.
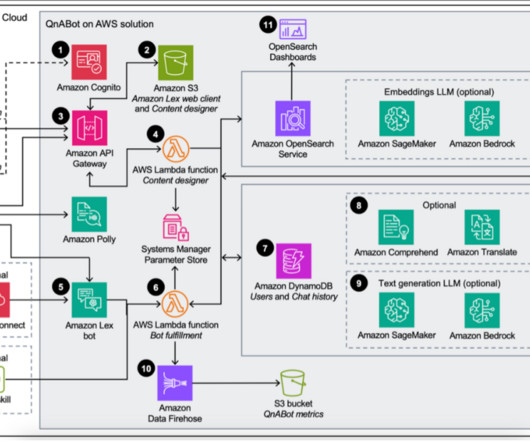
QnABot on AWS (an AWS Solution) now provides access to Amazon Bedrock foundational models (FMs) and KnowledgeBases for Amazon Bedrock , a fully managed end-to-end Retrieval Augmented Generation (RAG) workflow. The Content Designer AWS Lambda function saves the input in Amazon OpenSearch Service in a questions bank index.
Five years later, transformer architecture has evolved to create powerful models such as ChatGPT. ChatGPT was trained with 175 billion parameters; for comparison, GPT-2 was 1.5B (2019), Google’s LaMBDA was 137B (2021), and Google’s BERT was 0.3B (2018). GPT stands for generative pre-trained transformer.
You can now use Agents for Amazon Bedrock and KnowledgeBases for Amazon Bedrock to build specialized agents and AI-powered assistants that run actions based on natural language input prompts and your organization’s data. Both the action groups and knowledgebase are optional and not required for the agent itself.
By using Amazon Bedrock Agents , action groups , and Amazon Bedrock KnowledgeBases , we demonstrate how to build a migration assistant application that rapidly generates migration plans, R-dispositions, and cost estimates for applications migrating to AWS.
Moreover, Amazon Bedrock offers integration with other AWS services like Amazon SageMaker , which streamlines the deployment process, and its scalable architecture makes sure the solution can adapt to increasing call volumes effortlessly. This is powered by the web app portion of the architecture diagram (provided in the next section).
Built using Amazon Bedrock KnowledgeBases , Amazon Lex , and Amazon Connect , with WhatsApp as the channel, our solution provides users with a familiar and convenient interface. With the ability to continuously update and add to the knowledgebase, AI applications stay current with the latest information.
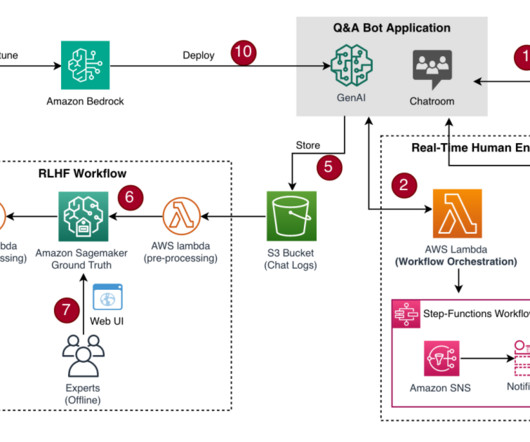
The entire conversation in this use case, starting with generative AI and then bringing in human agents who take over, is logged so that the interaction can be used as part of the knowledgebase. We also have another expert group providing feedback using Amazon SageMaker GroundTruth on completion quality for the RLHF based training.
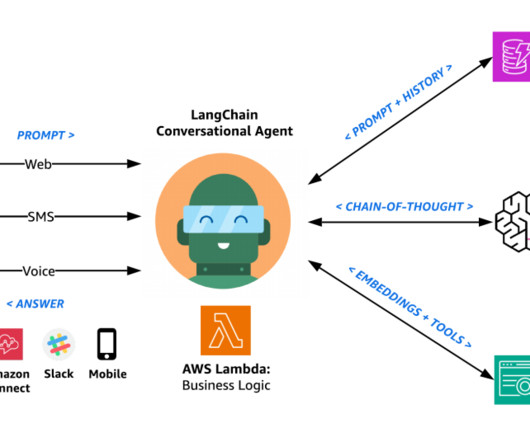
Solution architecture The following diagram illustrates the solution architecture. Diagram 1: Solution Architecture Overview The agent’s response workflow includes the following steps: Users perform natural language dialog with the agent through their choice of web, SMS, or voice channels.
In this post, we describe the development journey of the generative AI companion for Mozart, the data, the architecture, and the evaluation of the pipeline. The following diagram illustrates the solution architecture. You can create a decoupled architecture with reusable components. Connect with him on LinkedIn.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock KnowledgeBases. With just a few configuration steps, you can dramatically expand your chatbot’s knowledgebase and capabilities, all while maintaining a streamlined UI.
To create AI assistants that are capable of having discussions grounded in specialized enterprise knowledge, we need to connect these powerful but generic LLMs to internal knowledgebases of documents. Then we introduce you to a more versatile architecture that overcomes these limitations.
They use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledgebases using Retrieval Augmented Generation (RAG) to provide a final response to the end user. We use Amazon Bedrock Agents with two knowledgebases for this assistant.
These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned large language models (LLMs), or a combination of these techniques. Generative AI question-answering applications are pushing the boundaries of enterprise productivity.
By harnessing the power of generative AI and Amazon Web Services (AWS) services Amazon Bedrock , Amazon Kendra , and Amazon Lex , this solution provides a sample architecture to build an intelligent Slack chat assistant that can streamline information access, enhance user experiences, and drive productivity and efficiency within organizations.
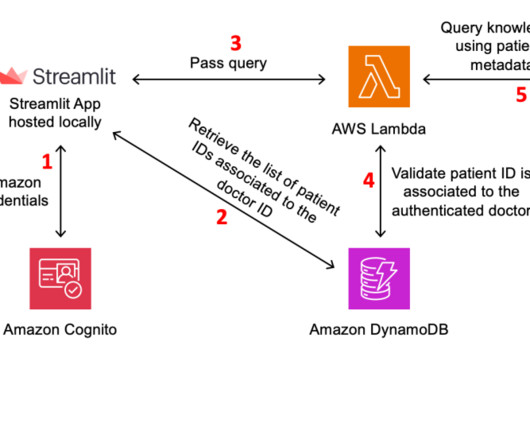
Architecture The solution uses Amazon API Gateway , AWS Lambda , Amazon RDS, Amazon Bedrock, and Anthropic Claude 3 Sonnet on Amazon Bedrock to implement the backend of the application. The following diagram illustrates the solution architecture. User authentication and authorization is done using Amazon Cognito.
For a generative AI powered Live Meeting Assistant that creates post call summaries, but also provides live transcripts, translations, and contextual assistance based on your own company knowledgebase, see our new LMA solution. Transcripts are then stored in the project’s S3 bucket under /transcriptions/TranscribeOutput/.
Our internal AI sales assistant, powered by Amazon Q Business , will be available across every modality and seamlessly integrate with systems such as internal knowledgebases, customer relationship management (CRM), and more. We carefully choose models based on their specific capabilities and the requirements of each summary section.
Mediasearch Q Business supercharges the way you consume media files by using them as part of the knowledgebase used by Amazon Q Business to generate reliable answers to user questions. Mediasearch Q Business builds on the Mediasearch solution powered by Amazon Kendra and enhances the search experience using Amazon Q Business.
RAG allows models to tap into vast knowledgebases and deliver human-like dialogue for applications like chatbots and enterprise search assistants. Solution overview In this post, we demonstrate how to create a RAG-based application using LlamaIndex and an LLM. Download press releases to use as our external knowledgebase.
This could be Amazon Elastic Compute Cloud (Amazon EC2), AWS Lambda , AWS SDK , Amazon SageMaker notebooks, or your workstation if you are doing a quick proof of concept. The following diagram illustrates the solution architecture. For the purpose of this post, this code is running on a t3a.micro EC2 instance with Amazon Linux 2023.
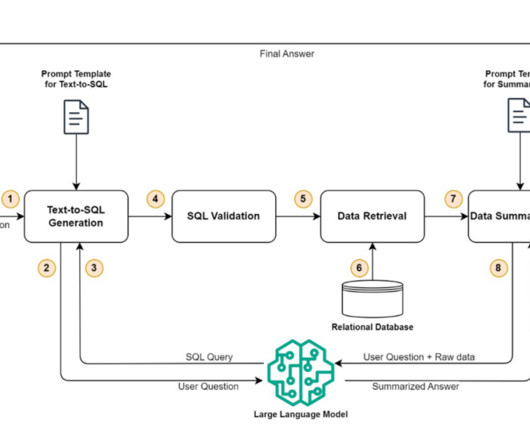
We use AWS Lambda as our orchestration function responsible for interacting with various data sources, LLMs and error correction based on the user query. The following figure illustrates this architecture. The following figures shows the step-by-step procedure of how a query is processed for the text-to-SQL pipeline.
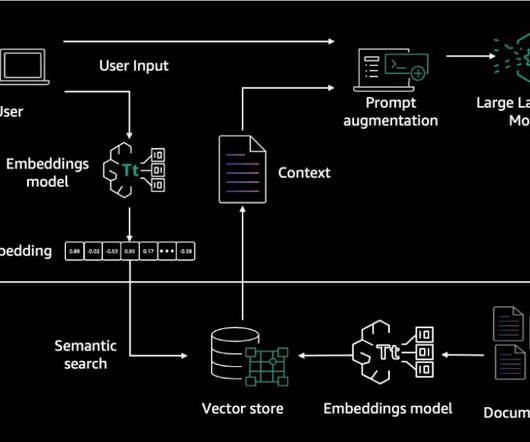
Llama 3 uses a decoder-only transformer architecture and new tokenizer that provides improved model performance with 128K size. RAG overview Retrieval-Augmented Generation (RAG) is a technique that enables the integration of external knowledge sources with FM. RAG involves three main steps: retrieval, augmentation, and generation.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content