This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post presents a solution where you can upload a recording of your meeting (a feature available in most modern digital communication services such as Amazon Chime ) to a centralized video insights and summarization engine. This post provides guidance on how you can create a video insights and summarization engine using AWS AI/ML services.
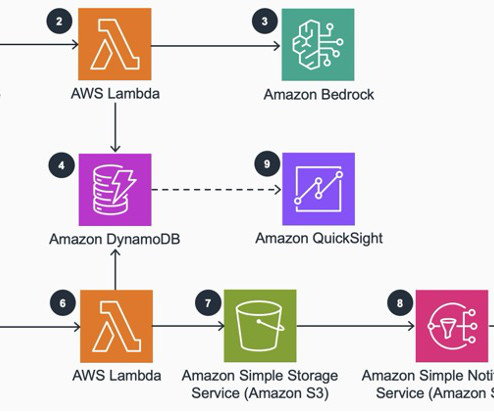
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
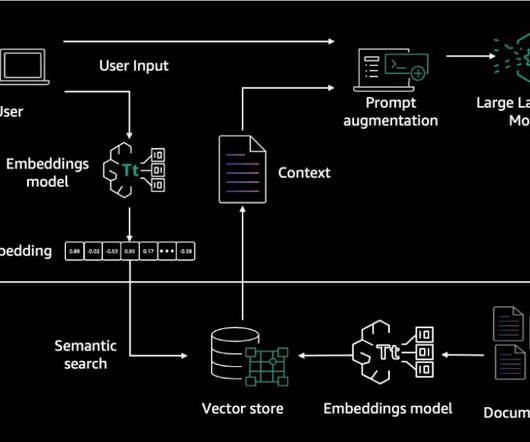
This architecture workflow includes the following steps: A user submits a question through a web or mobile application. The architecture of this system is illustrated in the following figure. These embeddings are then saved as a reference index inside an in-memory FAISS vector store, which is deployed as a Lambda layer.
Accelerate building on AWS What if your AI assistant could instantly access deep AWS knowledge, understanding every AWS service, best practice, and architectural pattern? Lets create an architecture that uses Amazon Bedrock Agents with a custom action group to call your internal API.
AWS Lambda offers a relatively thin service with a rich set of ancillary configuration options, making it possible to implement easily scalable and maintainable applications leveraging these services.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. To handle large volumes, the data is split into smaller chunks to mitigate Lambda function overload.
This post will discuss agentic AI driven architecture and ways of implementing. Agentic AI architecture Agentic AI architecture is a shift in process automation through autonomous agents towards the capabilities of AI, with the purpose of imitating cognitive abilities and enhancing the actions of traditional autonomous agents.
The following is a review of the book Fundamentals of Data Engineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a data engineer.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. The solution incorporates the following key features: Using a Retrieval Augmented Generation (RAG) architecture, the system generates a context-aware detailed assessment.
Solution overview This section outlines the architecture designed for an email support system using generative AI. AI-powered email processing engine – Central to the solution, this engine uses AI to analyze and process emails. When a customer sends an email, WorkMail receives it and invokes the next component in the workflow.
Using a client-server architecture, MCP enables developers to expose their data through lightweight MCP servers while building AI applications as MCP clients that connect to these servers. In the first flow, a Lambda-based action is taken, and in the second, the agent uses an MCP server.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures. As a result, building such a solution is often a significant undertaking for IT teams.
Fargate vs. Lambda has recently been a trending topic in the serverless space. Fargate and Lambda are two popular serverless computing options available within the AWS ecosystem. This blog aims to take a deeper look into the Fargate vs. This blog aims to take a deeper look into the Fargate vs. Lambda battle.
The architecture seamlessly integrates multiple AWS services with Amazon Bedrock, allowing for efficient data extraction and comparison. The following diagram illustrates the solution architecture. The text summarization Lambda function is invoked by this new queue containing the extracted text.
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. The following diagram illustrates the architecture of the application.
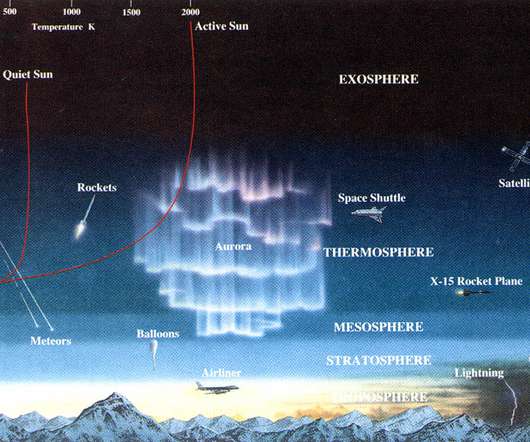
Audio-to-text transcription The recorded audio files are securely transmitted to a speech-to-text engine, which converts the spoken words into text format. Solution overview The following diagram illustrates the solution architecture. Copying these sample files will trigger an S3 event invoking the AWS Lambda function audio-to-text.
Not only did TrueCar need to move their domain DNS entries, they also needed to revamp their entire architecture, software, and operational practices. To complicate issues, the legacy codebase and architecture had to remain in place while TrueCar built out a new platform for the transition. Lambda@Edge NodeJS goodness.
Agents for Amazon Bedrock automates the prompt engineering and orchestration of user-requested tasks. This solution shows how Amazon Bedrock agents can be configured to accept cloud architecture diagrams, automatically analyze them, and generate Terraform or AWS CloudFormation templates.
Solution overview Before we dive into the deployment process, lets walk through the key steps of the architecture as illustrated in the following figure. This function invokes another Lambda function (see the following Lambda function code ) which retrieves the latest error message from the specified Terraform Cloud workspace.
The CloudFormation template provisions resources such as Amazon Data Firehose delivery streams, AWS Lambda functions, Amazon S3 buckets, and AWS Glue crawlers and databases. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. versions, catering to different programming preferences.
It enables you to privately customize the FM of your choice with your data using techniques such as fine-tuning, prompt engineering, and retrieval augmented generation (RAG) and build agents that run tasks using your enterprise systems and data sources while adhering to security and privacy requirements.
Traditionally, cloud engineers learning IaC would manually sift through documentation and best practices to write compliant IaC scripts. With Amazon Bedrock, teams can input high-level architectural descriptions and use generative AI to generate a baseline configuration of Terraform scripts.
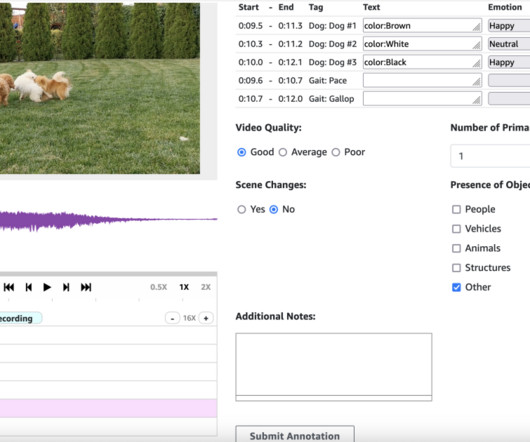
The following diagram illustrates the solution architecture. Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow. The pre-annotation Lambda function can process the input manifest file before data is presented to annotators, enabling any necessary formatting or modifications.
Edge Delta aims its tools at DevOps, site-reliability engineers and security teams — groups that focus on analyzing logs, metrics, events, traces and other large data troves, often in real time, to do their work.
Our proposed architecture provides a scalable and customizable solution for online LLM monitoring, enabling teams to tailor your monitoring solution to your specific use cases and requirements. A modular architecture, where each module can intake model inference data and produce its own metrics, is necessary.
In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda. Solution overview The following diagram illustrates our solution architecture. This can be done with a Lambda layer or by using a specific AMI with the required libraries. awscli>=1.29.57
Most organisations go through an architecture modernisation effort at some point as their systems drift into a state of intolerable maintenance costs and they diverge too far from modern technological advances. What architecture will be optimal for enabling that business vision? How are we going to deliver the new architecture?
My company, like most, spent far more money on engineer salaries than the cloud itself. This isn't exactly a new idea—Heroku launched in 2007, and AWS Lambda in 2014. Most engineers will never interact directly with cloud vendors, but through services on top of those. I'm not so sure? Predictions.
In this post, we describe how CBRE partnered with AWS Prototyping to develop a custom query environment allowing natural language query (NLQ) prompts by using Amazon Bedrock, AWS Lambda , Amazon Relational Database Service (Amazon RDS), and Amazon OpenSearch Service. A Lambda function with business logic invokes the primary Lambda function.
As an engineer, why would I? I can spin up a fleet of instances, a NoSQL database capable of millions of transactions per second, or even a flock of lambdas with instant scaling, as I please. I never used to care about the cost of the systems I built.
In this post, we describe the development journey of the generative AI companion for Mozart, the data, the architecture, and the evaluation of the pipeline. The following diagram illustrates the solution architecture. You can create a decoupled architecture with reusable components.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Finally I mention Lambda’s limited, but not trivial, vertical scaling capability.
Putting data to work to improve health outcomes “Predicting IDH in hemodialysis patients is challenging due to the numerous patient- and treatment-related factors that affect IDH risk,” says Pete Waguespack, director of data and analytics architecture and engineering for Fresenius Medical Care North America.
Lately, I’ve seen some talk about an architectural pattern that I believe will become prevalent in the near future. It will scale just fine… unless you hit your account-wide Lambda limit. 6.10, which is approaching EOL for AWS Lambda? What Skills Do Engineers Need For This New Technique? What if that’s Node.js
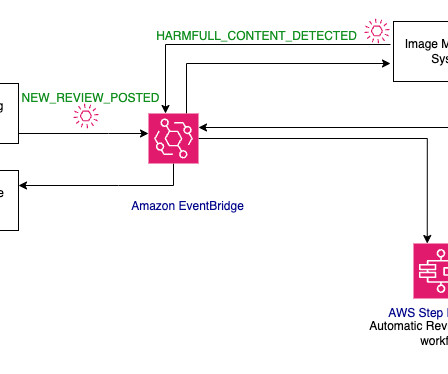
You can apply robust prompt engineering techniques to instruct the model to perform your specified actions to minimize any bias or hallucinations in the response, and have the output in the specific format required. The following reference architecture illustrates what an automated review analysis solution could look like.
The process of designing and refining prompts to get specific responses from these models is called prompt engineering. The application uses event-driven architecture (EDA), a powerful software design pattern that you can use to build decoupled systems by communicating through events. Prompt engineering is an iterative process.
According to the RightScale 2018 State of the Cloud report, serverless architecture penetration rate increased to 75 percent. Aware of what serverless means, you probably know that the market of cloudless architecture providers is no longer limited to major vendors such as AWS Lambda or Azure Functions.
Conversational artificial intelligence (AI) assistants are engineered to provide precise, real-time responses through intelligent routing of queries to the most suitable AI functions. For direct device actions like start, stop, or reboot, we use the action-on-device action group, which invokes a Lambda function.
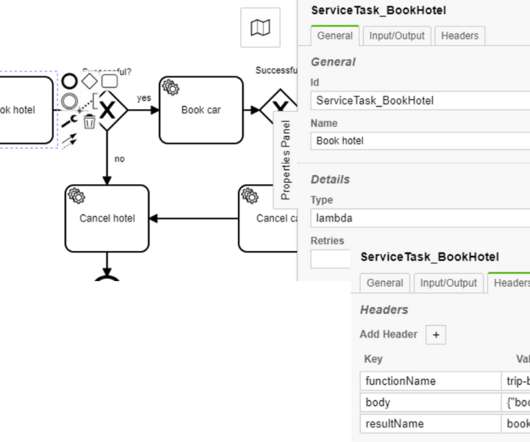
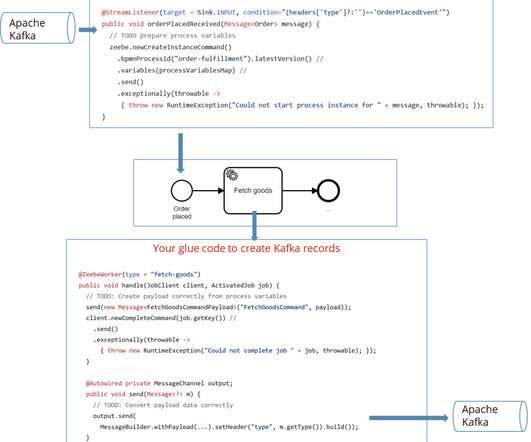
Powerful Serverless Function Orchestration using BPMN and Cloud-Native Workflow Technology Assume you want to coordinate multiple Lambdas to achieve a bigger goal. and how you can use BPMN and Camunda Cloud to orchestrate these three AWS Lambdas and provide an additional trip booking Lambda. Why Orchestration?
Camunda Cloud Architecture Blog Post Series?—?Part One of your first tasks would be to sketch the basic architecture of your solution, and this blog post will guide you through some important early questions such as how to connect the workflow engine Zeebe with your application or with remote systems?
Cloud-native application development in AWS often requires complex, layered architecture with synchronous and asynchronous interactions between multiple components, e.g., API Gateway, Microservices, Serverless Functions, and system of record integration.
Cold Starts This is Part 8 of Learning Lambda, a tutorial series about engineering using AWS Lambda. In this installment of Learning Lambda I discuss Cold Starts. In this installment of Learning Lambda I discuss Cold Starts. Way back in Part 3 I talked about the lifecycle of a Lambda function.
In this post, I describe how to send OpenTelemetry (OTel) data from an AWS Lambda instance to Honeycomb. I will be showing these steps using a Lambda written in Python and created and deployed using AWS Serverless Application Model (AWS SAM). Add OTel and Honeycomb environment variables to your template configuration for your Lambda.
The popular architecture pattern of Retrieval Augmented Generation (RAG) is often used to augment user query context and responses. Internally, Amazon Bedrock uses embeddings stored in a vector database to augment user query context at runtime and enable a managed RAG architecture solution.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content