This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
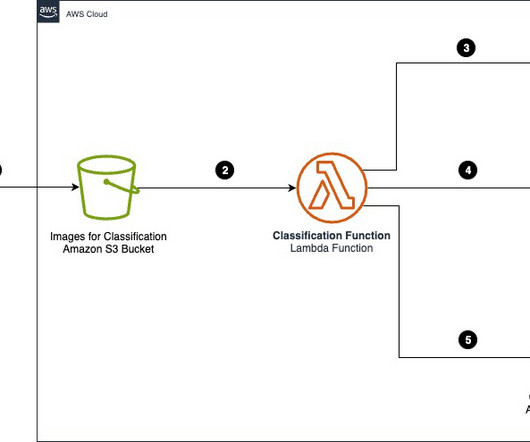
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Solution overview The solution presented in this post uses batch inference in Amazon Bedrock to process many requests efficiently using the following solution architecture.
GenAI can also harness vast datasets, insights, and documentation to provide guidance during the migration process. Alignment: Is the solution customisable for -specific architectures, and therefore able to unlock additional, unique efficiency, accuracy, and scalability improvements?
AI practitioners and industry leaders discussed these trends, shared best practices, and provided real-world use cases during EXLs recent virtual event, AI in Action: Driving the Shift to Scalable AI. And its modular architecture distributes tasks across multiple agents in parallel, increasing the speed and scalability of migrations.
Intelligent document processing (IDP) is changing the dynamic of a longstanding enterprise content management problem: dealing with unstructured content. The ability to effectively wrangle all that data can have a profound, positive impact on numerous document-intensive processes across enterprises. Not so with unstructured content.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. The solution incorporates the following key features: Using a Retrieval Augmented Generation (RAG) architecture, the system generates a context-aware detailed assessment.
Regulators today are no longer satisfied with frameworks, documentation, and audit validation alone; they want tangible evidence, including end-to-end testing, as well as compliance program management that is baked into day-to-day operating processes. 2025 Banking Regulatory Outlook, Deloitte The stakes are clear.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications. billion in 2025 to USD 66.68
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider. The biggest challenge is data.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
To address this, customers often begin by enhancing generative AI accuracy through vector-based retrieval systems and the Retrieval Augmented Generation (RAG) architectural pattern, which integrates dense embeddings to ground AI outputs in relevant context. Lettria provides an accessible way to integrate GraphRAG into your applications.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
Private cloud architecture is an increasingly popular approach to cloud computing that offers organizations greater control, security, and customization over their cloud infrastructure. What is Private Cloud Architecture? Why is Private Cloud Architecture important for Businesses?
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider. The biggest challenge is data.
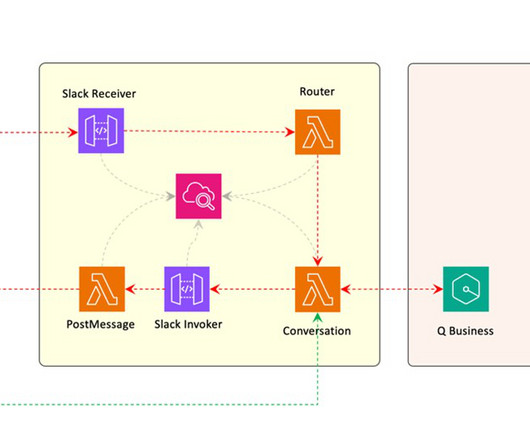
With Amazon Q Business , Hearst’s CCoE team built a solution to scale cloud best practices by providing employees across multiple business units self-service access to a centralized collection of documents and information. User authorization for documents within the individual S3 buckets were controlled through access control lists (ACLs).
A key part of the submission process is authoring regulatory documents like the Common Technical Document (CTD), a comprehensive standard formatted document for submitting applications, amendments, supplements, and reports to the FDA. The tedious process of compiling hundreds of documents is also prone to errors.
Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
Assessment : Deciphers and documents the business logic, dependencies and functionality of legacy code. Greater integration and scalability: This modular architecture distributes tasks across multiple agents working in parallel, so Code Harbor can perform more work in less time.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. 8B ) and DeepSeek-R1-Distill-Llama-70B (from base model Llama-3.3-70B-Instruct
This is where intelligent document processing (IDP), coupled with the power of generative AI , emerges as a game-changing solution. The process involves the collection and analysis of extensive documentation, including self-evaluation reports (SERs), supporting evidence, and various media formats from the institutions being reviewed.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. Choose Next.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
We walk through the key components and services needed to build the end-to-end architecture, offering example code snippets and explanations for each critical element that help achieve the core functionality. Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability.
This AI-driven approach is particularly valuable in cloud development, where developers need to orchestrate multiple services while maintaining security, scalability, and cost-efficiency. Skip hours of documentation research and immediately access ready-to-use patterns for complex services such as Amazon Bedrock Knowledge Bases.
Koletzki would use the move to upgrade the IT environment from a small data room to something more scalable. He knew that scalability was a big win for a company in aggressive growth mode, but he just needed to be persuaded that the platforms were more robust, and the financials made sense. I just subscribed to their service.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. However, to unlock the long-term success and viability of these AI-powered solutions, it is crucial to align them with well-established architectural principles.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. In the following sections, we explain how to deploy this architecture.
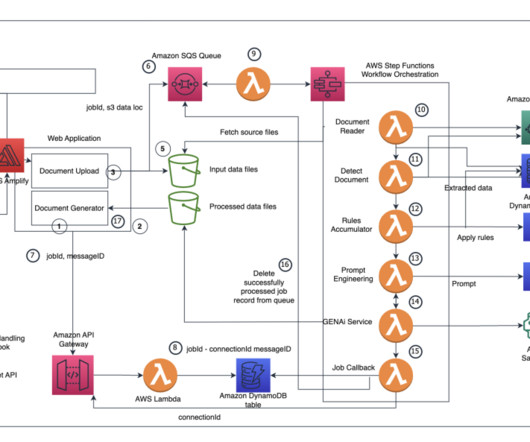
Whether processing invoices, updating customer records, or managing human resource (HR) documents, these workflows often require employees to manually transfer information between different systems a process thats time-consuming, error-prone, and difficult to scale. The following diagram illustrates the solution architecture.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
These specifications make up the API architecture. Over time, different API architectural styles have been released. A pull of choices raises endless debates as to which architectural style is best. RPC’s tight coupling makes scalability requirements and loosely coupled teams hard to achieve. Tedious message updating.
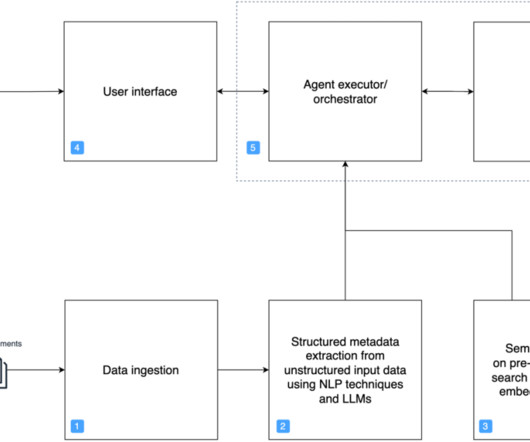
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. Then we introduce you to a more versatile architecture that overcomes these limitations.
Every company needs documents for its processes, information, contracts, proposals, quotes, reports, non-disclosure agreements, service agreements, and for various other purposes. Document creation and management is a crucial part of their operations. What is Industries Document Generation? How to generate documents?
Initially, our industry relied on monolithic architectures, where the entire application was a single, simple, cohesive unit. Ever increasing complexity To overcome these limitations, we transitioned to Service-Oriented Architecture (SOA). This could also mean that the samples in this document are outdated and no longer work.
The inner transformer architecture comprises a bunch of neural networks in the form of an encoder and a decoder. USE CASES: To develop custom AI workflow and transformer architecture-based AI agents. Scalability Thanks to their resilient architecture, LLMs can handle multiple documents simultaneously.
However, Anthropics documentation is full of warnings about serious security vulnerabilities that remain to be solved. Interest in Data Lake architectures rose 59%, while the much older Data Warehouse held steady, with a 0.3% Usage of material about Software Architecture rose 5.5% Finally, ETL grew 102%.
However, these tools may not be suitable for more complex data or situations requiring scalability and robust business logic. In short, Booster is a Low-Code TypeScript framework that allows you to quickly and easily create a backend application in the cloud that is highly efficient, scalable, and reliable. WTF is Booster?
In this blog post, we’ll dive deeper into the concept of multi-tenancy and explore how Django-multitenant can help you build scalable, secure, and maintainable multi-tenant applications on top of PostgreSQL and the Citus database extension. Introduced ReadTheDocs documentation. What is multi-tenancy?
For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository. Although the implementation is straightforward, following best practices is crucial for the scalability, security, and maintainability of your observability infrastructure.
This is where TOGAF (the Open Group Architecture Framework) comes into play. It is an enterprise architecture framework that offers a systematic and comprehensive approach to achieving business transformation and sustainable success. It helps architects organize and document the architecture effectively.
Scalability and performance – The EMR Serverless integration automatically scales the compute resources up or down based on your workload’s demands, making sure you always have the necessary processing power to handle your big data tasks. Each document is split page by page, with each page referencing the global in-memory PDFs.
You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures. A centralized service that exposes APIs for common prompt-chaining architectures to your tenants can accelerate development. As a result, building such a solution is often a significant undertaking for IT teams.
To accelerate iteration and innovation in this field, sufficient computing resources and a scalable platform are essential. In this post, we share an ML infrastructure architecture that uses SageMaker HyperPod to support research team innovation in video generation.
Example: A company that values open, verbal communication might undervalue a candidate who communicates effectively through written documentation or quieter, one-on-one interactions, missing out on a valuable contributor. Example: Ask a group of candidates to design an architecture for a scalable web application.
It is all about the accelerator’s architectural design plus optimization of the AI ecosystem that sits on top of the accelerator. When it comes to AI acceleration in production enterprise workloads, a fit-for-purpose architecture matters.
These cover the most widely used transformer architectures such as BERT, RoBERTa, DeBERTa, ALBERT, DistilBERT, XLM-RoBERTa, and CamamBERT. These applications enable companies, for example, to ask a chatbot about their private documents, emails, or other confidential content. “We are thrilled to present Spark NLP 5.0,
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content