This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With serverless components, there is no need to manage infrastructure, and the inbuilt tracing, logging, monitoring and debugging make it easy to run these workloads in production and maintain service levels. Financial services unique challenges However, it is important to understand that serverlessarchitecture is not a silver bullet.
How does Serverless help? How about security When the device sends its data, it also contains the identifier of the device itself. Conclusion Real-world examples help illustrate our options for serverless technology. Based on those questions, you might pivot your solution’s architecture.
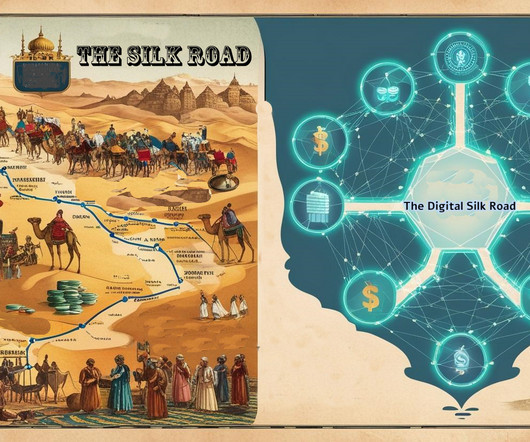
However, trade along the Silk Road was not just a matter of distance; it was shaped by numerous constraints much like todays data movement in cloud environments. Merchants had to navigate complex toll systems imposed by regional rulers, much as cloud providers impose egress fees that make it costly to move data between platforms.
In 2025, data management is no longer a backend operation. The evolution of cloud-first strategies, real-time integration and AI-driven automation has set a new benchmark for data systems and heightened concerns over data privacy, regulatory compliance and ethical AI governance demand advanced solutions that are both robust and adaptive.
Speaker: Ahmad Jubran, Cloud Product Innovation Consultant
Many do this by simply replicating their current architectures in the cloud. Those previous architectures, which were optimized for transactional systems, aren't well-suited for the new age of AI. In this webinar, you will learn how to: Take advantage of serverless application architecture. And much more!
As enterprises increasingly embrace serverless computing to build event-driven, scalable applications, the need for robust architectural patterns and operational best practices has become paramount. Each function should handle a specific task or domain, such as user authentication, data processing, or notification services.
Serverless and function as a service (FaaS) are hot terms in the software architecture world these days. All three major cloud service providers, or CSPs (Amazon, Microsoft, and Google), are heavily invested in serverless.
This article describes the implementation of RESTful API on AWS serverlessarchitecture. It provides a detailed overview of the architecture, data flow, and AWS services that can be used. This article also describes the benefits of the serverlessarchitecture over the traditional approach.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. The solution incorporates the following key features: Using a Retrieval Augmented Generation (RAG) architecture, the system generates a context-aware detailed assessment.
The good news is that deploying these applications on a serverlessarchitecture can make it easier to protect them. Cloud-native architecture has opened up new avenues for developers, bringing individual components out of monolithic server configurations and making them readily available as consumable services. Here’s why.
In the context of generative AI , significant progress has been made in developing multimodal embedding models that can embed various data modalities—such as text, image, video, and audio data—into a shared vector space. An Amazon OpenSearch Serverless collection. The GitHub repo cloned to the Amazon SageMaker Studio instance.
Amazon Bedrock Custom Model Import enables the import and use of your customized models alongside existing FMs through a single serverless, unified API. This serverless approach eliminates the need for infrastructure management while providing enterprise-grade security and scalability.
This blog post discusses an end-to-end ML pipeline on AWS SageMaker that leverages serverless computing, event-trigger-based data processing, and external API integrations. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
Amazon Web Services (AWS) provides an expansive suite of tools to help developers build and manage serverless applications with ease. In this article, we delve into serverless AI/ML on AWS, exploring best practices, implementation strategies, and an example to illustrate these concepts in action.
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional data integration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
As data volumes continue to grow, employees and customers are increasingly challenged to find the information they want. [ii] Flexible integration with multiple data types and sources Enterprise data is spread across a multitude of databases, internal applications, and software-as-a-service.
Model Context Protocol (MCP) aims to standardize how these channels, agents, tools, and customer data can be used by agents, as shown in the following figure. We will deep dive into the MCP architecture later in this post.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. These potential vulnerabilities could be exploited by adversaries through various threat vectors.
Architecting a multi-tenant generative AI environment on AWS A multi-tenant, generative AI solution for your enterprise needs to address the unique requirements of generative AI workloads and responsible AI governance while maintaining adherence to corporate policies, tenant and data isolation, access management, and cost control.
Leveraging Serverless and Generative AI for Image Captioning on GCP In today’s age of abundant data, especially visual data, it’s imperative to understand and categorize images efficiently. Cloud Storage Bucket: GCP’s unified object storage, allowing worldwide storage and retrieval of any amount of data.
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. In the following sections, we explain how to deploy this architecture.
Why I migrated my dynamic sites to a serverlessarchitecture. Moriel is a physicist turned software engineer turned systems architect, currently working on modernizing Wikipedia’s architecture. Like most web developers these days, I’ve heard of serverless applications and Jamstack for a while.
Here's a theory I have about cloud vendors (AWS, Azure, GCP): Cloud vendors 1 will increasingly focus on the lowest layers in the stack: basically leasing capacity in their data centers through an API. Redshift is a data warehouse (aka OLAP database) offered by AWS. Other pure-software providers will build all the stuff on top of it.
Data Summit 2025 is just around the corner, and were excited to connect, learn, and share ideas with fellow leaders in the data and AI space. As the pace of innovation accelerates, events like this offer a unique opportunity to engage with peers, discover groundbreaking solutions, and discuss the future of data-driven transformation.
PlanetScale , the serverless database company founded by the co-creators of the Vitess opensource project that powers YouTube, today announced that it has raised a $50 million Series C funding round led by Kleiner Perkins. ’ I think serverless is picking that up and it’s accelerating. .’
With the growth of the application modernization demands, monolithic applications were refactored to cloud-native microservices and serverless functions with lighter, faster, and smaller application portfolios for the past years.
However, as exciting as these advancements are, data scientists often face challenges when it comes to developing UIs and to prototyping and interacting with their business users. Streamlit allows data scientists to create interactive web applications using Python, using their existing skills and knowledge.
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for big data workloads has traditionally been a significant challenge, often requiring specialized expertise.
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies.
Create business intelligence (BI) dashboards for visual representation and analysis of event data. For instance, programmatic rules for event attribute-based noise filtering lack flexibility when faced with organizational changes, expansion of the service footprint, or new data source formats, leading growing complexity.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure.
Archival data in research institutions and national laboratories represents a vast repository of historical knowledge, yet much of it remains inaccessible due to factors like limited metadata and inconsistent labeling. The following diagram illustrates the solution architecture. Click here to open the AWS console and follow along.
We explain the end-to-end solution workflow, the prompts needed to produce the transcript and perform security analysis, and provide a deployable solution architecture. We must also account for limitations in the data that we ask Anthropics Claude to analyze. Highlight any actions taken that dont appear to be part of the runbook.
Ethan Batraski is a partner at Venrock and focuses on data infrastructure, open source and developer tools. Thanks to the cloud, the amount of data being generated and stored has exploded in scale and volume. As a result, enterprises, on average, store data across seven or more different databases.
Reduced time and effort in testing and deploying AI workflows with SDK APIs and serverless infrastructure. We can also quickly integrate flows with our applications using the SDK APIs for serverless flow execution — without wasting time in deployment and infrastructure management. Publish a working version of your guardrail.
According to the Unit 42 Cloud Threat Report : The rate of cloud migration shows no sign of slowing down—from $370 billion in 2021, with predictions to reach $830 billion in 2025—with many cloud-native applications and architectures already having had time to mature. Therefore, it'll be easier. It's definitely a misconception.
million terabytes of data will be generated by humans over the web and across devices. That’s just one of the many ways to define the uncontrollable volume of data and the challenge it poses for enterprises if they don’t adhere to advanced integration tech. As well as why data in silos is a threat that demands a separate discussion.
Infrastructure as code (IaC) has been gaining wider adoption among DevOps teams in recent years, but the complexities of data center configuration and management continue to create problems — and opportunities. IaC can be used for any type of cloud workload or architecture, but it is a necessity for anyone building on the modern cloud.
Each distinct task type will likely require a separate LLM, which might also be fine-tuned with custom data. The Pro tier, however, would require a highly customized LLM that has been trained on specific data and terminology, enabling it to assist with intricate tasks like drafting complex legal documents. 70B and 8B.
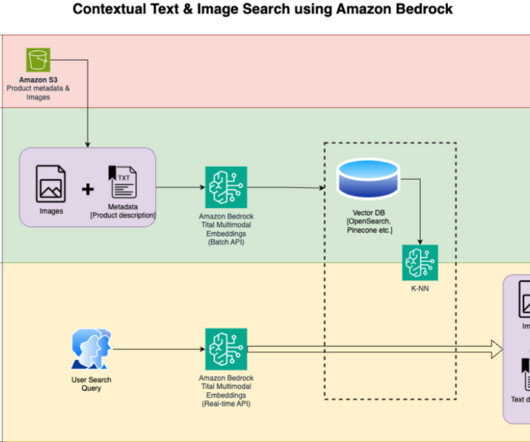
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model , available in Amazon Bedrock , with Amazon OpenSearch Serverless. The solution design consists of two parts: data indexing and contextual search. Review and prepare the dataset.
I summarized my key takeaways that can help you improve your serverlessarchitectures. From Lambda-lith to Step Function A common anti-pattern in serverlessarchitecture is creating a “Lambda-lith” – a monolithic Lambda function that handles too many responsibilities. With expressions like $.account.order.product.price.sum()
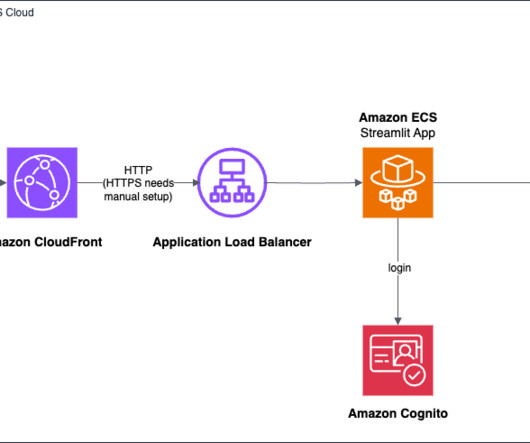
However, customer interaction data such as call center recordings, chat messages, and emails are highly unstructured and require advanced processing techniques in order to accurately and automatically extract insights. MaestroQA integrated Amazon Bedrock into their existing architecture using Amazon Elastic Container Service (Amazon ECS).
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. This feature allows you to separate data into logical partitions, making it easier to analyze and process data later.
The financial service (FinServ) industry has unique generative AI requirements related to domain-specific data, data security, regulatory controls, and industry compliance standards. Data security – Ensuring the security of inference payload data is paramount.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content