This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. This request contains the user’s message and relevant metadata.
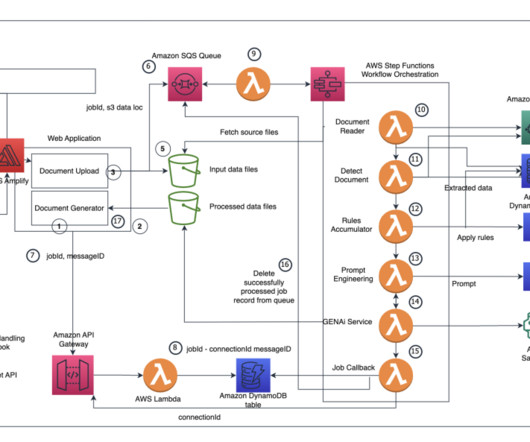
Batch inference in Amazon Bedrock efficiently processes large volumes of data using foundation models (FMs) when real-time results aren’t necessary. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB.
Each distinct task type will likely require a separate LLM, which might also be fine-tuned with custom data. The Pro tier, however, would require a highly customized LLM that has been trained on specific data and terminology, enabling it to assist with intricate tasks like drafting complex legal documents. 70B and 8B.
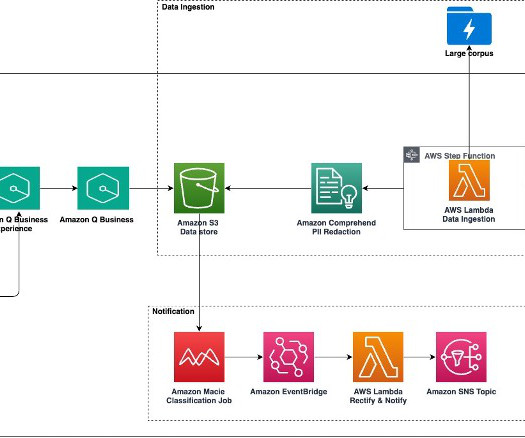
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Here you also have the data sources, processing pipelines, vector stores, and data governance mechanisms that allow tenants to securely discover, access, andthe data they need for their specific use case.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. The solution incorporates the following key features: Using a Retrieval Augmented Generation (RAG) architecture, the system generates a context-aware detailed assessment.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure.
Given the value of data today, organizations across various industries are working with vast amounts of data across multiple formats. The primary purpose of this proof of concept was to test and validate the proposed technologies, demonstrating their viability and potential for streamlining BQAs reporting and data management processes.
This post will discuss agentic AI driven architecture and ways of implementing. These AI agents have demonstrated remarkable versatility, being able to perform tasks ranging from creative writing and code generation to data analysis and decision support.
Model Context Protocol (MCP) aims to standardize how these channels, agents, tools, and customer data can be used by agents, as shown in the following figure. We will deep dive into the MCP architecture later in this post.
The following diagram illustrates the solution architecture on AWS. Semantic word associations with API Gateway and Lambda While the initial word list generated by Amazon Rekognition provides a solid starting point, the user might be seeking a more specific or related word.
Architecture Overview The accompanying diagram visually represents our infrastructure’s architecture, highlighting the relationships between key components. Data plane availability design is 99.995%. Which means that the data plane can be down for 26 minutes per year or 2 minutes per month.
Model Context Protocol (MCP) is a standardized open protocol that enables seamless interaction between large language models (LLMs), data sources, and tools. Accelerate building on AWS What if your AI assistant could instantly access deep AWS knowledge, understanding every AWS service, best practice, and architectural pattern?
Amazon Bedrock Agents enables this functionality by orchestrating foundation models (FMs) with data sources, applications, and user inputs to complete goal-oriented tasks through API integration and knowledge base augmentation. Local data sources : Your databases, local data sources, and services that MCP servers can securely access.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. This feature allows you to separate data into logical partitions, making it easier to analyze and process data later.
Companies of all sizes face mounting pressure to operate efficiently as they manage growing volumes of data, systems, and customer interactions. SageMaker Unified Studio, using Amazon DataZone , provides a comprehensive data management solution through its integrated services.
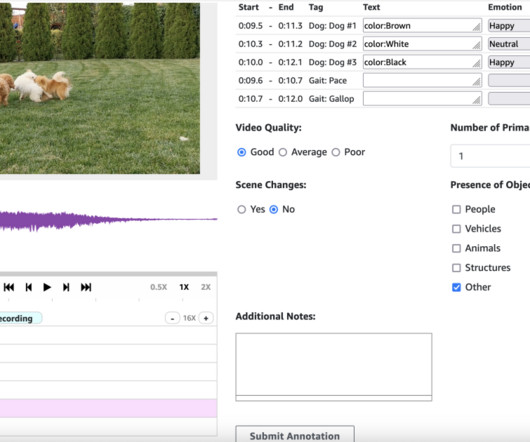
This setup enables the model to learn from human-labeled data, refining its ability to produce content that aligns with natural human expectations. Importance of high-quality data and reducing labeling errors High-quality data is essential for training generative AI models that can produce natural, human-like audio and video content.
Although weather information is accessible through multiple channels, businesses that heavily rely on meteorological data require robust and scalable solutions to effectively manage and use these critical insights and reduce manual processes. An agent helps your end users complete actions based on organization data and user input.
The LLM can then use its extensive knowledge base, which can be regularly updated with the latest medical research and clinical trial data, to provide relevant and trustworthy responses tailored to the patients specific situation. Extraction of relevant data points for electronic health records (EHRs) and clinical trial databases.
Databases are growing at an exponential rate these days, and so when it comes to real-time data observability, organizations are often fighting a losing battle if they try to run analytics or any observability process in a centralized way. ” he exclaimed.). “It makes us much more unique.”
How about security When the device sends its data, it also contains the identifier of the device itself. This allows you to use a Lambda function to use business logic to decide whether the call can be performed. Based on those questions, you might pivot your solution’s architecture. Using a queue completely decouples it.
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. The following diagram illustrates the architecture of the application.
I summarized my key takeaways that can help you improve your serverless architectures. From Lambda-lith to Step Function A common anti-pattern in serverless architecture is creating a “Lambda-lith” – a monolithic Lambda function that handles too many responsibilities. With expressions like $.account.order.product.price.sum()
Too often serverless is equated with just AWS Lambda. Yes, it’s true: Amazon Web Services (AWS) helped to pioneer what is commonly referred to as serverless today with AWS Lambda, which was first announced back in 2015. Lambda is just one component of a modern serverless stack.
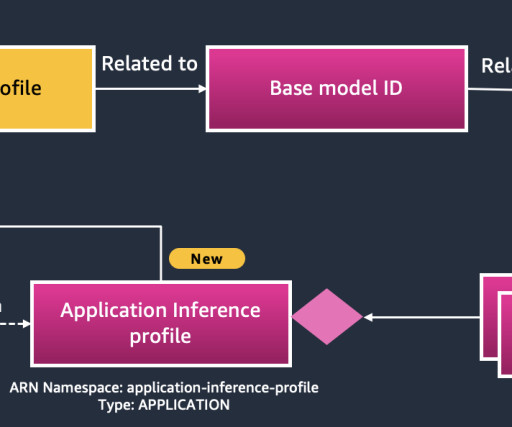
InvokeModelWithResponseStream API : Invokes the model and streams the response, useful for handling large data outputs or long-running processes. The architecture in the preceding figure illustrates two methods for dynamically retrieving inference profile ARNs based on tags.
The opportunities to unlock value using AI in the commercial real estate lifecycle starts with data at scale. Although CBRE provides customers their curated best-in-class dashboards, CBRE wanted to provide a solution for their customers to quickly make custom queries of their data using only natural language prompts.
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional data integration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Consider a global retail site operating across multiple regions and countries.
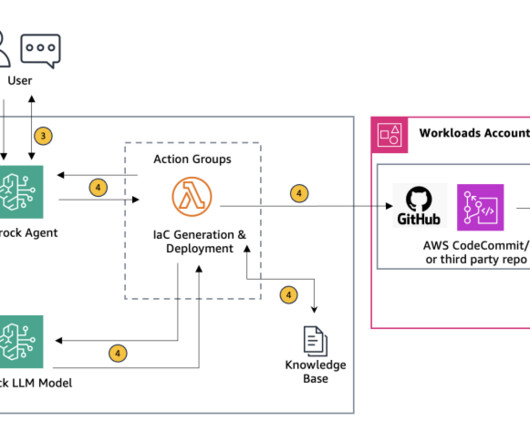
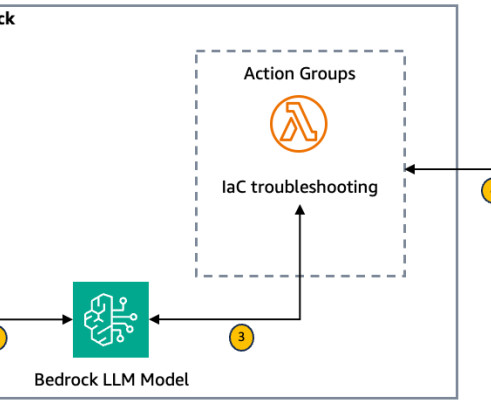
This solution shows how Amazon Bedrock agents can be configured to accept cloud architecture diagrams, automatically analyze them, and generate Terraform or AWS CloudFormation templates. Solution overview Before we explore the deployment process, let’s walk through the key steps of the architecture as illustrated in Figure 1.
The following is a review of the book Fundamentals of Data Engineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a data engineer.
Create business intelligence (BI) dashboards for visual representation and analysis of event data. For instance, programmatic rules for event attribute-based noise filtering lack flexibility when faced with organizational changes, expansion of the service footprint, or new data source formats, leading growing complexity.
Archival data in research institutions and national laboratories represents a vast repository of historical knowledge, yet much of it remains inaccessible due to factors like limited metadata and inconsistent labeling. The following diagram illustrates the solution architecture. Click here to open the AWS console and follow along.
It enables you to privately customize the FM of your choice with your data using techniques such as fine-tuning, prompt engineering, and retrieval augmented generation (RAG) and build agents that run tasks using your enterprise systems and data sources while adhering to security and privacy requirements.
For company research, the system conducts in-depth investigations of portfolio companies and collects vital financial and operational data. This architecture demonstrates the significant advantages of deploying multiple specialized agents, each designed to handle distinct aspects of complex tasks such as financial analysis.
Our proposed architecture provides a scalable and customizable solution for online LLM monitoring, enabling teams to tailor your monitoring solution to your specific use cases and requirements. A modular architecture, where each module can intake model inference data and produce its own metrics, is necessary.
Solution overview Before we dive into the deployment process, lets walk through the key steps of the architecture as illustrated in the following figure. This function invokes another Lambda function (see the following Lambda function code ) which retrieves the latest error message from the specified Terraform Cloud workspace.
In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda. Solution overview The following diagram illustrates our solution architecture. The ObjectCreator prompt converts the natural language requests into a data structure (JSON format). awscli>=1.29.57
The good news is that deploying these applications on a serverless architecture can make it easier to protect them. Cloud-native architecture has opened up new avenues for developers, bringing individual components out of monolithic server configurations and making them readily available as consumable services. Here’s why.
By extracting key data from testing reports, the system uses Amazon SageMaker JumpStart and other AWS AI services to generate CTDs in the proper format. Because of the sensitive nature of the data and effort involved, pharmaceutical companies need a higher level of control, security, and auditability.
Specifically, such data analysis can result in predicting trends and public sentiment while also personalizing customer journeys, ultimately leading to more effective marketing and driving business. The central goal is to empower customers to directly query and analyze their creative performance data through a chat interface.
Early in 2016, TrueCar decided to move internet operations off premises from its data centers to the AWS cloud. Not only did TrueCar need to move their domain DNS entries, they also needed to revamp their entire architecture, software, and operational practices. We also included a range key for the URI part of the request.
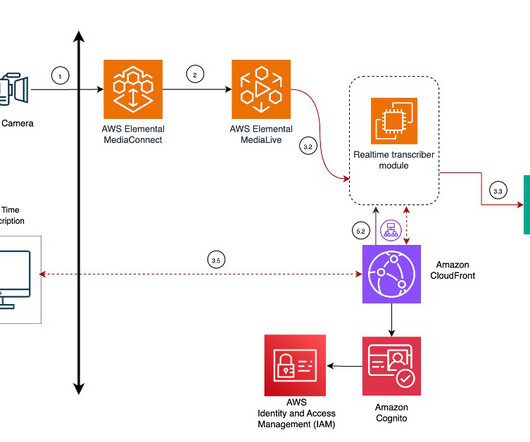
Seamless live stream acquisition The solution begins with an IP-enabled camera capturing the live event feed, as shown in the following section of the architecture diagram. A serverless, event-driven workflow using Amazon EventBridge and AWS Lambda automates the post-event processing.
This was not only about rewriting applications, but the backend data stores were also redesigned in terms of dynamic scalability , high performance, and flexibility for event-driven architecture.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content