This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataarchitecture definition Dataarchitecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations dataarchitecture is the purview of data architects.
From customer service chatbots to marketing teams analyzing call center data, the majority of enterprises—about 90% according to recent data —have begun exploring AI. For companies investing in data science, realizing the return on these investments requires embedding AI deeply into business processes.
In todays economy, as the saying goes, data is the new gold a valuable asset from a financial standpoint. A similar transformation has occurred with data. More than 20 years ago, data within organizations was like scattered rocks on early Earth.
The next phase of this transformation requires an intelligent data infrastructure that can bring AI closer to enterprise data. The challenges of integrating data with AI workflows When I speak with our customers, the challenges they talk about involve integrating their data and their enterprise AI workflows.
In an effort to be data-driven, many organizations are looking to democratize data. However, they often struggle with increasingly larger data volumes, reverting back to bottlenecking data access to manage large numbers of dataengineering requests and rising data warehousing costs.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
The O’Reilly Data Show Podcast: A special episode to mark the 100th episode. This episode of the Data Show marks our 100th episode. We had a collection of friends who were key members of the data science and big data communities on hand and we decided to record short conversations with them.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
Hes seeing the need for professionals who can not only navigate the technology itself, but also manage increasing complexities around its surrounding architectures, data sets, infrastructure, applications, and overall security. There are data scientists, but theyre expensive, he says.
Data architect role Data architects are senior visionaries who translate business requirements into technology requirements and define data standards and principles, often in support of data or digital transformations. Data architects are frequently part of a data science team and tasked with leading data system projects.
Being at the top of data science capabilities, machine learning and artificial intelligence are buzzing technologies many organizations are eager to adopt. However, they often forget about the fundamental work – data literacy, collection, and infrastructure – that must be done prior to building intelligent data products.
As many companies that have already adopted off-the-shelf GenAI models have found, getting these generic LLMs to work for highly specialized workflows requires a great deal of customization and integration of company-specific data. million on inference, grounding, and data integration for just proof-of-concept AI projects.
RudderStack , a platform that focuses on helping businesses build their customer data platforms to improve their analytics and marketing efforts, today announced that it has raised a $56 million Series B round led by Insight Partners, with previous investors Kleiner Perkins and S28 Capital also participating. Image Credits: RudderStack.
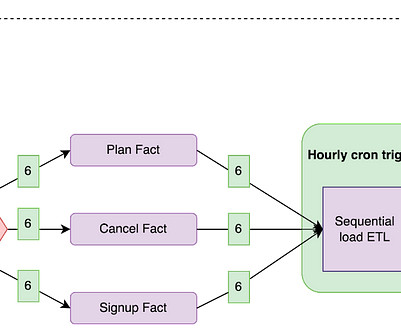
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Data pipelines are composed of multiple steps with dependencies and triggers.
Today, IT encompasses site reliability engineering (SRE), platform engineering, DevOps, and automation teams, and the need to manage services across multi-cloud and hybrid-cloud environments in addition to legacy systems. At the same time, the scale of observability data generated from multiple tools exceeds human capacity to manage.
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Introduction to the Data Mesh Architecture and its Required Capabilities.
Meroxa , a startup that makes it easier for businesses to build the data pipelines to power both their analytics and operational workflows, today announced that it has raised a $15 million Series A funding round led by Drive Capital. “Honestly, people come to us as a real-time FiveTran or real-time data warehouse sink. .
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. It’s no longer driven by data volumes, but containerization, separation of storage and compute, and democratization of analytics.
We are continuously deploying new data capabilities and insights, we are pushing forward with our digital progression agenda, and we’re also building these generative AI capabilities internally to help our employees have more productivity in their day to day. What’s your mindset when it comes to data? We’re modernizing our ecosystem.
The trouble is, when people in the business do their own thing, IT loses control, and protecting against loss of data and intellectual property becomes an even bigger concern. AI models will be developed differently for different industries, and different data will be used to train for the healthcare industry than for logistics, for example.
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Explaining the difference, especially when they both work with something intangible such as data , is difficult. If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. Data science vs dataengineering.
In the annual Porsche Carrera Cup Brasil, data is essential to keep drivers safe and sustain optimal performance of race cars. Until recently, getting at and analyzing that essential data was a laborious affair that could take hours, and only once the race was over. The process took between 30 minutes and two hours.
Israeli startup Firebolt has been taking on Google’s BigQuery, Snowflake and others with a cloud data warehouse solution that it claims can run analytics on large datasets cheaper and faster than its competitors. Big data is at the heart of how a lot of applications, and a lot of business overall, works these days.
For example, events such as Twitters rebranding to X, and PySparks rise in the dataengineering realm over Spark have all contributed to this decline. The initial excitement that once propelled the language into the limelight during the mid-2010s has diminished over the last 15 years.
Over the last decade, the rate at which organizations create data has accelerated as it becomes cheaper to store, access, and process data. But as data continues to grow in scale and complexity, it’s becoming scattered across apps and platforms — often leading to problems where it concerns data quality.
For years, IT and business leaders have been talking about breaking down the data silos that exist within their organizations. In fact, as companies undertake digital transformations , usually the data transformation comes first, and doing so often begins with breaking down data — and political — silos in various corners of the enterprise.
To find out, he queried Walgreens’ data lakehouse, implemented with Databricks technology on Microsoft Azure. “We Previously, Walgreens was attempting to perform that task with its data lake but faced two significant obstacles: cost and time. Enter the data lakehouse. Lakehouses redeem the failures of some data lakes.
While models and algorithms garner most of the media coverage, this is a great time to be thinking about building tools in data. In this post I share slides and notes from a keynote I gave at the Strata Data Conference in London at the end of May. Economic value of data.
The promise of a modern data lakehouse architecture. Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. What is late-arriving data? Let’s dive in!
Job titles like dataengineer, machine learning engineer, and AI product manager have supplanted traditional software developers near the top of the heap as companies rush to adopt AI and cybersecurity professionals remain in high demand. Demand for developers is simply growing at a slower rate than other IT roles.
According to the MIT Technology Review Insights Survey, an enterprise data strategy supports vital business objectives including expanding sales, improving operational efficiency, and reducing time to market. The problem is today, just 13% of organizations excel at delivering on their data strategy.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DevOps continues to get a lot of attention as a wave of companies develop more sophisticated tools to help developers manage increasingly complex architectures and workloads. And as data workloads continue to grow in size and use, they continue to become ever more complex. ” Not a great scenario. .”
Modak, a leading provider of modern dataengineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera DataEngineering (CDE) integration with Modak Nabu.
The implementation was a over-engineered custom Feast implementation using unsupported backend data stores. The engineer that implemented it had left the company by the time I joined. Mind, data lineage and discoverability become paramount when collaborating on features. You have complete access to all historical data.
Cloudera is committed to providing the most optimal architecture for data processing, advanced analytics, and AI while advancing our customers’ cloud journeys. Together, Cloudera and AWS empower businesses to optimize performance for data processing, analytics, and AI while minimizing their resource consumption and carbon footprint.
Coalesce is a startup that offers data transformation tools geared mainly toward enterprise customers. Petrossian met Coalesce’s other co-founder, Satish Jayanthi, at WhereScape, where the two were responsible for solving data warehouse problems for large organizations. (In
Heartex, a startup that bills itself as an “open source” platform for data labeling, today announced that it landed $25 million in a Series A funding round led by Redpoint Ventures. We agreed that the only viable solution was to have internal teams with domain expertise be responsible for annotating and curating training data.
By George Trujillo, Principal Data Strategist, DataStax Innovation is driven by the ease and agility of working with data. Increasing ROI for the business requires a strategic understanding of — and the ability to clearly identify — where and how organizations win with data.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content