This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Modernizing pipelines. With the release of Spark 3.1
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. Each unlocking value in the dataengineering workflows enterprises can start taking advantage of. Usage Patterns.
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
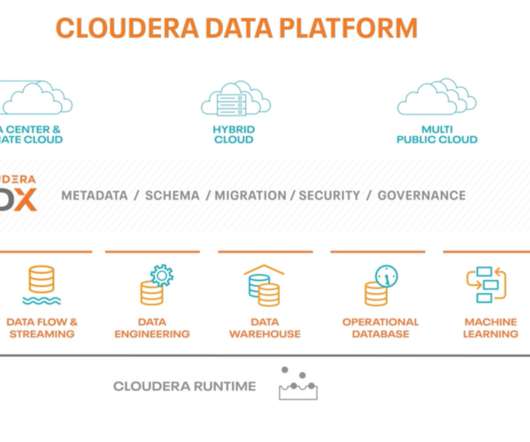
What is Cloudera DataEngineering (CDE) ? Cloudera DataEngineering is a serverless service for Cloudera Data Platform (CDP) that allows you to submit jobs to auto-scaling virtual clusters. Refer to the following cloudera blog to understand the full potential of Cloudera DataEngineering. .
Modak, a leading provider of modern dataengineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera DataEngineering (CDE) integration with Modak Nabu.
Your data demands, like your data itself, are outpacing your dataengineering methods and teams. You’ll discover that they all have identified datavirtualization as a must-have addition to your data integration tooling and a critical enabler to a more modern, distributed dataarchitecture.
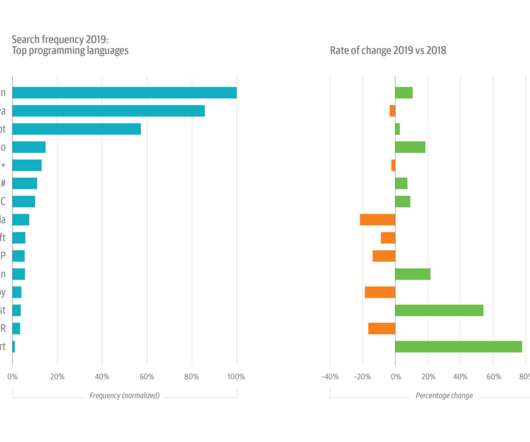
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. Software architecture, infrastructure, and operations are each changing rapidly. Along with R , Python is one of the most-used languages for data analysis.
Introduction: We often end up creating a problem while working on data. So, here are few best practices for dataengineering using snowflake: 1.Transform Each data model has its own advantages and storing intermediate step results has significant architectural advantages.
Snowflake and Capgemini powering data and AI at scale Capgemini October 13, 2020 Organizations slowed by legacy information architectures are modernizing their data and BI estates to achieve significant incremental value with relatively small capital investments. This evolution is also being driven by many industry factors.
We will define how enterprise warehouses are different from the usual ones, what types of data warehouses exist, and how they work. The focus of this material is to provide information about the business value of each architectural and conceptual approach to building a warehouse. What is an Enterprise Data Warehouse?
To break data silos and speed up access to all enterprise information, organizations can opt for an advanced data integration technique known as datavirtualization. This post is a perfect place to learn about this approach, its architecture components, differences, benefits, tools, and more. Real-time access.
The vendor-neutral certification covers topics such as organizational structure, security and risk management, asset security, security operations, identity and access management (IAM), security assessment and testing, and security architecture and engineering.
This custom knowledge base that connects these diverse data sources enables Amazon Q to seamlessly respond to a wide range of sales-related questions using the chat interface. The following diagram illustrates the solution architecture. Under Connectivity , for Virtual private cloud (VPC) , choose the VPC that you created.
We’ll review all the important aspects of their architecture, deployment, and performance so you can make an informed decision. Before jumping into the comparison of available products right away, it will be a good idea to get acquainted with the data warehousing basics first. Data warehouse architecture.
The same can be said for IT, and especially dataengineers, responsible for providing data to business consumers. To perform their work, quickly and well, they need to have all the right tools in their data integration toolbox. Data services orchestration. ? Datavirtualization. ? Replication. ?
Databricks Streaming and Apache Flink are two popular stream processing frameworks that enable developers to build real-time data pipelines, applications and services at scale. Comparison Databricks is an integrated platform for dataengineering, machine learning, data science and analytics built on top of Apache Spark.
Hot: AI and VR/AR With digital transformations moving at full throttle, and a desire to stay innovative, it should come as no surprise that use cases for virtual reality, augmented reality, and artificial intelligence continue to grow in several verticals.
IDC analyst Jason Leigh says Verizon made the right move to build a tool to facilitate customer migrations, but adds that there will be challenges whenever a CIO or C-suite move their data and traffic to new environments.
CDP-PC provides the same fine-grained access control as on-prem for data warehouse querying (Hive or Apache Impala ), search index lookups ( Apache Solr ), and applications built upon operational database tables ( Apache HBase ). Customer 1 – Centralized data authorization management. Conclusion.
Cloudera Data Platform Powered by NVIDIA RAPIDS Software Aims to Dramatically Increase Performance of the Data Lifecycle Across Public and Private Clouds. This exciting initiative is built on our shared vision to make data-driven decision-making a reality for every business. Compared to previous CPU-based architectures, CDP 7.1
How to optimize an enterprise dataarchitecture with private cloud and multiple public cloud options? As the inexorable drive to cloud continues, telecommunications service providers (CSPs) around the world – often laggards in adopting disruptive technologies – are embracing virtualization.
This has also accelerated the execution of edge computing solutions so compute and real-time decisioning can be closer to where the data is generated. Augmented or virtual reality, gaming, and the combination of gamification with social media leverages AI for personalization and enhancing online dynamics.
Key survey results: The C-suite is engaged with data quality. Data scientists and analysts, dataengineers, and the people who manage them comprise 40% of the audience; developers and their managers, about 22%. Data quality might get worse before it gets better. An additional 7% are dataengineers.
That’s part of why I was excited to attend the “What’s New and What’s Next for TIBCO® DataVirtualization ” session at our recent TIBCO NOW event. . For instance: How will this new capability impact my client’s as-is and future architectures? Where TIBCO DataVirtualization Advancements Help. Show Me The Money!
Data Catalog profilers have been run on existing databases in the Data Lake. A Cloudera Data Warehouse virtual warehouse with Cloudera Data Visualisation enabled exists. A Cloudera DataEngineering service exists. The Data Scientist. The DataEngineer.
Many customers looking at modernizing their pipeline orchestration have turned to Apache Airflow, a flexible and scalable workflow manager for dataengineers. CDE provides a managed Spark service that can be accessed via a simple REST end-point in a CDE Virtual Cluster called the Jobs API (learn how to set up a Virtual Cluster here ).
A detailed view of the KAWAII architecture. InnoGames KAWAII accesses data from our internal wiki and optionally also tickets from Jira. To ensure the relevance of the information and avoid outdated data, we can use the Confluence Query Language (CQL) to specifically select the wiki pages that are to be integrated into KAWAII.
Extra searching about the arch command lead me to this final command to start a Terminal session with the x86_64 architecture: arch -x86_64 /bin/zsh --login for this to work Rosetta needs to be installed. The software used also needs to be architecture specific. Well not really. We are only halfway. brew install python@3.8
What’s more, Gartner identifies data fabric implementation as one of the top strategic technology trends for 2022 and expects that by 2024, data fabric deployments will increase the efficiency of data use while halving human-driven data management tasks. What is data fabric? Data fabric architecture example.
However, there is still some confusion regarding the finer details of a data fabric and how it can provide the most benefit to your business. Animal, Vegetable, or Architecture? Breaking Down Data Fabrics. It’s obviously important to understand what a data fabric is, but it is equally critical to know what a data fabric is not.
In addition, data pipelines include more and more stages, thus making it difficult for dataengineers to compile, manage, and troubleshoot those analytical workloads. different analytical frameworks) for complex use cases that span different stages across the data lifecycle? CRM platforms).
In matters concerning operations, architecture and DevOps, any barriers are overcome by the ubiquitous engineering mindset both our companies have been fostering. kol , Chief of DataEngineering. Working with the people at Xebia is like working with colleagues I’ve known for a long time. Organization. Krzysztof K?kol
I recently teamed up with Austrian customer Raiffeisen Bank , Dutch partner Connected Data Group , and German partner QuinScape to deliver a webinar entitled “Next-Generation DataVirtualization Has Arrived.” Connected Data Group helps clients become more data-driven and was co-founded with Antoine Stelma.
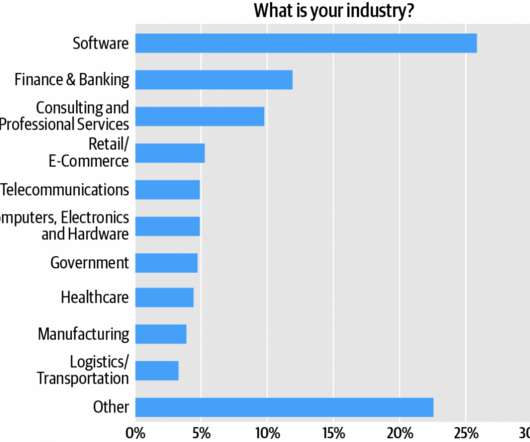
Software engineers comprise the survey audience’s single largest cluster, over one quarter (27%) of respondents (Figure 1). If you combine the different architectural roles—i.e., Adding architects and engineers, we see that roughly 55% of the respondents are directly involved in software development.
Managing and retrieving the right information can be complex, especially for data analysts working with large data lakes and complex SQL queries. Looker is an enterprise platform for BI and data applications that helps data analysts explore and share insights in real time.
While billing used to be one of two critical things for any successful telco (the other being the network), today’s digital service providers prioritise channels, ecosystems, payments and cloud service architectures in enterprise architecture. Edge analytics by definition require in-network deployment.
Data Innovation Summit topics. Same as last year, the event offers six workshops (crash-course) themes, each dedicated to a unique domain area: Data-driven Strategy, Analytics & Visualisation, Machine Learning, IoT Analytics & Data Management, Data Management and DataEngineering.
Highly available networks are resistant to failures or interruptions that lead to downtime and can be achieved via various strategies, including redundancy, savvy configuration, and architectural services like load balancing. Resiliency. Resilient networks can handle attacks, dropped connections, and interrupted workflows.
For lack of similar capabilities, some of our competitors began implying that we would no longer be focused on the innovative data infrastructure, storage and compute solutions that were the hallmark of Hitachi Data Systems. A midrange user now has access to the same, super-powerful features as the biggest banks.
As you modernize your dataarchitectures, you must consider these two truths. First, today’s diverse, distributed data environments are the new normal. Second, trying to centralize all their data in a single location is a fools’ errand. Today’s Data Topology . DataVirtualization Rises to The Challenge.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
To win the data game, it helps to deal yourself four aces. In my last blog , I shared your first two aces, adaptive dataarchitecture and agile methods. Your Third Ace: Advanced Data Management Technology. Data management processes that embrace business domain expertise and thereby improve data quality and relevance.
We’ll dive deeper into Snowflake’s pros and cons, its unique architecture, and its features to help you decide whether this data warehouse is the right choice for your company. Data warehousing in a nutshell. BTW, we have an engaging video explaining how dataengineering works.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content