This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataarchitecture definition Dataarchitecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations dataarchitecture is the purview of data architects.
The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both. Imagine that you’re a dataengineer. The data is spread out across your different storage systems, and you don’t know what is where.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Cloudera is committed to providing the most optimal architecture for data processing, advanced analytics, and AI while advancing our customers’ cloud journeys. Lakehouse Optimizer : Cloudera introduced a service that automatically optimizes Iceberg tables for high-performance queries and reduced storage utilization.
The data architect also “provides a standard common business vocabulary, expresses strategic requirements, outlines high-level integrated designs to meet those requirements, and aligns with enterprise strategy and related business architecture,” according to DAMA International’s Data Management Body of Knowledge.
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Securing and scaling storage. Modernizing pipelines.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. It’s no longer driven by data volumes, but containerization, separation of storage and compute, and democratization of analytics.
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Designed with a serverless, cost-optimized architecture, the platform provisions SageMaker endpoints dynamically, providing efficient resource utilization while maintaining scalability. The following diagram illustrates the solution architecture. Key architectural decisions drive both performance and cost optimization.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
download Model-specific cost drivers: the pillars model vs consolidated storage model (observability 2.0) All of the observability companies founded post-2020 have been built using a very different approach: a single consolidated storageengine, backed by a columnar store. and observability 2.0. understandably). moving forward.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
So, along with data scientists who create algorithms, there are dataengineers, the architects of data platforms. In this article we’ll explain what a dataengineer is, the field of their responsibilities, skill sets, and general role description. What is a dataengineer?
Modak, a leading provider of modern dataengineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera DataEngineering (CDE) integration with Modak Nabu.
MaestroQA integrated Amazon Bedrock into their existing architecture using Amazon Elastic Container Service (Amazon ECS). The customer interaction transcripts are stored in an Amazon Simple Storage Service (Amazon S3) bucket. The following architecture diagram demonstrates the request flow for AskAI.
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloud storage (S3 for AWS, ADLS-gen2 for Azure).
The first data source connected was an Amazon Simple Storage Service (Amazon S3) bucket, where a 100-page RFP manual was uploaded for natural language querying by users. The data source allowed accurate results to be returned based on indexed content. Joel Elscott is a Senior DataEngineer on the Principal AI Enablement team.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. This greatly increases data processing capabilities.
This year’s sessions on DataEngineering and Architecture showcases streaming and real-time applications, along with the data platforms used at several leading companies. On the infrastructure side, we have sessions from members of some of the leading stream processing and storage communities. Data platforms.
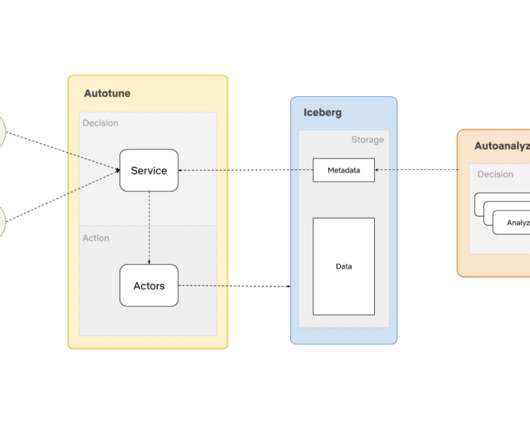
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Introduction: We often end up creating a problem while working on data. So, here are few best practices for dataengineering using snowflake: 1.Transform So, resist the temptation to periodically load data using other methods (such as querying external tables). Use it, but don’t use it for normal large data loads.
DevOps continues to get a lot of attention as a wave of companies develop more sophisticated tools to help developers manage increasingly complex architectures and workloads. And as data workloads continue to grow in size and use, they continue to become ever more complex. Doing so manually can be time-consuming, if not impossible.
Our Databricks Practice holds FinOps as a core architectural tenet, but sometimes compliance overrules cost savings. Deletion vectors are a storage optimization feature that replaces physical deletion with soft deletion. Instead of physically deleting data, a deletion vector marks records as deleted at the storage layer.
They may also ensure consistency in terms of processes, architecture, security, and technical governance. Our platform engineering teams, which support more than 200 applications, have innovated around automation,” says Bob Simms, former director of enterprise infrastructure delivery at the US Patent and Trademark Office (USPTO).
Similar to humans companies generate and collect tons of data about the past. And this data can be used to support decision making. While our brain is both the processor and the storage, companies need multiple tools to work with data. And one of the most important ones is a data warehouse. Subject-oriented data.
Agencies are plagued by a wide range of data formats and storage environments—legacy systems, databases, on-premises applications, citizen access portals, innumerable sensors and devices, and more—that all contribute to a siloed ecosystem and the data management challenge. . Modern dataarchitectures. Forrester ).
For lack of similar capabilities, some of our competitors began implying that we would no longer be focused on the innovative data infrastructure, storage and compute solutions that were the hallmark of Hitachi Data Systems. A REST API is built directly into our VSP storage controllers.
I mentioned in an earlier blog titled, “Staffing your big data team, ” that dataengineers are critical to a successful data journey. That said, most companies that are early in their journey lack a dedicated engineering group. Image 1: DataEngineering Skillsets.
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Data warehouse architecture.
The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket. Solution overview Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge.
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Supports Disaggregation of compute and storage.
When asked, Heartex says that it doesn’t collect any customer data and open sources the core of its labeling platform for inspection. “We’ve built a dataarchitecture that keeps data private on the customer’s storage, separating the data plane and control plane,” Malyuk added.
So Thermo Fisher Scientific CIO Ryan Snyder and his colleagues have built a data layer cake based on a cascading series of discussions that allow IT and business partners to act as one team. Martha Heller: What are the business drivers behind the dataarchitecture ecosystem you’re building at Thermo Fisher Scientific?
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
To do this, they are constantly looking to partner with experts who can guide them on what to do with that data. This is where dataengineering services providers come into play. Dataengineering consulting is an inclusive term that encompasses multiple processes and business functions.
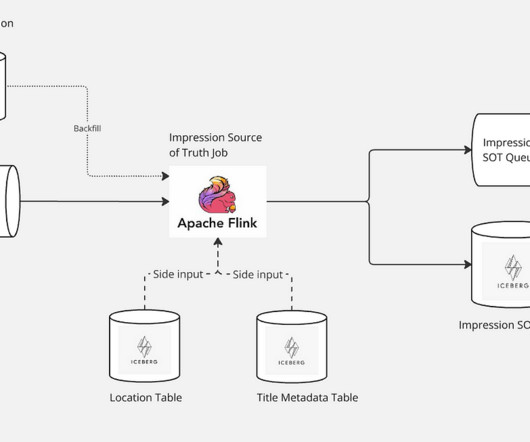
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
Data obsession is all the rage today, as all businesses struggle to get data. But, unlike oil, data itself costs nothing, unless you can make sense of it. Dedicated fields of knowledge like dataengineering and data science became the gold miners bringing new methods to collect, process, and store data.
Now, as more faculty, staff, and students are accessing information on-premises and in the cloud, IT has a borderless network and the team is implementing a zero-trust network architecture, says CIO Mugunth Vaithylingam. On-prem infrastructure will grow cold — with the exception of storage, Nardecchia says.
My goal was to remind the data community about the many interesting opportunities and challenges in data itself. Because large deep learning architectures are quite data hungry, the importance of data has grown even more. Economic value of data. control over how their data is shared and used.
But, in any case, the pipeline would provide dataengineers with means of managing data for training, orchestrating models, and managing them on production. Machine learning production pipeline architecture. Here we’ll look at the common architecture and the flow of such a system.
Organizations have balanced competing needs to make more efficient data-driven decisions and to build the technical infrastructure to support that goal. From architectures and databases to feature stores and feature engineering, a myriad of variables must work in sync for this to be accomplished.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content