This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DataarchitecturedefinitionDataarchitecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations dataarchitecture is the purview of data architects.
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. Furthermore, generally speaking, data should not be split across multiple databases on different cloud providers to achieve cloud neutrality.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
Please have a look at this blog post on machine learning serving architectures if you do not know the difference. Let’s say you are a Data Scientist working in a model development environment. You have complete access to all historical data. Teams can share features definitions to prevent them from reinventing the wheel.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Introduction to the Data Mesh Architecture and its Required Capabilities.
Therefore, its not surprising that DataEngineering skills showed a solid 29% increase from 2023 to 2024. Interest in Data Lake architectures rose 59%, while the much older Data Warehouse held steady, with a 0.3% Its worth understanding the connection between dataengineering, data lakes, and data lakehouses.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
Breaking down silos has been a drumbeat of data professionals since Hadoop, but this SAP <-> Databricks initiative may help to solve one of the more intractable dataengineering problems out there. SAP has a large, critical data footprint in many large enterprises. However, SAP has an opaque data model.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. Big data processing. maintaining data pipeline.
quintillion bytes of data generated daily, data scientists get busier than ever. And data science provides us with methods to make use of this data. So while you search for a definition of “quintillion”, Google probably learns that you have this knowledge gap. What is a dataengineer?
You start out really small, perhaps a Proof of Concept, a small app or dataengineering pipeline. Point 1 you most likely cannot learn from a blog post, but point 2 is definitively something we can tackle here. Architecture rules are defined in simple Pytest test cases and can run as part of a CI/CD pipeline.
This post was co-written with Vishal Singh, DataEngineering Leader at Data & Analytics team of GoDaddy Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) in these solutions has become increasingly popular.
Data visualization definition. Data visualization is the presentation of data in a graphical format such as a plot, graph, or map to make it easier for decision makers to see and understand trends, outliers, and patterns in data. Maps and charts were among the earliest forms of data visualization.
But, in any case, the pipeline would provide dataengineers with means of managing data for training, orchestrating models, and managing them on production. A dedicated team of data scientists or people with a business domain would define the data that will be used for training.
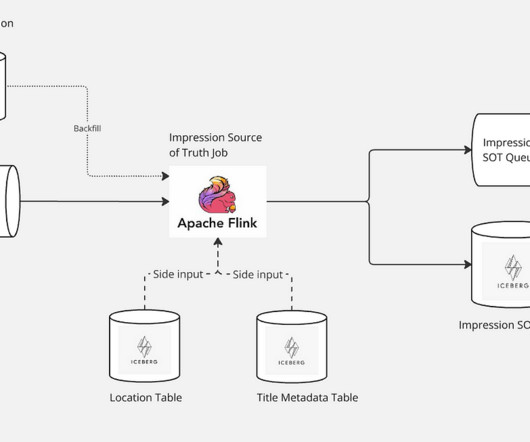
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflixs impression data.
Here, I’ll focus on why these three elements and capabilities are fundamental building blocks of a data ecosystem that can support real-time AI. DataStax Real-time data and decisioning First, a few quick definitions. Real-time data involves a continuous flow of data in motion.
Data obsession is all the rage today, as all businesses struggle to get data. But, unlike oil, data itself costs nothing, unless you can make sense of it. Dedicated fields of knowledge like dataengineering and data science became the gold miners bringing new methods to collect, process, and store data.
We’ll review all the important aspects of their architecture, deployment, and performance so you can make an informed decision. Before jumping into the comparison of available products right away, it will be a good idea to get acquainted with the data warehousing basics first. Data warehouse architecture.
Learning data science through books will help you get a holistic view of Data Science as data science is not just about computing, it also includes mathematics, probability, statistics, programming, machine learning, and much more. Top Data science books you should definitely read.
What’s more, Gartner identifies data fabric implementation as one of the top strategic technology trends for 2022 and expects that by 2024, data fabric deployments will increase the efficiency of data use while halving human-driven data management tasks. What is data fabric? Data fabric architecture example.
Streamlit This open source Python library makes it straightforward to create and share beautiful, custom web apps for ML and data science. In just a few minutes you can build powerful data apps using only Python. The following diagram shows the solution architecture. About the Author Rajendra Choudhary is a Sr.
Our data scientists often want to apply their knowledge of the business and statistics to fully understand the outcome of an experiment. Instead of relying on engineers to productionize scientific contributions, we’ve made a strategic bet to build an architecture that enables data scientists to easily contribute.
Your data demands, like your data itself, are outpacing your dataengineering methods and teams. You’ll discover that they all have identified data virtualization as a must-have addition to your data integration tooling and a critical enabler to a more modern, distributed dataarchitecture.
The Power of the Architecture-driven Organisation. Engineers in an agile development team generally do not have much control over this scenario, but as a consultant it is something I would definitely want to highlight in order to give Project Positron the best chance of success in its organisation. – Melvin Conway.
There’s no clear problem formulation, no clear loss function, lots of various data sets to use. Learning stuff is what matters and kind of by definition you have to do stupid s**t before you learned it. What do you wish you knew earlier about being a data scientist? I don’t consider myself a data scientist so not sure :).
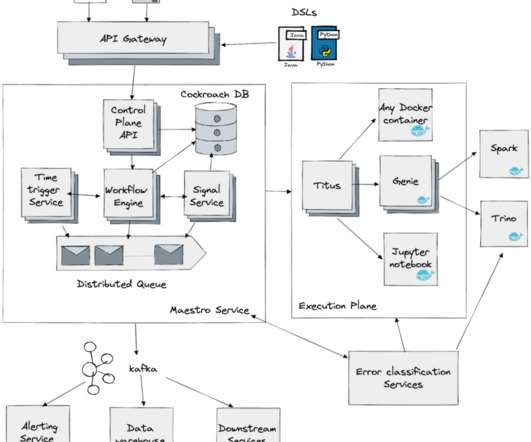
Meson was based on a single leader architecture with high availability. We want users to rely on shared templates and reuse their workflow definitions across their team, saving time and effort on creating the same functionality. Figure 1 shows the high-level architecture. With the high growth of workflows in the past few years?
There’s no clear problem formulation, no clear loss function, lots of various data sets to use. Learning stuff is what matters and kind of by definition you have to do stupid s**t before you learned it. What do you wish you knew earlier about being a data scientist? I don’t consider myself a data scientist so not sure :).
While billing used to be one of two critical things for any successful telco (the other being the network), today’s digital service providers prioritise channels, ecosystems, payments and cloud service architectures in enterprise architecture. Edge analytics by definition require in-network deployment.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” Nonetheless, Netflix data landscape (see below) is complex and many teams collaborate effectively for sharing the responsibility of our data system management.
While we like to talk about how fast technology moves, internet time, and all that, in reality the last major new idea in software architecture was microservices, which dates to roughly 2015. Who wants to learn about design patterns or software architecture when some AI application may eventually do your high-level design?
Highly available networks are resistant to failures or interruptions that lead to downtime and can be achieved via various strategies, including redundancy, savvy configuration, and architectural services like load balancing. Resiliency. Resilient networks can handle attacks, dropped connections, and interrupted workflows.
As the use of ChatGPT becomes more prevalent, I frequently encounter customers and data users citing ChatGPT’s responses in their discussions. I love the enthusiasm surrounding ChatGPT and the eagerness to learn about modern dataarchitectures such as data lakehouses, data meshes, and data fabrics.
Shell, Adobe, Burberry, Columbia, Bayer — you definitely know the names. The answer is simple: They use the same technology to make the most of data. Along with thousands of other data-driven organizations from different industries, the above-mentioned leaders opted for Databrick to guide strategic business decisions.
One-sixth of respondents identify as data scientists, but executives—i.e., The survey does have a data-laden tilt, however: almost 30% of respondents identify as data scientists, dataengineers, AIOps engineers, or as people who manage them. All told, more than 70% of respondents work in technology roles.
Adhering to the don’t repeat yourself (DRY) principle, we say: similar datastore -> similar ingestion pipeline KISS (Keep It Simple, Stupid) KISS is a design and development principle that advocates for simplicity in software design, architecture, and implementation. Imagine the benefits when there are hundreds of tables!
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. The number of possible applications tends to grow due to the rise of IoT , Big Data analytics , streaming media, smart manufacturing, predictive maintenance , and other data-intensive technologies.
Similar to how DevOps once reshaped the software development landscape, another evolving methodology, DataOps, is currently changing Big Data analytics — and for the better. DataOps is a relatively new methodology that knits together dataengineering, data analytics, and DevOps to deliver high-quality data products as fast as possible.
In this article, we will explain the concept and usage of Big Data in the healthcare industry and talk about its sources, applications, and implementation challenges. Definitely, the topic is way too extensive to be covered in a blog post, so we’re only going to make a succinct overview. What is Big Data and its sources in healthcare?
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next.
To break data silos and speed up access to all enterprise information, organizations can opt for an advanced data integration technique known as data virtualization. This post is a perfect place to learn about this approach, its architecture components, differences, benefits, tools, and more. What is data virtualization?
a runtime environment (sandbox) for classic business intelligence (BI), advanced analysis of large volumes of data, predictive maintenance , and data discovery and exploration; a store for raw data; a tool for large-scale data integration ; and. a suitable technology to implement data lake architecture.
From DevOps to DataOps DataOps can be simply stated as “DevOps for data”. It is a set of practices and technologies that integrate the development and operation of data movement architectures into a continuous process. DataOps aids data practitioners to continuously deliver quality data to applications and business processes.
We’ll dive deeper into Snowflake’s pros and cons, its unique architecture, and its features to help you decide whether this data warehouse is the right choice for your company. Data warehousing in a nutshell. BTW, we have an engaging video explaining how dataengineering works.
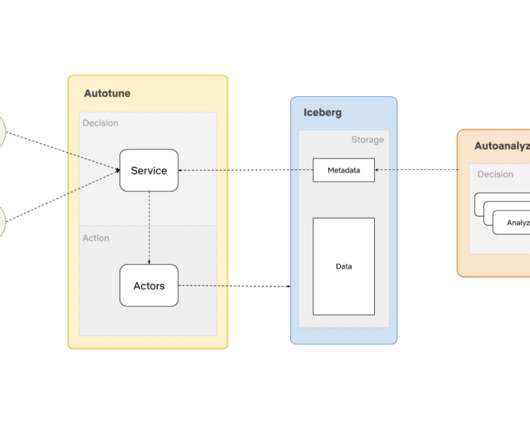
This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture. Some of the optimizations are prerequisites for a high-performance data warehouse. We store the MSE and N for each partition in Redis for later use.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content