This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataarchitecture definition Dataarchitecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations dataarchitecture is the purview of data architects.
From customer service chatbots to marketing teams analyzing call center data, the majority of enterprises—about 90% according to recent data —have begun exploring AI. For companies investing in data science, realizing the return on these investments requires embedding AI deeply into business processes.
In our real-world case study, we needed a system that would create test data. This data would be utilized for different types of application testing. The requirements for the system stated that we need to create a test data set that introduces different types of analytic and numerical errors.
In todays economy, as the saying goes, data is the new gold a valuable asset from a financial standpoint. A similar transformation has occurred with data. More than 20 years ago, data within organizations was like scattered rocks on early Earth.
In an effort to be data-driven, many organizations are looking to democratize data. However, they often struggle with increasingly larger data volumes, reverting back to bottlenecking data access to manage large numbers of data engineering requests and rising data warehousing costs.
The next phase of this transformation requires an intelligent data infrastructure that can bring AI closer to enterprise data. The challenges of integrating data with AI workflows When I speak with our customers, the challenges they talk about involve integrating their data and their enterprise AI workflows.
In today’s data-driven world, large enterprises are aware of the immense opportunities that data and analytics present. Yet, the true value of these initiatives is in their potential to revolutionize how data is managed and utilized across the enterprise. Take, for example, a recent case with one of our clients.
AI’s ability to automate repetitive tasks leads to significant time savings on processes related to content creation, data analysis, and customer experience, freeing employees to work on more complex, creative issues. Another challenge here stems from the existing architecture within these organizations.
In 2025, data management is no longer a backend operation. The evolution of cloud-first strategies, real-time integration and AI-driven automation has set a new benchmark for data systems and heightened concerns over data privacy, regulatory compliance and ethical AI governance demand advanced solutions that are both robust and adaptive.
Speaker: Jeremiah Morrow, Nicolò Bidotti, and Achille Barbieri
Data teams in large enterprise organizations are facing greater demand for data to satisfy a wide range of analytic use cases. Yet they are continually challenged with providing access to all of their data across business units, regions, and cloud environments.
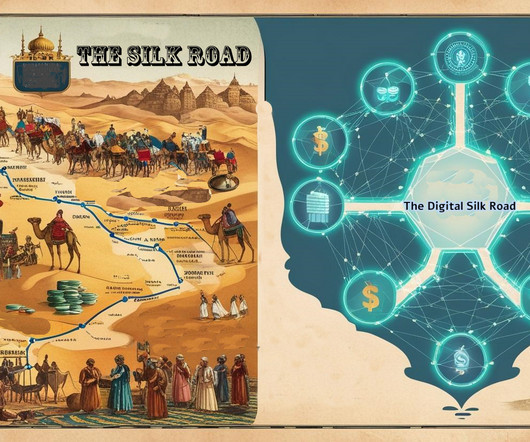
However, trade along the Silk Road was not just a matter of distance; it was shaped by numerous constraints much like todays data movement in cloud environments. Merchants had to navigate complex toll systems imposed by regional rulers, much as cloud providers impose egress fees that make it costly to move data between platforms.
Their journey offers valuable lessons for IT leaders seeking scalable and efficient architecture solutions. This story may sound familiar to many IT leaders: the business grows, but legacy IT architecture cant keep up limiting innovation and speed. Domain-Driven Design gurus could see good old bounded contexts here.
Yet, as transformative as GenAI can be, unlocking its full potential requires more than enthusiasm—it demands a strong foundation in data management, infrastructure flexibility, and governance. Trusted, Governed Data The output of any GenAI tool is entirely reliant on the data it’s given.
Data is the lifeblood of the modern insurance business. Yet, despite the huge role it plays and the massive amount of data that is collected each day, most insurers struggle when it comes to accessing, analyzing, and driving business decisions from that data. There are lots of reasons for this.
While data platforms, artificial intelligence (AI), machine learning (ML), and programming platforms have evolved to leverage big data and streaming data, the front-end user experience has not kept up. Traditional Business Intelligence (BI) aren’t built for modern data platforms and don’t work on modern architectures.
Migration to the cloud, data valorization, and development of e-commerce are areas where rubber sole manufacturer Vibram has transformed its business as it opens up to new markets. Data is the heart of our business, and its centralization has been fundamental for the group,” says Emmelibri CIO Luca Paleari.
As such, the data on labor, occupancy, and engagement is extremely meaningful. Here, CIO Patrick Piccininno provides a roadmap of his journey from data with no integration to meaningful dashboards, insights, and a data literate culture. You ’re building an enterprise data platform for the first time in Sevita’s history.
In todays digital-first economy, enterprise architecture must also evolve from a control function to an enablement platform. This transformation requires a fundamental shift in how we approach technology delivery moving from project-based thinking to product-oriented architecture. The stakes have never been higher.
The road ahead for IT leaders in turning the promise of generative AI into business value remains steep and daunting, but the key components of the gen AI roadmap — data, platform, and skills — are evolving and becoming better defined. But that’s only structured data, she emphasized. MIT event, moderated by Lan Guan, CAIO at Accenture.
With data stored in vendor-agnostic files and table formats like Apache Iceberg, the open lakehouse is the best architecture to enable data democratization. By moving analytic workloads to the data lakehouse you can save money, make more of your data accessible to consumers faster, and provide users a better experience.
While data and analytics were not entirely new to the company, there was no enterprise-wide approach. As a result, we embarked on this journey to create a cohesive enterprise data strategy. Initially, I worked as a researcher in academia, specializing in data analysis. This initiative is about creating a unified data platform.
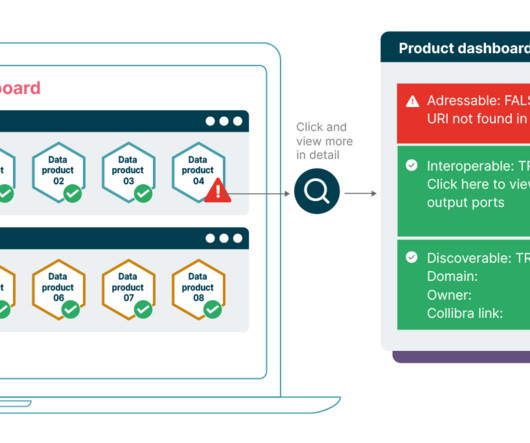
Decentralized data management requires automation to scale governance effectively. Fitness functions are a powerful automated governance technique my colleagues have applied to data products within the context of a Data Mesh.
The data landscape is constantly evolving, making it challenging to stay updated with emerging trends. That’s why we’ve decided to launch a blog that focuses on the data trends we expect to see in 2025. Poor data quality automatically results in poor decisions. That applies not only to GenAI but to all data products.
The built-in elasticity in serverless computing architecture makes it particularly appealing for unpredictable workloads and amplifies developers productivity by letting developers focus on writing code and optimizing application design industry benchmarks , providing additional justification for this hypothesis. Architecture complexity.
Data fuels the modern enterprise — today more than ever, businesses compete on their ability to turn big data into essential business insights. Increasingly, enterprises are leveraging cloud data lakes as the platform used to store data for analytics, combined with various compute engines for processing that data.
The successor to SAP ECC, S/4HANA is built on an in-memory database and is designed to enable real-time data processing and analysis for businesses. Instead of storing data mechanically on punched cards, they relied on an online dialog via keyboard and screen. It is available both in a cloud-based SaaS and an on-premises version.
The McKinsey 2023 State of AI Report identifies data management as a major obstacle to AI adoption and scaling. Enterprises generate massive volumes of unstructured data, from legal contracts to customer interactions, yet extracting meaningful insights remains a challenge.
Business leaders know its crucial to use identity-driven customer data to make smart decisions. The consequences of getting identity wrong are substantial: Poor data quality = missed insights, operational inefficiencies, and wasted marketing spend. Slow digital adoption = inability to activate customer data reliably at scale.
Allow me to explain by discussing what legacy platform modernization entails, along with tips on how to streamline the complex process of migrating data from legacy platforms. The first is migrating data and workloads off of legacy platforms entirely and rehosting them in new environments, like the public cloud.
An organization’s data is copied for many reasons, namely ingesting datasets into data warehouses, creating performance-optimized copies, and building BI extracts for analysis. Read this whitepaper to learn: Why organizations frequently end up with unnecessary data copies.
We are excited to announce the acquisition of Octopai , a leading data lineage and catalog platform that provides data discovery and governance for enterprises to enhance their data-driven decision making. This dampens confidence in the data and hampers access, in turn impacting the speed to launch new AI and analytic projects.
In CIOs 2024 Security Priorities study, 40% of tech leaders said one of their key priorities is strengthening the protection of confidential data. But with big data comes big responsibility, and in a digital-centric world, data is coveted by many players. Ravinder Arora elucidates the process to render data legible.
It prevents vendor lock-in, gives a lever for strong negotiation, enables business flexibility in strategy execution owing to complicated architecture or regional limitations in terms of security and legal compliance if and when they rise and promotes portability from an application architecture perspective.
Two things play an essential role in a firm’s ability to adapt successfully: its data and its applications. Generally speaking, a healthy application and dataarchitecture is at the heart of successful modernisation. Learn more about NTT DATA and Edge AI That’s why the issue is so important today.
The pandemic has led to new data vulnerabilities, and therefore new cyber security threats. Whether you need to rework your security architecture, improve performance, and/or deal with new threats, this webinar has you covered. What methods and architectures you should consider to proactively protect your data.
With the core architectural backbone of the airlines gen AI roadmap in place, including United Data Hub and an AI and ML platform dubbed Mars, Birnbaum has released a handful of models into production use for employees and customers alike. CIO Jason Birnbaum has ambitious plans for generative AI at United Airlines.
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Plus, they can be more easily trained on a companys own data, so Upwork is starting to embrace this shift, training its own small language models on more than 20 years of interactions and behaviors on its platform. Agents can be more loosely coupled than services, making these architectures more flexible, resilient and smart.
Jayesh Chaurasia, analyst, and Sudha Maheshwari, VP and research director, wrote in a blog post that businesses were drawn to AI implementations via the allure of quick wins and immediate ROI, but that led many to overlook the need for a comprehensive, long-term business strategy and effective data management practices.
From understanding its distributed architecture to unlocking its incredible power for industries like healthcare, finance, retail and more, experience how Cassandra® can transform your entire data operations.
To keep up, IT must be able to rapidly design and deliver application architectures that not only meet the business needs of the company but also meet data recovery and compliance mandates. Moving applications between data center, edge, and cloud environments is no simple task.
This architecture leads to the slow performance Python developers know too well, where simple operations like creating a virtual environment or installing packages can take seconds or even minutes for complex projects. A hard link is a filesystem feature where multiple directory entries point to the same underlying data blocks on disk.
Design tokens are fundamental design decisions represented as data. Andreas Kutschmann explains how they work and how to organize them to balance scalability, maintainability and developer experience.
The reasons include higher than expected costs, but also performance and latency issues; security, data privacy, and compliance concerns; and regional digital sovereignty regulations that affect where data can be located, transported, and processed. So we carefully manage our data lifecycle to minimize transfers between clouds.
Apache Cassandra is an open-source distributed database that boasts an architecture that delivers high scalability, near 100% availability, and powerful read-and-write performance required for many data-heavy use cases.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content