This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 During the training of Llama 3.1
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
The Pro tier, however, would require a highly customized LLM that has been trained on specific data and terminology, enabling it to assist with intricate tasks like drafting complex legal documents. This architecture workflow includes the following steps: A user submits a question through a web or mobile application. 70B and 8B.
Training large language models (LLMs) models has become a significant expense for businesses. PEFT is a set of techniques designed to adapt pre-trained LLMs to specific tasks while minimizing the number of parameters that need to be updated.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
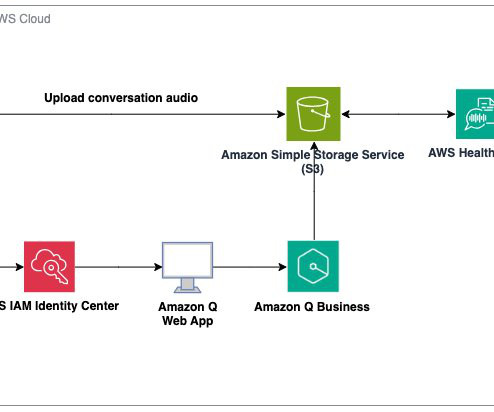
During re:Invent 2023, we launched AWS HealthScribe , a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures.
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Hes seeing the need for professionals who can not only navigate the technology itself, but also manage increasing complexities around its surrounding architectures, data sets, infrastructure, applications, and overall security. Or bring in a consulting company that can help you build and train at the same time, he adds.
The following diagram illustrates the solution architecture: The steps of the solution include: Upload data to Amazon S3 : Store the product images in Amazon Simple Storage Service (Amazon S3). The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3.
It prevents vendor lock-in, gives a lever for strong negotiation, enables business flexibility in strategy execution owing to complicated architecture or regional limitations in terms of security and legal compliance if and when they rise and promotes portability from an application architecture perspective.
These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is a complex and resource-intensive process, often requiring specialized expertise and significant computational resources.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. These potential vulnerabilities could be exploited by adversaries through various threat vectors.
Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources. Unlike fine-tuning, in RAG, the model doesnt undergo any training and the model weights arent updated to learn the domain knowledge.
This advancement makes sophisticated agent architectures more accessible and economically viable across a broader range of applications and scales of deployment. We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information.
We will deep dive into the MCP architecture later in this post. Using a client-server architecture (as illustrated in the following screenshot), MCP helps developers expose their data through lightweight MCP servers while building AI applications as MCP clients that connect to these servers.
Plus, they can be more easily trained on a companys own data, so Upwork is starting to embrace this shift, training its own small language models on more than 20 years of interactions and behaviors on its platform. Agents can be more loosely coupled than services, making these architectures more flexible, resilient and smart.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. Nemotron-4 15B, with its impressive 15-billion-parameter architecturetrained on 8 trillion text tokens, brings powerful multilingual and coding capabilities to the Amazon Bedrock.
Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others. These recipes are processed through the HyperPod recipe launcher, which serves as the orchestration layer responsible for launching a job on the corresponding architecture.
The Education and Training Quality Authority (BQA) plays a critical role in improving the quality of education and training services in the Kingdom Bahrain. BQA oversees a comprehensive quality assurance process, which includes setting performance standards and conducting objective reviews of education and training institutions.
The result was a compromised availability architecture. For example, the database team we worked with in an organization new to the cloud launched all the AWS RDS database servers from dev through production, incurring a $600K a month cloud bill nine months before the scheduled production launch. Long-term value creation.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. The following diagram provides a detailed view of the architecture to enhance email support using generative AI.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. 8B ) and DeepSeek-R1-Distill-Llama-70B (from base model Llama-3.3-70B-Instruct
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone.
Organizations must decide on their hosting provider, whether it be an on-prem setup, cloud solutions like AWS, GCP, Azure or specialized data platform providers such as Snowflake and Databricks. Not my original quote, but a cardinal sin of cloud-native data architecture is copying data from one location to another.
LoRA is a technique for efficiently adapting large pre-trained language models to new tasks or domains by introducing small trainable weight matrices, called adapters, within each linear layer of the pre-trained model. Why LoRAX for LoRA deployment on AWS? The following diagram is the solution architecture.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider.
A generative pre-trained transformer (GPT) uses causal autoregressive updates to make prediction. Variety of tasks such as speech recognition, text generation, and question answering are demonstrated to have stupendous performance by these model architectures. Both are decoder models following similar architectural design as Chat GPT3.
Enterprise architecture definition Enterprise architecture (EA) is the practice of analyzing, designing, planning, and implementing enterprise analysis to successfully execute on business strategies. Making it easier to evaluate existing architecture against long-term goals.
Large organizations often have many business units with multiple lines of business (LOBs), with a central governing entity, and typically use AWS Organizations with an Amazon Web Services (AWS) multi-account strategy. In this post, we evaluate different generative AI operating model architectures that could be adopted.
This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
For instance, Capital One successfully transitioned from mainframe systems to a cloud-first strategy by gradually migrating critical applications to Amazon Web Services (AWS). It adopted a microservices architecture to decouple legacy components, allowing for incremental updates without disrupting the entire system.
Llama2 by Meta is an example of an LLM offered by AWS. Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. It comes in a range of parameter sizes—7 billion, 13 billion, and 70 billion—as well as pre-trained and fine-tuned variations.
A key component of this expansion is the introduction of Hyperforce, Salesforces next-generation platform architecture, to Saudi Arabia. Delivered in partnership with Amazon Web Services (AWS), Hyperforce will enable Salesforce customers to run workloads locally while adhering to regulatory requirements.
We discuss the unique challenges MaestroQA overcame and how they use AWS to build new features, drive customer insights, and improve operational inefficiencies. MaestroQA integrated Amazon Bedrock into their existing architecture using Amazon Elastic Container Service (Amazon ECS).
This post will discuss agentic AI driven architecture and ways of implementing. Agentic AI architecture Agentic AI architecture is a shift in process automation through autonomous agents towards the capabilities of AI, with the purpose of imitating cognitive abilities and enhancing the actions of traditional autonomous agents.
Its improved architecture, based on the Multimodal Diffusion Transformer (MMDiT), combines multiple pre-trained text encoders for enhanced text understanding and uses QK-normalization to improve training stability. Use the us-west-2 AWS Region to run this demo. An Amazon SageMaker domain. Access to Stability AIs SD3.5
Amazon Web Services (AWS) is committed to supporting the development of cutting-edge generative artificial intelligence (AI) technologies by companies and organizations across the globe. Let’s dive in and explore how these organizations are transforming what’s possible with generative AI on AWS.
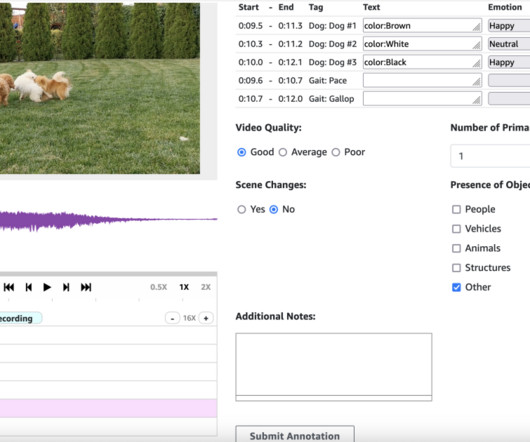
As large language models (LLMs) increasingly integrate more multimedia capabilities, human feedback becomes even more critical in training them to generate rich, multi-modal content that aligns with human quality standards. The path to creating effective AI models for audio and video generation presents several distinct challenges.
For medium to large businesses with outdated systems or on-premises infrastructure, transitioning to AWS can revolutionize their IT operations and enhance their capacity to respond to evolving market needs. AWS migration isnt just about moving data; it requires careful planning and execution. Need to hire skilled engineers?
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced large language model (LLM) distinguished by its innovative, multi-stage training process. Instead of relying solely on traditional pre-training and fine-tuning, DeepSeek-R1 integrates reinforcement learning to achieve more refined outputs.
Cross-Region inference enables seamless management of unplanned traffic bursts by using compute across different AWS Regions. Amazon Bedrock Data Automation optimizes for available AWS Regional capacity by automatically routing across regions within the same geographic area to maximize throughput at no additional cost.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content