This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Region Evacuation with static anycast IP approach Welcome back to our comprehensive "Building Resilient Public Networking on AWS" blog series, where we delve into advanced networking strategies for regional evacuation, failover, and robust disaster recovery. Find the detailed guide here.
However, this method presents trade-offs. However, it also presents some trade-offs. Implementation of dynamic routing In this section, we explore different approaches to implementing dynamic routing on AWS, covering both built-in routing features and custom solutions that you can use as a starting point to build your own.
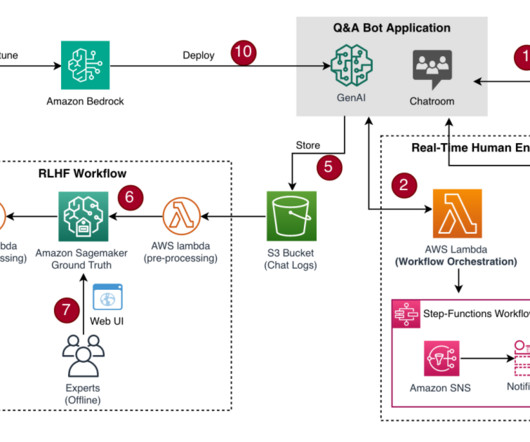
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
During re:Invent 2023, we launched AWS HealthScribe , a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation.
Recognizing this need, we have developed a Chrome extension that harnesses the power of AWS AI and generative AI services, including Amazon Bedrock , an AWS managed service to build and scale generative AI applications with foundation models (FMs). The following diagram illustrates the architecture of the application.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures.
In addition to cost, performing fine tuning for LLMs at scale presents significant technical challenges. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. To learn more about Trainium chips and the Neuron SDK, see Welcome to AWS Neuron.
However, as companies expand their operations and adopt multi-cloud architectures, they are faced with an invisible but powerful challenge: Data gravity. This gravitational effect presents a paradox for IT leaders. The adoption of cloud-native architectures further mitigates the impact of data gravity.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. In the following sections, we explain how to deploy this architecture.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
The device further processes this response, including text-to-speech (TTS) conversion for voice agents, before presenting it to the user. AWS Local Zones are a type of edge infrastructure deployment that places select AWS services close to large population and industry centers. Next, create a subnet inside each Local Zone.
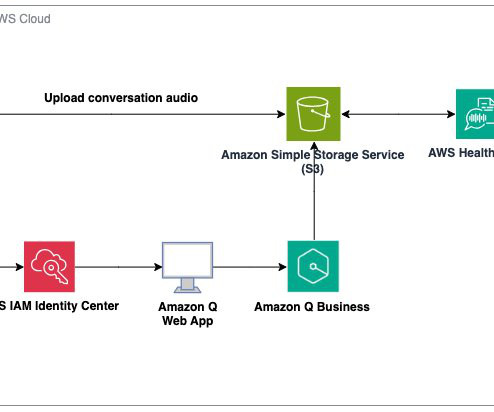
This post presents a solution where you can upload a recording of your meeting (a feature available in most modern digital communication services such as Amazon Chime ) to a centralized video insights and summarization engine. You can invoke Lambda functions from over 200 AWS services and software-as-a-service (SaaS) applications.
Here's a theory I have about cloud vendors (AWS, Azure, GCP): Cloud vendors 1 will increasingly focus on the lowest layers in the stack: basically leasing capacity in their data centers through an API. Redshift is a data warehouse (aka OLAP database) offered by AWS. If you're an ambitious person, do you go work at AWS?
Approach and base model overview In this section, we discuss the differences between a fine-tuning and RAG approach, present common use cases for each approach, and provide an overview of the base model used for experiments. The following diagram illustrates the solution architecture.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. The following diagram illustrates the conceptual architecture of an AI assistant with Amazon Bedrock IDE.
The failed instance also needs to be isolated and terminated manually, either through the AWS Management Console , AWS Command Line Interface (AWS CLI), or tools like kubectl or eksctl. About the Authors Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. This innovative service goes beyond traditional trip planning methods, offering real-time interaction through a chat-based interface and maintaining scalability, reliability, and data security through AWS native services.
Although these advancements offer remarkable capabilities, they also present significant challenges. In a transformer architecture, such layers are the embedding layers and the multilayer perceptron (MLP) layers. and prior Llama models) and Mistral model architectures for context parallelism. supports the Llama 3.1 (and
The collaboration between BQA and AWS was facilitated through the Cloud Innovation Center (CIC) program, a joint initiative by AWS, Tamkeen , and leading universities in Bahrain, including Bahrain Polytechnic and University of Bahrain. The following diagram illustrates the solution architecture.
However, using generative AI models in enterprise environments presents unique challenges. Why LoRAX for LoRA deployment on AWS? The surge in popularity of fine-tuning LLMs has given rise to multiple inference container methods for deploying LoRA adapters on AWS. The following diagram is the solution architecture.
Amazon Web Services (AWS) is committed to supporting the development of cutting-edge generative artificial intelligence (AI) technologies by companies and organizations across the globe. Let’s dive in and explore how these organizations are transforming what’s possible with generative AI on AWS.
VPC Lattice offers a new mechanism to connect microservices across AWS accounts and across VPCs in a developer-friendly way. Or if you have an existing landing zone with AWS Transit Gateway, do you already plan to replace it with VPC Lattice? You can also use AWS PrivateLink to inter-connect your VPCs across accounts.
As many of you may have read, Amazon has released C7g instances powered by the highly anticipated AWS Graviton3 Processors. Based on the success we had with this experiment (don’t worry, we discuss it below) we can only expect great things to come out of the new AWS Graviton3 Processors. Background. Reservations[]|.Instances[]'
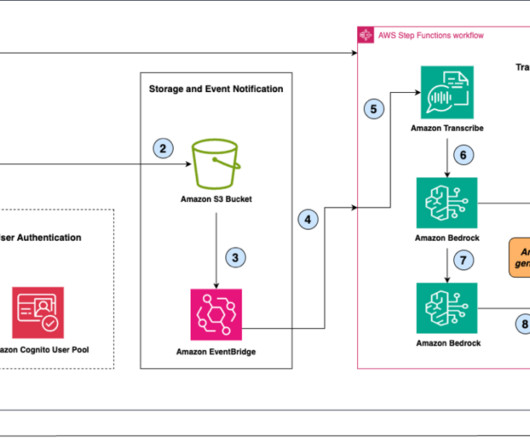
We explain the end-to-end solution workflow, the prompts needed to produce the transcript and perform security analysis, and provide a deployable solution architecture. This architecture can be used for demonstration purposes and testing with your own video recordings and prompts; however, it is not suitable for a production use.
In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWS AI and generative AI services to provide a framework to streamline video extraction and evaluation processes. This solution, powered by AWS AI and generative AI services, meets these needs.
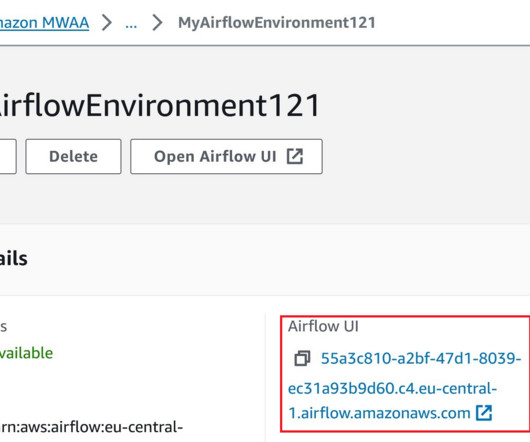
Tenable Research discovered a one-click account takeover vulnerability in the AWS Managed Workflows Apache Airflow service that could have allowed full takeover of a victim’s web management panel of the Airflow instance. By abusing the vulnerability, an attacker could have forced victims to use and authenticate the attacker’s known session.
Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others. These recipes are processed through the HyperPod recipe launcher, which serves as the orchestration layer responsible for launching a job on the corresponding architecture.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. Prospecting, opportunity progression, and customer engagement present exciting opportunities to utilize generative AI, using historical data, to drive efficiency and effectiveness.
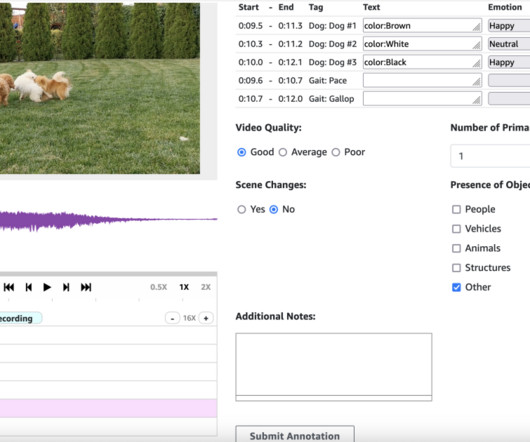
The path to creating effective AI models for audio and video generation presents several distinct challenges. We guide you through deploying the necessary infrastructure using AWS CloudFormation , creating an internal labeling workforce, and setting up your first labeling job. We demonstrate how to use Wavesurfer.js
These reports can be presented to clinical trial teams, regulatory bodies, and safety monitoring committees, supporting informed decision-making processes. Insights and reporting The processed data and insights derived from the LLM are presented through interactive dashboards, visualizations, and reports. An AWS account.
{{interview_audio_title}} 00:00 00:00 Volume Slider 10s 10s 10s 10s Seek Slider The genesis of cloud computing can be traced back to the 1960s concept of utility computing, but it came into its own with the launch of Amazon Web Services (AWS) in 2006. As a result, another crucial misconception revolves around the shared responsibility model.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The AI-native technology stack illustrated in the architecture diagram has two key components: Cohere language models and a Weaviate vector database.
Mistral developed a novel architecture for Pixtral 12B, optimized for both computational efficiency and performance. This architecture supports processing an arbitrary number of images of varying sizes within a large context window of 128k tokens. For more Mistral resources on AWS, check out the GitHub repo.
We use various AWS services to deploy a complete solution that you can use to interact with an API providing real-time weather information. In this post, we present a streamlined approach to deploying an AI-powered agent by combining Amazon Bedrock Agents and a foundation model (FM). In this solution, we use Amazon Bedrock Agents.
The Mozart application rapidly compares policy documents and presents comprehensive change details, such as descriptions, locations, excerpts, in a tracked change format. In this post, we describe the development journey of the generative AI companion for Mozart, the data, the architecture, and the evaluation of the pipeline.
You can access the model through the Image Playground on the AWS Management Console for Amazon Bedrock, or through APIs. Architectural lighting. Architectural design A white cubic house with floor-to-ceiling windows, interior view from living room. Ultra-wide architectural lens. Strong shadow play. Minimal composition.
Model Variants The current DeepSeek model collection consists of the following models: DeepSeek-V3 An LLM that uses a Mixture-of-Experts (MoE) architecture. These models retain their existing architecture while gaining additional reasoning capabilities through a distillation process. GenAI Data Scientist at AWS.
In addition to Amazon Bedrock, you can use other AWS services like Amazon SageMaker JumpStart and Amazon Lex to create fully automated and easily adaptable generative AI order processing agents. In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda.
We present the solution and provide an example by simulating a case where the tier one AWS experts are notified to help customers using a chat-bot. We provide LangChain and AWS SDK code-snippets, architecture and discussions to guide you on this important topic.
Public speaking is a critical skill in today’s world, whether it’s for professional presentations, academic settings, or personal growth. Using LLMs trained on extensive data, Amazon Bedrock generates curated speech outputs to enhance the presentation delivery. The following diagram shows our solution architecture.
One of the most common questions people ask us is, “Do I need to have an IT background to start using AWS?” Knowing how networking works, and being familiar with the client-server model will help you understand the ins and outs of AWS, but what if you need something even more basic than that? AWS in non-technical terms.
But managing multicloud environments presents unique challenges, especially when it comes to the interoperability and workload-fluidity issues at the center of more deliberate — rather than happenstance — multicloud strategies. Tiffany further explains that multicloud is generally just a more complicated form of hybrid cloud.
IoT architecture layers. The list of top five fully-fledged solutions in alphabetical order is as follows : Amazon Web Service (AWS) IoT platform , Cisco IoT , Google Cloud IoT , IBM Watson IoT platform , and. AWS IoT Platform: the best place to build smart cities. AWS IoT infrastructure. Source: AWS. AWS IoT Core.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content