This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Region Evacuation with static anycast IP approach Welcome back to our comprehensive "Building Resilient Public Networking on AWS" blog series, where we delve into advanced networking strategies for regional evacuation, failover, and robust disaster recovery. Find the detailed guide here.
The built-in elasticity in serverless computing architecture makes it particularly appealing for unpredictable workloads and amplifies developers productivity by letting developers focus on writing code and optimizing application design industry benchmarks , providing additional justification for this hypothesis. Architecture complexity.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures.
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Particularly well-suited for microservice-oriented architectures and agile workflows, containers help organizations improve developer efficiency, feature velocity, and optimization of resources. Key metrics to monitor when leveraging two container orchestration systems.
David Copland, from QARC, and Scott Harding, a person living with aphasia, used AWS services to develop WordFinder, a mobile, cloud-based solution that helps individuals with aphasia increase their independence through the use of AWS generative AI technology. The following diagram illustrates the solution architecture on AWS.
The following diagram illustrates the solution architecture: The steps of the solution include: Upload data to Amazon S3 : Store the product images in Amazon Simple Storage Service (Amazon S3). The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Security – The solution uses AWS services and adheres to AWS Cloud Security best practices so your data remains within your AWS account.
The result was a compromised availability architecture. For example, the database team we worked with in an organization new to the cloud launched all the AWS RDS database servers from dev through production, incurring a $600K a month cloud bill nine months before the scheduled production launch. Standardized metrics.
The general architecture of the metadata pipeline consists of two primary steps: Generate transcriptions of audio tracks: use speech recognition models to generate accurate transcripts of the audio content. Word information lost (WIL) – This metric quantifies the amount of information lost due to transcription errors.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. Review the model response and metrics provided.
Organizations can now label all Amazon Bedrock models with AWS cost allocation tags , aligning usage to specific organizational taxonomies such as cost centers, business units, and applications. By assigning AWS cost allocation tags, the organization can effectively monitor and track their Bedrock spend patterns.
It prevents vendor lock-in, gives a lever for strong negotiation, enables business flexibility in strategy execution owing to complicated architecture or regional limitations in terms of security and legal compliance if and when they rise and promotes portability from an application architecture perspective.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone.
As organizations continue to build out their digital architecture, a new category of enterprise software has emerged to help them manage that process. “Enterprise architecture today is very much about the scaffolding in the organization,” he said. This means that you can also then run, for example, scenario analysis.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform.
The collaboration between BQA and AWS was facilitated through the Cloud Innovation Center (CIC) program, a joint initiative by AWS, Tamkeen , and leading universities in Bahrain, including Bahrain Polytechnic and University of Bahrain. The following diagram illustrates the solution architecture.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. The following diagram illustrates the solution architecture.
We discuss the unique challenges MaestroQA overcame and how they use AWS to build new features, drive customer insights, and improve operational inefficiencies. MaestroQA integrated Amazon Bedrock into their existing architecture using Amazon Elastic Container Service (Amazon ECS).
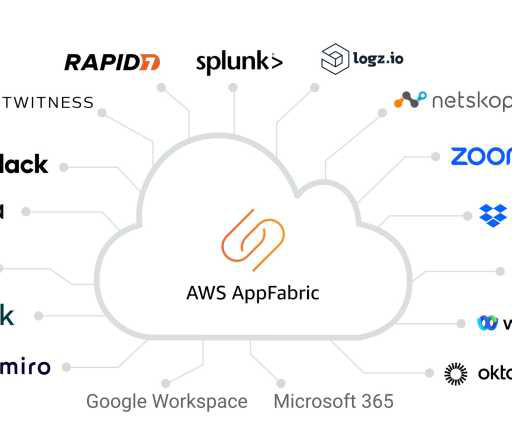
Amazon Web Services (AWS) on Tuesday unveiled a new no-code offering, dubbed AppFabric, designed to simplify SaaS integration for enterprises by increasing application observability and reducing operational costs associated with building point-to-point solutions. AppFabric, which is available across AWS’ US East (N.
Our partnership with AWS and our commitment to be early adopters of innovative technologies like Amazon Bedrock underscore our dedication to making advanced HCM technology accessible for businesses of any size. We are thrilled to partner with AWS on this groundbreaking generative AI project. John Canada, VP of Engineering at Asure.
This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers.
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
In the era of generative AI , new large language models (LLMs) are continually emerging, each with unique capabilities, architectures, and optimizations. In this post, we present an LLM migration paradigm and architecture, including a continuous process of model evaluation, prompt generation using Amazon Bedrock, and data-aware optimization.
Our proposed architecture provides a scalable and customizable solution for online LLM monitoring, enabling teams to tailor your monitoring solution to your specific use cases and requirements. Overview of solution The first thing to consider is that different metrics require different computation considerations.
Solution overview To evaluate the effectiveness of RAG compared to model customization, we designed a comprehensive testing framework using a set of AWS-specific questions. The following diagram illustrates the solution architecture. To do so, we create a knowledge base. For Job name , enter a name for the fine-tuning job.
Hameed and Qadeer developed Deep Vision’s architecture as part of a Ph.D. “They came up with a very compelling architecture for AI that minimizes data movement within the chip,” Annavajjhala explained. In addition, its software optimizes the overall data flow inside the architecture based on the specific workload.
Model Variants The current DeepSeek model collection consists of the following models: DeepSeek-V3 An LLM that uses a Mixture-of-Experts (MoE) architecture. These models retain their existing architecture while gaining additional reasoning capabilities through a distillation process. deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
Large organizations often have many business units with multiple lines of business (LOBs), with a central governing entity, and typically use AWS Organizations with an Amazon Web Services (AWS) multi-account strategy. In this post, we evaluate different generative AI operating model architectures that could be adopted.
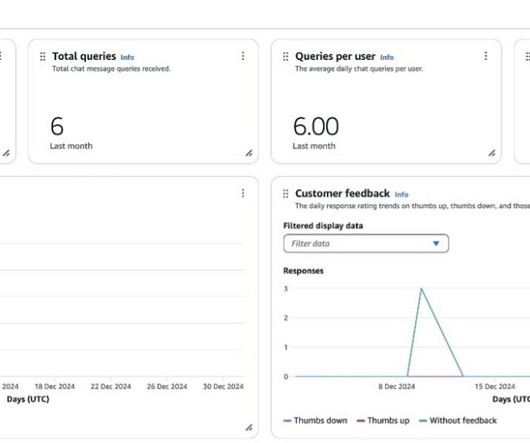
By monitoring utilization metrics, organizations can quantify the actual productivity gains achieved with Amazon Q Business. Tracking metrics such as time saved and number of queries resolved can provide tangible evidence of the services impact on overall workplace productivity.
This advancement makes sophisticated agent architectures more accessible and economically viable across a broader range of applications and scales of deployment. We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information.
Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others. These recipes are processed through the HyperPod recipe launcher, which serves as the orchestration layer responsible for launching a job on the corresponding architecture.
For medium to large businesses with outdated systems or on-premises infrastructure, transitioning to AWS can revolutionize their IT operations and enhance their capacity to respond to evolving market needs. AWS migration isnt just about moving data; it requires careful planning and execution. Need to hire skilled engineers?
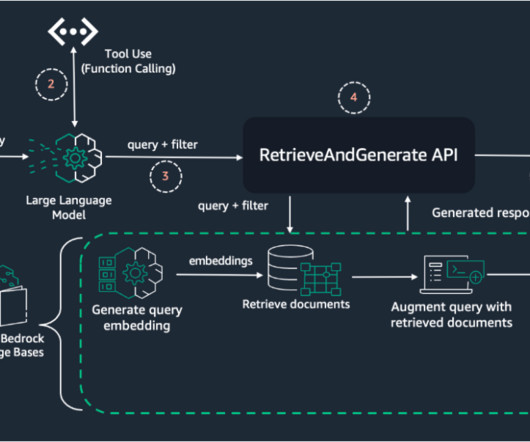
To evaluate the effectiveness of a RAG system, we focus on three key metrics: Answer relevancy – Measures how well the generated answer addresses the user’s query. By implementing dynamic metadata filtering, you can significantly improve these metrics, leading to more accurate and relevant RAG responses. model in Amazon Bedrock.
Two years ago, we shared our experiences with adopting AWS Graviton3 and our enthusiasm for the future of AWS Graviton and Arm. Once again, we’re privileged to share our experiences as a launch customer of the Amazon EC2 R8g instances powered by AWS Graviton4, the newest generation of AWS Graviton processors.
To assess system reliability, engineering teams often rely on key metrics such as mean time between failures (MTBF), which measures the average operational time between hardware failures and serves as a valuable indicator of system robustness.
Cross-Region inference enables seamless management of unplanned traffic bursts by using compute across different AWS Regions. Amazon Bedrock Data Automation optimizes for available AWS Regional capacity by automatically routing across regions within the same geographic area to maximize throughput at no additional cost.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. This innovative service goes beyond traditional trip planning methods, offering real-time interaction through a chat-based interface and maintaining scalability, reliability, and data security through AWS native services.
In this post, we describe the development journey of the generative AI companion for Mozart, the data, the architecture, and the evaluation of the pipeline. The following diagram illustrates the solution architecture. Data: Policy forms Mozart is designed to author policy forms like coverage and endorsements.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. AWS Prototyping developed an AWS Cloud Development Kit (AWS CDK) stack for deployment following AWS best practices.
Mistral developed a novel architecture for Pixtral 12B, optimized for both computational efficiency and performance. This architecture supports processing an arbitrary number of images of varying sizes within a large context window of 128k tokens. For more Mistral resources on AWS, check out the GitHub repo.
DeepSeek-R1 uses a Mixture of Experts (MoE) architecture and is 671 billion parameters in size. The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. For details, refer to Create an AWS account.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content