This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machinelearning. Choose the us-east-1 AWS Region from the top right corner. Choose Manage model access.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
Implementation of dynamic routing In this section, we explore different approaches to implementing dynamic routing on AWS, covering both built-in routing features and custom solutions that you can use as a starting point to build your own. The architecture of this system is illustrated in the following figure. 70B and 8B.
With rapid progress in the fields of machinelearning (ML) and artificial intelligence (AI), it is important to deploy the AI/ML model efficiently in production environments. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
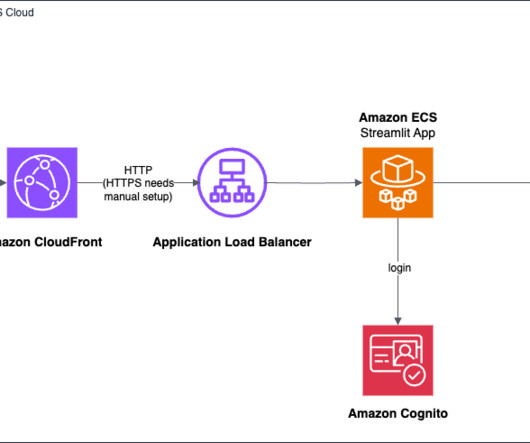
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures.
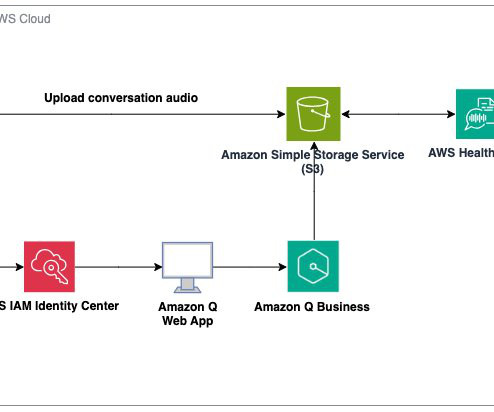
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. AWS HealthScribe combines speech recognition and generative AI trained specifically for healthcare documentation to accelerate clinical documentation and enhance the consultation experience.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. Predicting protein structures.
invoke(input_text=Convert 11am from NYC time to London time) We showcase an example of building an agent to understand your Amazon Web Service (AWS) spend by connecting to AWS Cost Explorer , Amazon CloudWatch , and Perplexity AI through MCP. This gives you an AI agent that can transform the way you manage your AWS spend.
Recognizing this need, we have developed a Chrome extension that harnesses the power of AWS AI and generative AI services, including Amazon Bedrock , an AWS managed service to build and scale generative AI applications with foundation models (FMs). The following diagram illustrates the architecture of the application.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. You can also customize your distributed training.
In continuation of its efforts to help enterprises migrate to the cloud, Oracle said it is partnering with Amazon Web Services (AWS) to offer database services on the latter’s infrastructure. Oracle Database@AWS is expected to be available in preview later in the year with broader availability expected in 2025.
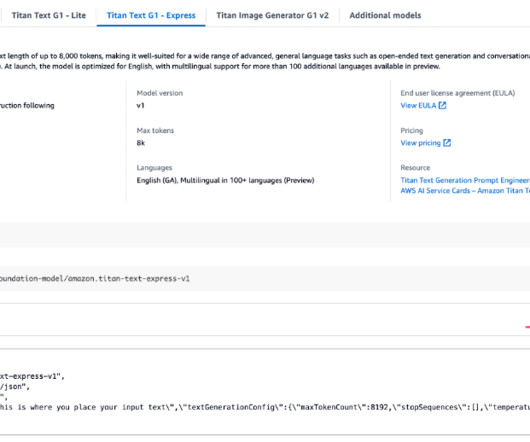
Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3. If enabled, its status will display as Access granted.
Built on top of EXLerate.AI, EXLs AI orchestration platform, and Amazon Web Services (AWS), Code Harbor eliminates redundant code and optimizes performance, reducing manual assessment, conversion and testing effort by 60% to 80%. The EXLerate.AI
Prerequisites Before you dive into the integration process, make sure you have the following prerequisites in place: AWS account – You’ll need an AWS account to access and use Amazon Bedrock. You can interact with Amazon Bedrock using AWS SDKs available in Python, Java, Node.js, and more.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. In the following sections, we explain how to deploy this architecture.
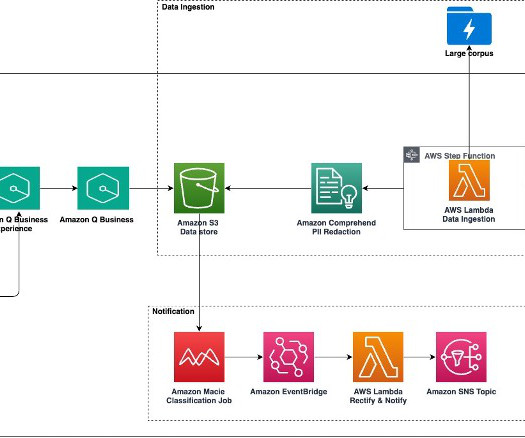
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider.
This engine uses artificial intelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
The failed instance also needs to be isolated and terminated manually, either through the AWS Management Console , AWS Command Line Interface (AWS CLI), or tools like kubectl or eksctl. About the Authors Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference.
Digital transformation started creating a digital presence of everything we do in our lives, and artificial intelligence (AI) and machinelearning (ML) advancements in the past decade dramatically altered the data landscape. The choice of vendors should align with the broader cloud or on-premises strategy.
Amazon Bedrock cross-Region inference capability that provides organizations with flexibility to access foundation models (FMs) across AWS Regions while maintaining optimal performance and availability. We provide practical examples for both SCP modifications and AWS Control Tower implementations.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. Nemotron-4 15B, with its impressive 15-billion-parameter architecture trained on 8 trillion text tokens, brings powerful multilingual and coding capabilities to the Amazon Bedrock. About the authors James Park is a Solutions Architect at Amazon Web Services.
The computer use agent demo powered by Amazon Bedrock Agents provides the following benefits: Secure execution environment Execution of computer use tools in a sandbox environment with limited access to the AWS ecosystem and the web. The following diagram illustrates the solution architecture. AWS CDK CLI, follow instructions here.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services. versions, catering to different programming preferences.
Its improved architecture, based on the Multimodal Diffusion Transformer (MMDiT), combines multiple pre-trained text encoders for enhanced text understanding and uses QK-normalization to improve training stability. Use the us-west-2 AWS Region to run this demo. An Amazon SageMaker domain. Access to Stability AIs SD3.5
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. 8B ) and DeepSeek-R1-Distill-Llama-70B (from base model Llama-3.3-70B-Instruct
AWS App Studio is a generative AI-powered service that uses natural language to build business applications, empowering a new set of builders to create applications in minutes. Cross-instance Import and Export Enabling straightforward and self-service migration of App Studio applications across AWS Regions and AWS accounts.
Solution overview To evaluate the effectiveness of RAG compared to model customization, we designed a comprehensive testing framework using a set of AWS-specific questions. The following diagram illustrates the solution architecture. At the time of writing, Amazon Nova model fine-tuning is exclusively available in us-east-1.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. This innovative service goes beyond traditional trip planning methods, offering real-time interaction through a chat-based interface and maintaining scalability, reliability, and data security through AWS native services.
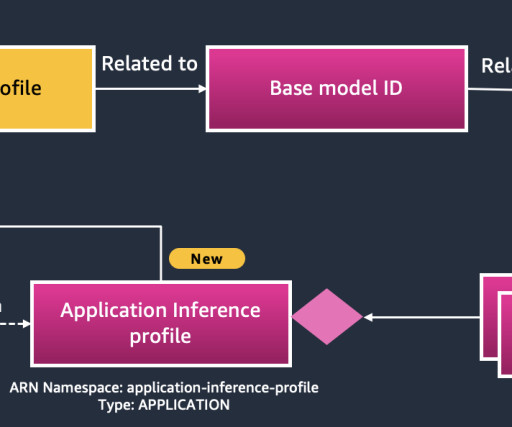
Organizations can now label all Amazon Bedrock models with AWS cost allocation tags , aligning usage to specific organizational taxonomies such as cost centers, business units, and applications. By assigning AWS cost allocation tags, the organization can effectively monitor and track their Bedrock spend patterns.
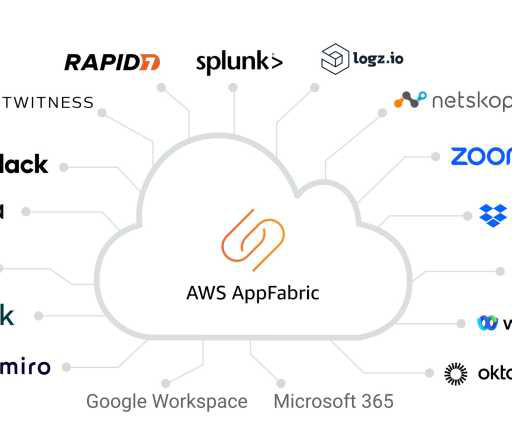
Amazon Web Services (AWS) on Tuesday unveiled a new no-code offering, dubbed AppFabric, designed to simplify SaaS integration for enterprises by increasing application observability and reducing operational costs associated with building point-to-point solutions. AppFabric, which is available across AWS’ US East (N.
Seamless integration of latest foundation models (FMs), Prompts, Agents, Knowledge Bases, Guardrails, and other AWS services. Prerequisites Before implementing the new capabilities, make sure that you have the following: An AWS account In Amazon Bedrock: Create and test your base prompts for customer service interactions in Prompt Management.
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. Cross-Region inference enables seamless management of unplanned traffic bursts by using compute across different AWS Regions.
In a transformer architecture, such layers are the embedding layers and the multilayer perceptron (MLP) layers. and prior Llama models) and Mistral model architectures for context parallelism. Delving deeper into FP8’s architecture, we discover two distinct subtypes: E4M3 and E5M2. supports the Llama 3.1 (and
The general architecture of the metadata pipeline consists of two primary steps: Generate transcriptions of audio tracks: use speech recognition models to generate accurate transcripts of the audio content. Tom Lauwers is a machinelearning engineer on the video personalization team for DPG Media.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
Enterprise architecture definition Enterprise architecture (EA) is the practice of analyzing, designing, planning, and implementing enterprise analysis to successfully execute on business strategies. Making it easier to evaluate existing architecture against long-term goals.
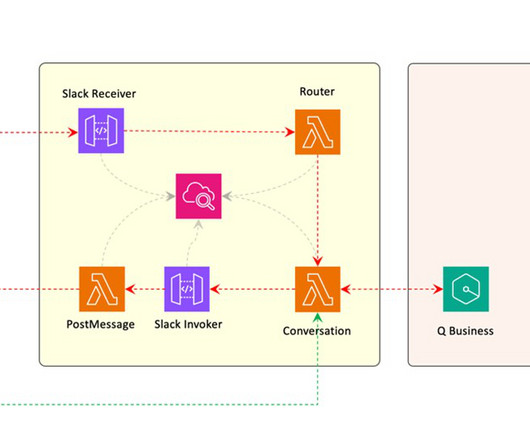
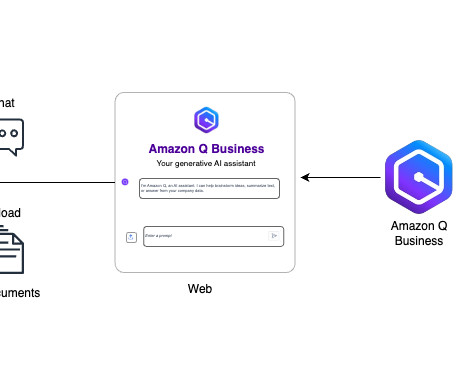
Amazon Q Business as a web experience makes AWS best practices readily accessible, providing cloud-centered recommendations quickly and making it straightforward to access AWS service functions, limits, and implementations. This post covers how to integrate Amazon Q Business into your enterprise setup.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone.
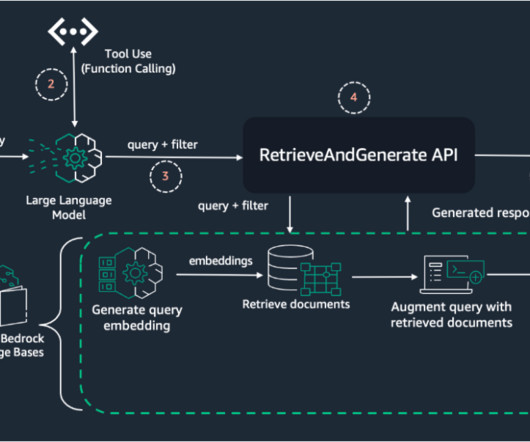
The following diagram illustrates high level RAG architecture with dynamic metadata filtering. This architecture uses the power of tool use for intelligent metadata extraction from a user’s query, combined with the robust RAG capabilities of Amazon Bedrock Knowledge Bases. Finally, the generated response is returned to the user.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content