This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
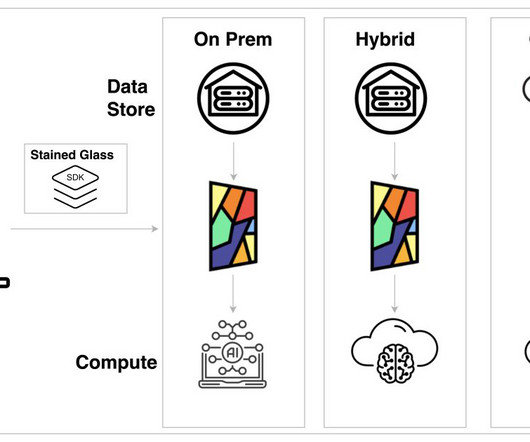
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud storage.
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
Whether it’s a financial services firm looking to build a personalized virtual assistant or an insurance company in need of ML models capable of identifying potential fraud, artificialintelligence (AI) is primed to transform nearly every industry.
All industries and modern applications are undergoing rapid transformation powered by advances in accelerated computing, deep learning, and artificialintelligence. The next phase of this transformation requires an intelligent data infrastructure that can bring AI closer to enterprise data.
Imagine, for example, asking an LLM which Amazon S3 storage buckets or Azure storage accounts contain data that is publicly accessible, then change their access settings? Or having an LLM identify documents in an Amazon DynamoDB database that havent been updated in over a year and delete or archive them.
LargeLanguageModels (LLMs) have revolutionized the field of natural language processing (NLP), improving tasks such as language translation, text summarization, and sentiment analysis. Monitoring the performance and behavior of LLMs is a critical task for ensuring their safety and effectiveness.
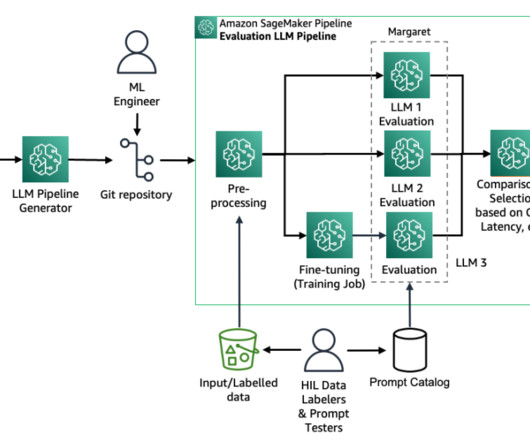
Out-of-the-box models often lack the specific knowledge required for certain domains or organizational terminologies. To address this, businesses are turning to custom fine-tuned models, also known as domain-specific largelanguagemodels (LLMs). The following diagram is the solution architecture.
National Laboratory has implemented an AI-driven document processing platform that integrates named entity recognition (NER) and largelanguagemodels (LLMs) on Amazon SageMaker AI. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
Digital tools are the lifeblood of todays enterprises, but the complexity of hybrid cloud architectures, involving thousands of containers, microservices and applications, frustratesoperational leaders trying to optimize business outcomes. Artificialintelligence has contributed to complexity.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. ” Generating DNA sequences.
Architecture The following figure shows the architecture of the solution. Through natural language processing algorithms and machinelearning techniques, the largelanguagemodel (LLM) analyzes the user’s queries in real time, extracting relevant context and intent to deliver tailored responses.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced largelanguagemodel (LLM) distinguished by its innovative, multi-stage training process. Instead of relying solely on traditional pre-training and fine-tuning, DeepSeek-R1 integrates reinforcement learning to achieve more refined outputs.
The introduction of Amazon Nova models represent a significant advancement in the field of AI, offering new opportunities for largelanguagemodel (LLM) optimization. In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline.
Largelanguagemodels (LLMs) have witnessed an unprecedented surge in popularity, with customers increasingly using publicly available models such as Llama, Stable Diffusion, and Mistral. With activations being partitioned along the sequence dimension, we need to consider how our model’s computations are affected.
With advancement in AI technology, the time is right to address such complexities with largelanguagemodels (LLMs). Amazon Bedrock has helped democratize access to LLMs, which have been challenging to host and manage. The following diagram illustrates the architecture using AWS services.
This engine uses artificialintelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. He helps support large enterprise customers at AWS and is part of the MachineLearning TFC.
From delightful consumer experiences to attacking fuel costs and carbon emissions in the global supply chain, real-time data and machinelearning (ML) work together to power apps that change industries. Data architecture coherence. more machinelearning use casesacross the company.
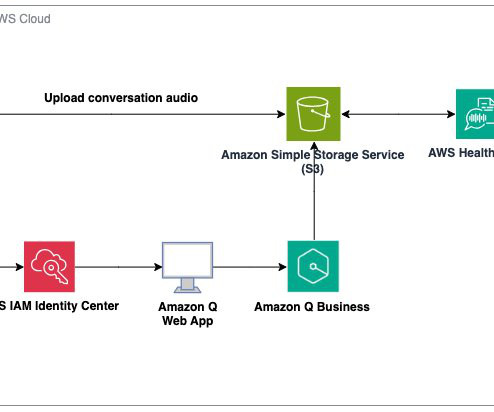
This is where the integration of cutting-edge technologies, such as audio-to-text translation and largelanguagemodels (LLMs), holds the potential to revolutionize the way patients receive, process, and act on vital medical information. These insights can include: Potential adverse event detection and reporting.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. The solution incorporates the following key features: Using a Retrieval Augmented Generation (RAG) architecture, the system generates a context-aware detailed assessment.
Their DeepSeek-R1 models represent a family of largelanguagemodels (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. The resulting distilled models, such as DeepSeek-R1-Distill-Llama-8B (from base model Llama-3.1-8B
This need for customization has become even more pronounced with the emergence of new models, such as those released by DeepSeek. However, customizing DeepSeek models effectively while managing computational resources remains a significant challenge. You can run these recipes using SageMaker HyperPod or as SageMaker training jobs.
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. It doesn’t retain audio or output text, and users have control over data storage with encryption in transit and at rest. This can lead to more personalized and effective care.
This application allows users to ask questions in natural language and then generates a SQL query for the users request. Largelanguagemodels (LLMs) are trained to generate accurate SQL queries for natural language instructions. However, off-the-shelf LLMs cant be used without some modification.
There are organizations who spend $1 million plus per year on LLM calls, Ricky wrote. Agent ops is a critical capability think Python SDKs for agent monitoring, LLM cost tracking, benchmarking, to gain visibility into API calls, real-time cost management, and reliability scores for agents in production.
You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures. Prompt catalog – Crafting effective prompts is important for guiding largelanguagemodels (LLMs) to generate the desired outputs. It’s serverless so you don’t have to manage the infrastructure.
Introduction to Multiclass Text Classification with LLMs Multiclass text classification (MTC) is a natural language processing (NLP) task where text is categorized into multiple predefined categories or classes. Traditional approaches rely on training machinelearningmodels, requiring labeled data and iterative fine-tuning.
It prevents vendor lock-in, gives a lever for strong negotiation, enables business flexibility in strategy execution owing to complicated architecture or regional limitations in terms of security and legal compliance if and when they rise and promotes portability from an application architecture perspective.
New and powerful largelanguagemodels (LLMs) are changing businesses rapidly, improving efficiency and effectiveness for a variety of enterprise use cases. Speed is of the essence, and adoption of LLM technologies can make or break a business’s competitive advantage.
The solution integrates largelanguagemodels (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. It can be a local machine or a cloud instance.
Largelanguagemodels (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
Consolidating data and improving accessibility through tenanted access controls can typically deliver a 25-30% reduction in data storage expenses while driving more informed decisions. When evaluating options, prioritize platforms that facilitate data democratization through low-code or no-code architectures.
As more enterprises migrate to cloud-based architectures, they are also taking on more applications (because they can) and, as a result of that, more complex workloads and storage needs. Machinelearning and other artificialintelligence applications add even more complexity.
Training largelanguagemodels (LLMs) models has become a significant expense for businesses. For many use cases, companies are looking to use LLM foundation models (FM) with their domain-specific data. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
DeepSeek-R1 is a largelanguagemodel (LLM) developed by DeepSeek AI that uses reinforcement learning to enhance reasoning capabilities through a multi-stage training process from a DeepSeek-V3-Base foundation. DeepSeek-R1 uses a Mixture of Experts (MoE) architecture and is 671 billion parameters in size.
Traditionally, transforming raw data into actionable intelligence has demanded significant engineering effort. It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats.
CEOs and boards of directors are tasking their CIOs to enable artificialintelligence (AI) within the organization as rapidly as possible. The networking, compute, and storage needs not to mention power and cooling are significant, and market pressures require the assembly to happen quickly.
Organizations building and deploying AI applications, particularly those using largelanguagemodels (LLMs) with Retrieval Augmented Generation (RAG) systems, face a significant challenge: how to evaluate AI outputs effectively throughout the application lifecycle.
Data governance is rapidly rising on the priority lists of large companies that want to work with AI in a data-driven manner. In many companies, data is spread across different storage locations and platforms, thus, ensuring effective connections and governance is crucial. Poor data quality automatically results in poor decisions.
The use of a multi-agent system, rather than relying on a single largelanguagemodel (LLM) to handle all tasks, enables more focused and in-depth analysis in specialized areas. Furthermore, the systems modular architecture facilitates seamless maintenance, updates, and scalability.
Rather than pull away from big iron in the AI era, Big Blue is leaning into it, with plans in 2025 to release its next-generation Z mainframe , with a Telum II processor and Spyre AI Accelerator Card, positioned to run largelanguagemodels (LLMs) and machinelearningmodels for fraud detection and other use cases.
The flexible, scalable nature of AWS services makes it straightforward to continually refine the platform through improvements to the machinelearningmodels and addition of new features. The following diagram illustrates the Principal generative AI chatbot architecture with AWS services.
In this post, we describe the development journey of the generative AI companion for Mozart, the data, the architecture, and the evaluation of the pipeline. Solution overview The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage. The following diagram illustrates the solution architecture.
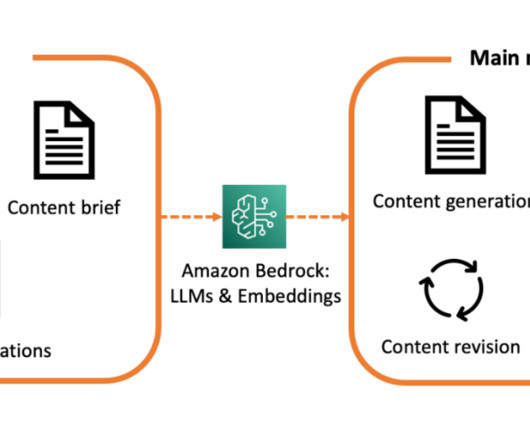
Generative AI and transformer-based largelanguagemodels (LLMs) have been in the top headlines recently. These models demonstrate impressive performance in question answering, text summarization, code, and text generation. Amazon Bedrock : to interact with supported LLMs and embedding models.
Artificialintelligence (AI) is the analytics vehicle that extracts data’s tremendous value and translates it into actionable, usable insights. In my role at Dell Technologies, I strive to help organizations advance the use of data, especially unstructured data, by democratizing the at-scale deployment of artificialintelligence (AI).
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content