This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From data masking technologies that ensure unparalleled privacy to cloud-native innovations driving scalability, these trends highlight how enterprises can balance innovation with accountability. Its ability to apply masking dynamically at the source or during data retrieval ensures both high performance and minimal disruptions to operations.
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Conclusion In this post, we’ve introduced a scalable and efficient solution for automating batch inference jobs in Amazon Bedrock. Access to your selected models hosted on Amazon Bedrock.
Agent Development Kit (ADK) The Agent Development Kit (ADK) is a game-changer for easily building sophisticated multi-agent applications. Native Multi-Agent Architecture: Build scalableapplications by composing specialized agents in a hierarchy. Built-in Evaluation: Systematically assess agent performance. BigFrames 2.0
Organizations are increasingly using multiple large language models (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements. In this post, we provide an overview of common multi-LLM applications.
Of course, the key as a senior leader is to understand what your organization needs, your application requirements, and to make choices that leverage the benefits of the right approach that fits the situation. How to make the right architectural choices given particular application patterns and risks.
Modern data architectures must be designed for security, and they must support data policies and access controls directly on the raw data, not in a web of downstream data stores and applications. Application programming interfaces. According to data platform Acceldata , there are three core principles of data architecture: Scalability.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. In this post, we set up the custom solution for observability and evaluation of Amazon Bedrock applications.
enterprise architects ensure systems are performing at their best, with mechanisms (e.g. tagging, component/application mapping, key metric collection) and tools incorporated to ensure data can be reported on sufficiently and efficiently without creating an industry in itself!
Small language models (SLMs) are giving CIOs greater opportunities to develop specialized, business-specific AI applications that are less expensive to run than those reliant on general-purpose large language models (LLMs). Microsofts Phi, and Googles Gemma SLMs. Googles Gemma 3, based on Gemini 2.0,
Think your customers will pay more for data visualizations in your application? Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Five years ago they may have. But today, dashboards and visualizations have become table stakes. Brought to you by Logi Analytics.
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machine learning.
The workflow includes the following steps: The process begins when a user sends a message through Google Chat, either in a direct message or in a chat space where the application is installed. After it’s authenticated, the request is forwarded to another Lambda function that contains our core application logic.
When addressed properly , application and platform modernization drives immense value and positions organizations ahead of their competition, says Anindeep Kar, a consultant with technology research and advisory firm ISG. The bad news, however, is that IT system modernization requires significant financial and time investments.
While many have performed this move, they still need professionals to stay on top of cloud services and manage large datasets. It enables developers to create consistent virtual environments to run applications, while also allowing them to create more scalable and secure applications via portable containers.
The gap between emerging technological capabilities and workforce skills is widening, and traditional approaches such as hiring specialized professionals or offering occasional training are no longer sufficient as they often lack the scalability and adaptability needed for long-term success.
Organizations building and deploying AI applications, particularly those using large language models (LLMs) with Retrieval Augmented Generation (RAG) systems, face a significant challenge: how to evaluate AI outputs effectively throughout the application lifecycle.
This alignment ensures that technology investments and projects directly contribute to achieving business goals, such as market expansion, product innovation, customer satisfaction, operational efficiency, and financial performance. Guiding principles Recognizing the core principles that drive business decisions is crucial for taking action.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. Building a generative AI application SageMaker Unified Studio offers tools to discover and build with generative AI.
Technology leaders in the financial services sector constantly struggle with the daily challenges of balancing cost, performance, and security the constant demand for high availability means that even a minor system outage could lead to significant financial and reputational losses. Scalability. Cost forecasting. Vendor lock-in.
All industries and modern applications are undergoing rapid transformation powered by advances in accelerated computing, deep learning, and artificial intelligence. Scalable data infrastructure As AI models become more complex, their computational requirements increase. Performance enhancements. Seamless data integration.
Structured frameworks such as the Stakeholder Value Model provide a method for evaluating how IT projects impact different stakeholders, while tools like the Business Model Canvas help map out how technology investments enhance value propositions, streamline operations, and improve financial performance.
Cost-performance optimizations via new chip One of the major updates announced last week was Googles seventh generation Tensor Processing Unit (TPU) chip Ironwood targeted at accelerating AI workloads, especially inferencing. Google is quietly redefining agent lifecycle management as it is destined to become the next DevOps frontier.
With demand for generative AI applications surging across projects and multiple lines of business, accurately allocating and tracking spend becomes more complex. Without a scalable approach to controlling costs, organizations risk unbudgeted usage and cost overruns.
In this blog post, we discuss how Prompt Optimization improves the performance of large language models (LLMs) for intelligent text processing task in Yuewen Group. To improve performance and efficiency, Yuewen Group transitioned to Anthropics Claude 3.5 In certain scenarios, the LLMs performance fell short of traditional NLP models.
Among other benefits, a hybrid cloud approach to mainframe modernization allows organizations to: Leverage cloud-native technologies which, in turn, help optimize workloads for performance and scalability. This integration enhances the overall efficiency of IT operations. Better leverage their mainframe data with near real-time access.
In the world of modern web development, creating scalable, efficient, and maintainable applications is a top priority for developers. and Redux have emerged as a powerful duo, transforming how developers approach building user interfaces and managing application state. Among the many tools and frameworks available, React.js
Facing increasing demand and complexity CIOs manage a complex portfolio spanning data centers, enterprise applications, edge computing, and mobile solutions, resulting in a surge of apps generating data that requires analysis. Enterprise IT struggles to keep up with siloed technologies while ensuring security, compliance, and cost management.
As the shine wears thin on generative AI and we transition into finding its best application, its more important than ever that CIOs and IT leaders ensure [they are] using AI in a point-specific way that drives business success, he says.
In todays fast-paced digital landscape, the cloud has emerged as a cornerstone of modern business infrastructure, offering unparalleled scalability, agility, and cost-efficiency. Technology modernization strategy : Evaluate the overall IT landscape through the lens of enterprise architecture and assess IT applications through a 7R framework.
Cloud providers have recognized the need to offer model inference through an API call, significantly streamlining the implementation of AI within applications. AWS Step Functions is a fully managed service that makes it easier to coordinate the components of distributed applications and microservices using visual workflows.
If so, youre already benefiting from a powerful, globally optimized platform designed for modern web applications. But did you know you can take your performance even further? Why Sitecore Developers Should Care Sitecore is a powerful digital experience platform, but ensuring smooth, high-speed performance at scale can be challenging.
Scalable infrastructure – Bedrock Marketplace offers configurable scalability through managed endpoints, allowing organizations to select their desired number of instances, choose appropriate instance types, define custom auto scaling policies that dynamically adjust to workload demands, and optimize costs while maintaining performance.
Determining their efficacy, safety, and value requires targeted, context-aware testing to ensure models perform reliably in real-world applications,” said David Talby, CEO, John Snow Labs. to Help Domain Experts Evaluate and Improve LLM Applications and Conduct HCC Coding Reviews appeared first on John Snow Labs.
The company says it can achieve PhD-level performance in challenging benchmark tests in physics, chemistry, and biology. Agents will begin replacing services Software has evolved from big, monolithic systems running on mainframes, to desktop apps, to distributed, service-based architectures, web applications, and mobile apps.
Why Vue Components Are Essential for Building Scalable UIs Components are a core feature of Vue.js, known for its simplicity and flexibility. They serve as the building blocks of Vue applications, enabling developers to break down the user interface into smaller, self-contained units. What Are Vue Components?
The imperative for APMR According to IDC’s Future Enterprise Resiliency and Spending Survey, Wave 1 (January 2024), 23% of organizations are shifting budgets toward GenAI projects, potentially overlooking the crucial role of application portfolio modernization and rationalization (APMR). Set relevant key performance indicators (KPIs).
AI-infused applications such as Microsoft Copilot + PCs are transforming the workforce by automating routine tasks and personalizing employee experiences. These issues can hinder AI scalability and limit its benefits. Key considerations include: Security AI increases application data use. Fortunately, a solution is at hand.
Image: The Importance of Hybrid and Multi-Cloud Strategy Key benefits of a hybrid and multi-cloud approach include: Flexible Workload Deployment: The ability to place workloads in environments that best meet performance needs and regulatory requirements allows organizations to optimize operations while maintaining compliance.
An agent uses a function call to invoke an external tool (like an API or database) to perform specific actions or retrieve information it doesnt possess internally. These tools are integrated as an API call inside the agent itself, leading to challenges in scaling and tool reuse across an enterprise.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. This scalability allows for more frequent and comprehensive reviews.
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment.
For generative AI models requiring multiple instances to handle high-throughput inference requests, this added significant overhead to the total scaling time, potentially impacting applicationperformance during traffic spikes. We ran 5+ scaling simulations and observed consistent performance with low variations across trials.
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











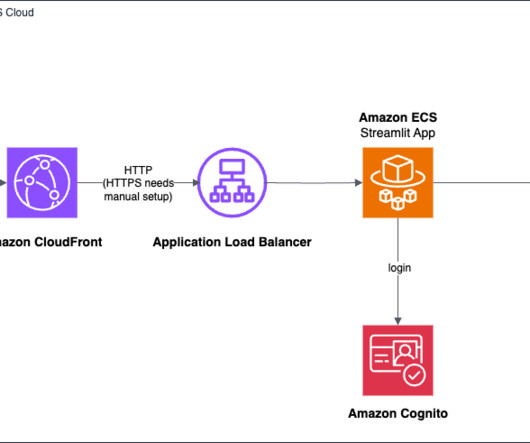











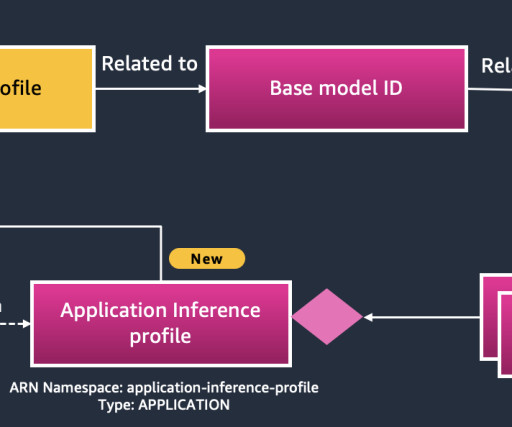












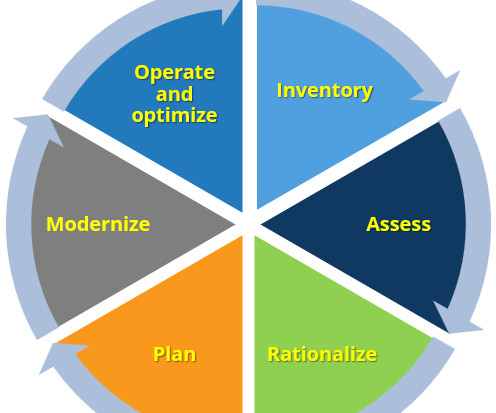

















Let's personalize your content