This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From data masking technologies that ensure unparalleled privacy to cloud-native innovations driving scalability, these trends highlight how enterprises can balance innovation with accountability. Organizations leverage serverless computing and containerized applications to optimize resources and reduce infrastructure costs.
Add to this the escalating costs of maintaining legacy systems, which often act as bottlenecks for scalability. The latter option had emerged as a compelling solution, offering the promise of enhanced agility, reduced operational costs, and seamless scalability. Scalability. Cost forecasting. Legacy infrastructure.
This process includes establishing core principles such as agility, scalability, security, and customer centricity. For example, a company aiming for market expansion might focus on developing scalable infrastructure, enabling application localization, and enhancing security measures to support operations in new regions.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. In this post, we set up the custom solution for observability and evaluation of Amazon Bedrock applications.
When addressed properly , application and platform modernization drives immense value and positions organizations ahead of their competition, says Anindeep Kar, a consultant with technology research and advisory firm ISG. He recommends building a user feedback loop and carefully studying satisfaction metrics.
Organizations building and deploying AI applications, particularly those using large language models (LLMs) with Retrieval Augmented Generation (RAG) systems, face a significant challenge: how to evaluate AI outputs effectively throughout the application lifecycle.
These metrics might include operational cost savings, improved system reliability, or enhanced scalability. CIOs must take an active role in educating their C-suite counterparts about the strategic applications of technologies like, for example, artificial intelligence, augmented reality, blockchain, and cloud computing.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. Building a generative AI application SageMaker Unified Studio offers tools to discover and build with generative AI.
tagging, component/application mapping, key metric collection) and tools incorporated to ensure data can be reported on sufficiently and efficiently without creating an industry in itself! to identify opportunities for optimizations that reduce cost, improve efficiency and ensure scalability.
Among these signals, OpenTelemetry metrics are crucial in helping engineers understand their systems. In this blog, well explore OpenTelemetry metrics, how they work, and how to use them effectively to ensure your systems and applications run smoothly. What are OpenTelemetry metrics?
With demand for generative AI applications surging across projects and multiple lines of business, accurately allocating and tracking spend becomes more complex. Without a scalable approach to controlling costs, organizations risk unbudgeted usage and cost overruns.
In todays fast-paced digital landscape, the cloud has emerged as a cornerstone of modern business infrastructure, offering unparalleled scalability, agility, and cost-efficiency. Technology modernization strategy : Evaluate the overall IT landscape through the lens of enterprise architecture and assess IT applications through a 7R framework.
In this post we’ll take a pragmatic approach to the realm of Kubernetes-based applications and go over a list of steps to help ensure reliability throughout the pipeline. Because even though ensuring application quality today is two times as difficult as it was in the past, there are also twice as many ways for us to improve it.
Mainframes hold an enormous amount of critical and sensitive business data including transactional information, healthcare records, customer data, and inventory metrics. It enhances scalability, flexibility, and cost-effectiveness, while maximizing existing infrastructure investments.
As DPG Media grows, they need a more scalable way of capturing metadata that enhances the consumer experience on online video services and aids in understanding key content characteristics. Word information lost (WIL) – This metric quantifies the amount of information lost due to transcription errors.
Generative artificial intelligence (AI) has gained significant momentum with organizations actively exploring its potential applications. As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions.
The Asure team was manually analyzing thousands of call transcripts to uncover themes and trends, a process that lacked scalability. Staying ahead in this competitive landscape demands agile, scalable, and intelligent solutions that can adapt to changing demands.
Work simulations Work simulations replicate real-life tasks and help you evaluate candidates practical application of skills. For instance, assigning a project that involves designing a scalable database architecture can reveal a candidates technical depth and strategic thinking.
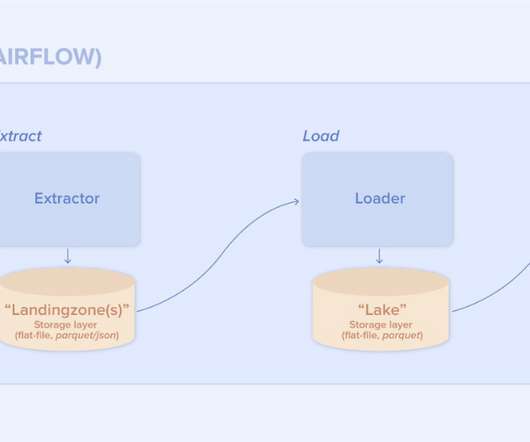
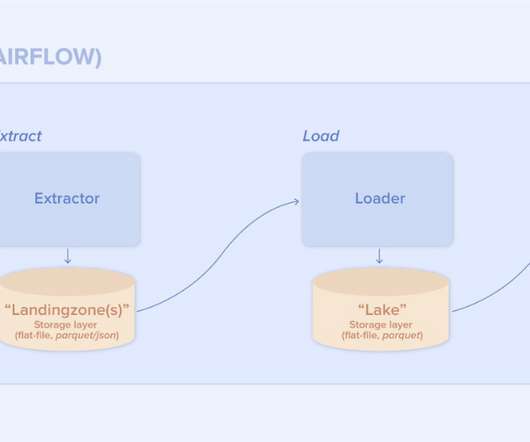
A data pipeline component is nothing more than a normal application. It goes through the same lifecycle as any other application: the component is developed and tested, an artifact is built and finally it gets deployed. During this the application uses normal application development processes like: CI/CD. Scalability.
A data pipeline component is nothing more than a normal application. It goes through the same lifecycle as any other application: the component is developed and tested, an artifact is built and finally it gets deployed. During this the application uses normal application development processes like: CI/CD. Scalability.
By boosting productivity and fostering innovation, human-AI collaboration will reshape workplaces, making operations more efficient, scalable, and adaptable. GenAI in 2025: Security, Observability, and the further rise of LLMOps The initial hype surrounding AI is evolving into a focus on practical applications that deliver measurable value.
Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft. DataJunction: Unifying Experimentation and Analytics Yian Shang , AnhLe At Netflix, like in many organizations, creating and using metrics is often more complex than it should be. Enter DataJunction (DJ).
He says, My role evolved beyond IT when leadership recognized that platform scalability, AI-driven matchmaking, personalized recommendations, and data-driven insights were crucial for business success. Shajy points out that its crucial to deal with the challenge of managing multiple applications across operations.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, such as AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
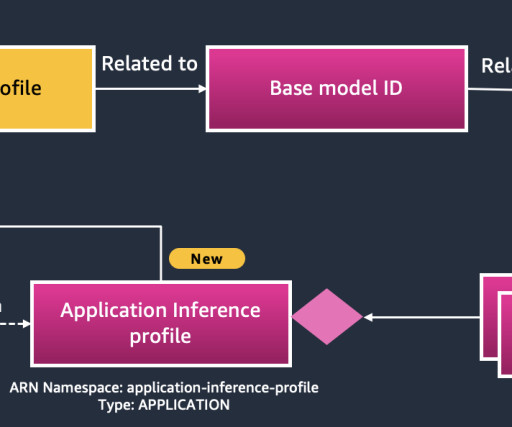
Open foundation models (FMs) have become a cornerstone of generative AI innovation, enabling organizations to build and customize AI applications while maintaining control over their costs and deployment strategies. Review the model response and metrics provided. This requires 2 Custom Model Units.
This involves monitoring the historical performance of the application and database to ensure that resources are not over-provisioned, which can lead to overhead costs. Combining cost visibility tools with automation can help organizations maintain financial efficiency without affecting the performance or scalability of Azure environments.
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. With Amazon Cognito , we are able to protect the web application from unauthenticated users.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics?
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
To unlock the full potential of AI, however, businesses need to deploy models and AI applications at scale, in real-time, and with low latency and high throughput. The Cloudera AI Inference service is a highly scalable, secure, and high-performance deployment environment for serving production AI models and related applications.
While organizations continue to discover the powerful applications of generative AI , adoption is often slowed down by team silos and bespoke workflows. Generative AI components provide functionalities needed to build a generative AI application. Each tenant has different requirements and needs and their own application stack.
Under Input data , enter the location of the source S3 bucket (training data) and target S3 bucket (model outputs and training metrics), and optionally the location of your validation dataset. To do so, we create a knowledge base. For Job name , enter a name for the fine-tuning job.
It also offers extensive industry and task-specific customization and secure integration with web/mobile applications. Llama Index LlamaIndex is also used to build RAG applications. USE CASES: Build interactive LLM applications, AI summarizers, etc. It is multilingual and improves search results with advanced AI technology.
Get your free copy of Charity’s Cost Crisis in Metrics Tooling whitepaper. Metrics-heavy shops are used to blaming custom metrics for their cost spikes, and for good reason. If you use a lot of custom metrics, switching to the 2.0 Every multiple pillars platform can handle your metrics, logs, traces, errors, etc.,
Generative AI can revolutionize organizations by enabling the creation of innovative applications that offer enhanced customer and employee experiences. For a comprehensive read about vector store and embeddings, you can refer to The role of vector databases in generative AI applications.
there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. Startup probe – Gives the application time to start up. It allows up to 25 minutes for the application to start before considering it failed. With the rise of large language models (LLMs) like Meta Llama 3.1,
Amazon SageMaker AI provides a managed way to deploy TGI-optimized models, offering deep integration with Hugging Faces inference stack for scalable and cost-efficient LLM deployment. Optimizing these metrics directly enhances user experience, system reliability, and deployment feasibility at scale. xlarge across all metrics.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
When it comes to developing applications and deploying technology, AI and IoT can be hugely successful if the right deployment measures are taken into consideration. However, even though the deployment of IoT application development has seen tremendous growth, the challenging aspect of implementation cannot be ignored.
So developers and data scientists can go from useful data in any shape, any form to useful applications in a matter of minutes. Rockset supplied a few metrics to illustrate this. Series D as scalable database resonates. And we’re offering this as a service. And it would take months today,” he told me in 2018.
Amazon SQS serves as a buffer, enabling the different components to send and receive messages in a reliable manner without being directly coupled, enhancing scalability and fault tolerance of the system. An event notification is sent to an Amazon Simple Queue Service (Amazon SQS) queue to align each file for further processing.
By integrating this model with Amazon SageMaker AI , you can benefit from the AWS scalable infrastructure while maintaining high-quality language model capabilities. SageMaker AI provides enterprise-grade security features to help keep your data and applications secure and private.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content