This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It seems like everyone is into microservices these days, and monolith architectures are slowly fading into obscurity. With Microservices, though, there seems to be more consensus that the trend is here to stay. With Microservices, though, there seems to be more consensus that the trend is here to stay. It makes sense.
The built-in elasticity in serverless computing architecture makes it particularly appealing for unpredictable workloads and amplifies developers productivity by letting developers focus on writing code and optimizing application design industry benchmarks , providing additional justification for this hypothesis. Vendor lock-in.
If you think of the shift to microservices and containers as an evolution rather than a revolution then you’ve reached the right place! In this post we’ll take a pragmatic approach to the realm of Kubernetes-based applications and go over a list of steps to help ensure reliability throughout the pipeline. Logging across microservices.
To answer this question, we recently created a framework that helps organizations pinpoint critical gaps in data and metrics that are holding them back on their reliability journeys. To fully understand what’s going on inside your application and maintain stability, this data must be collected at the code level. Code Metrics.
Containers power many of the applications we use every day. Particularly well-suited for microservice-oriented architectures and agile workflows, containers help organizations improve developer efficiency, feature velocity, and optimization of resources. Key metrics to monitor when leveraging two container orchestration systems.
Before you know it, you might find yourself preparing to transition a massive, complex monolith application to Microservices and realize that you have no idea where to start and there’s no one left at the company that knows how the foundational code of the software works. Microservices to the rescue? So… What is it anyway?
While organizations continue to discover the powerful applications of generative AI , adoption is often slowed down by team silos and bespoke workflows. The orchestrator is responsible for receiving the requests forwarded by the HTTPS endpoint and invoking relevant microservices, based on the task at hand.
phenomenon We’ve all heard the slogan, “metrics, logs, and traces are the three pillars of observability.” You probably use some subset (or superset) of tools including APM, RUM, unstructured logs, structured logs, infra metrics, tracing tools, profiling tools, product analytics, marketing analytics, dashboards, SLO tools, and more.
Honeycomb was founded in 2016 by two former Facebook engineers to create a new way of looking at application monitoring based on the internal tooling they had seen at Facebook. As the world shifted from applications performance monitoring to observability, Yen says Honeycomb was at the forefront of this shift.
Cisco announced on Friday that it’s acquiring Israeli applications-monitoring startup Epsagon at a price pegged at $500 million. The purchase gives Cisco a more modern microservices-focused component for its growing applications-monitoring portfolio. billion, and ThousandEyes, which it nabbed last year for $1 billion.
What is Microservices Architecture? Microservices Architecture Software development follows an architectural and organizational approach where small independent services communicate with each other through well-defined APIs. A microservice can locate and connect with other microservices only when it is published on an R&D server.
Below we outline common approaches to distributed tracing, the challenges these methods pose and how OverOps can help deliver greater insights when troubleshooting across microservices. The accelerated adoption of microservices and increasingly distributed systems brings the promise of greater speed, scalability and flexibility.
DevOps teams must take into account the whole picture of building applications, from features to costs, from application monitoring and underlying infrastructure instead of only being responsible for building features for their applications. There are also some downsides to Kubernetes.
Containerized microservices enable developers and DevOps engineers to meet these demands. Microservices are simple to develop, test, deploy, and scale, but they’re not without their own challenges. Each microservice must be individually configured, deployed, and monitored. What is Kubernetes?
IT teams have been observing applications for their health and performance since the beginning. If observability is not something new and there are a plethora of monitoring and observability tools available in the market, why bother about OpenTelemetry?
Everyone in tech is busy discussing Kubernetes, containers, and microservices as if the basics of DevOps and continuous delivery are all figured out. There’s not enough high-level data to inform application owners about application behavior. There’s not enough granular data to inform developers about application behavior.
Incorporating AI into API and microservice architecture design for the Cloud can bring numerous benefits. Automated scaling : AI can monitor usage patterns and automatically scale microservices to meet varying demands, ensuring efficient resource utilization and cost-effectiveness.
From software as a service (SaaS) and platform as a service (PaaS) to functions as a service (FaaS) and SaaS-delivered applications, service delivery has become paramount to business goals and practices. The post Hooked on Service Metrics appeared first on DevOps.com.
Get your free copy of Charity’s Cost Crisis in Metrics Tooling whitepaper. Metrics-heavy shops are used to blaming custom metrics for their cost spikes, and for good reason. If you use a lot of custom metrics, switching to the 2.0 Every multiple pillars platform can handle your metrics, logs, traces, errors, etc.,
Logs are time-stamped records generated by software applications, services, or network devices. They provide a sequential account of events that occurred within a system, including details of what happened, when it happened, and the state of the application during the event. What are logs? What are traces? What are traces composed of?
If you’re in the technology field and you live on planet earth, you’ve probably heard the term “microservices” thrown around. The purpose of this article will be to give you a familiarity with microservices and what it (not “they”) does. Microservices. Microservices is not just a buzzword. It’s almost become a buzzword.
Microservices architecture has become popular over the last several years. Many organizations have seen significant improvements in critical metrics such as time to market, quality, and productivity as a result of implementing microservices. Recently, however, there has been a noticeable backlash against microservices.
Enterprise development and IT Ops teams have various goals that they work towards, most of which fall under two main categories: driving innovation and maintaining application reliability (e.g. When it comes to application reliability, it can be hard to know where to start. The Agility-Reliability Paradox. software quality).
Significance of Bottleneck Analysis in Microservices Bottleneck analysis has become a significant part of microservices development for many reasons. Identify and Isolate Performance Issues Conducting a bottleneck analysis allows the developer to pinpoint specific areas where the application is experiencing performance issues.
At Imperva, we took advantage of Kafka Streams to build shared state microservices that serve as fault-tolerant, highly available single sources of truth about the state of objects in our system. At the core of each shared state microservice we built was a Kafka Streams instance with a rather simple processing topology.
When it comes to software development, application integration testing often finds itself in a somewhat nebulous space. With a shift towards microservices and highly modular architectures, the importance of application integration testing has never been greater. We often ask ourselves, "Why is it important?"
How many errors does the average application have? We all know application issues cost money, but quantifying it – well, that’s a harder task. Problems with a high likelihood of crashing an application or causing serious performance issues clearly contribute to technical debt. Every application has errors.
But did you ever ask yourself how an application does that? Applications talk to each other using intermediary software, an API, or an Application Programming Interface. The post API Testing Automation – Benefits, Metrics, and how to use for Microservices appeared first on Newgen.
A metric crossed a threshold. This is a critical application so you drag yourself out of bed, open your laptop, and start poring through dashboards for more info. Telltale learns what constitutes typical health for an application, no alert tuning required. Metrics are a key part of understanding application health.
The underlying large-scale metrics storage technology they built was eventually open sourced as M3. The distributed tracing tools also being announced today speak to how Chronosphere will be, going forward, looking for further applications of its monitoring tech.
The goal wasn’t just about having some insights from application performance monitoring; it was about embedding observability into the development process, aligning with service level objectives (SLOs), and enabling engineers to detect and resolve issues faster than ever. Early adopters quickly saw value.
Splunk helps organizations understand where things go wrong in applications, how to optimize the customer experience and to identify the fingerprints of fraud. It ingests this data from a myriad of sources but one of the largest contributors is the log files associated with our applications. It has become a standard in the data center.
Organizations are increasingly using distributed tracing to monitor their complex, microservice-based architectures. Distributed tracing has become essential in microserviceapplications, cloud-native and distributed systems.
So we set out to rethink the way we obtain information about errors and exceptions from our applications and services. Containers and microservices have become a default standard for the way we architect new applications. It often felt like we were fighting with one hand tied behind our backs.
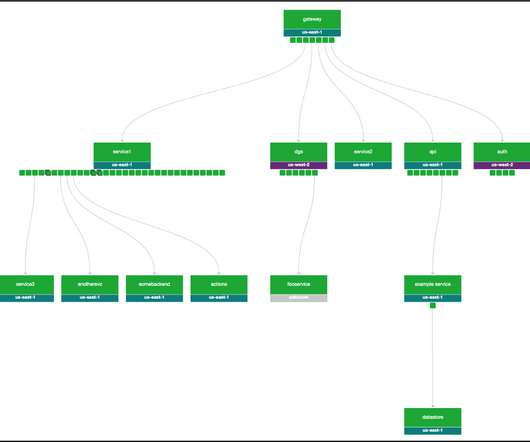
In particular, the VMAF metric lies at the core of improving the Netflix member’s streaming video quality. This article explains how we designed microservices and workflows on top of the Cosmos platform to bolster such video quality innovations. Cosmos is a computing platform for workflow-driven, media-centric microservices.
The rise of containerization technologies, like Docker, and systems for orchestrating and deploying these containers, like Kubernetes, have completely transformed the traditional application architecture. Traditionally, an application was more of a monolith. Because of this, manual intervention can sometimes be necessary.
If you want to develop microservices or backend applications in Java and make use of innovative and new technologies while also reducing coding effort, speeding development time, and producing a more resilient application, you should consider using Jakarta EE and MicroProfile. What is Jakarta EE? . pom.xml. <dependency>
Underlying technology of Chaos Studio for Azure Kubernetes Service is the opens source platform Chaos Mesh We started with deploying a microserviceapplication on to AKS. This application uses DAPR to add some more robustness to the application. Without metrics, you are blind. This is what Dapr brings to the table.
Consumer lag is the most important metric to monitor when working with event streams. However, it is not available as a default metric in Azure Insights. Want to have this metric available as part of your monitoring solution? A consuming application can have multiple instances that can each read from multiple partitions.
HCL Commerce Containers provide a modular and scalable approach to managing ecommerce applications. framework to build server-side rendered (SSR) and statically generated (SSG) React applications. Registry app : This app implementsa service registry to maintain a directory of all microservices and their instances (Containers).
Application performance monitoring, also known as APM, represents the difference between code and running software. APM answers these questions: Is my application working? APM brings this level of metric rigor to applications, recording uptime, requests received, statuses returned, latency, and resource usage for each running process.
Applications can no longer simply be understood by examining their source code or relying on traditional monitoring methods. The interplay of distributed architectures, microservices, cloud-native environments, and massive data flows requires an increasingly critical approach : observability. Software systems are increasingly complex.
The project involved decommissioning an extensive monolith Scala application into smaller microservices. The team used the Strangler Fig pattern to decommission the legacy system gradually in new Scala and modern microservices running in Kubernetes. We’ll put the focus on Kubernetes and the Java Virtual Machine ( JVM ).
Observability has three pillars: metrics, logs, and traces.” But logs are expensive and everybody wants dashboards… so we buy a metrics tool. Software engineers want to instrument their applications… so we buy an APM tool. Logs, metrics, traces, APM, RUM. A “metric” consists of a single number, often with tags appended.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content