This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. In this post, we set up the custom solution for observability and evaluation of Amazon Bedrock applications.
Lumigo , a cloud-native application monitoring and debugging platform, today announced that it has raised a $29 million Series A funding round led by Redline Capital. The company started with a focus on distributed tracing for serverless platforms like AWS’ API Gateway, DynamoDB, S3 and Lambda. Image Credits: Lumigo.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. Building a generative AI application SageMaker Unified Studio offers tools to discover and build with generative AI.
With demand for generative AI applications surging across projects and multiple lines of business, accurately allocating and tracking spend becomes more complex. This scalable, programmatic approach eliminates inefficient manual processes, reduces the risk of excess spending, and ensures that critical applications receive priority.
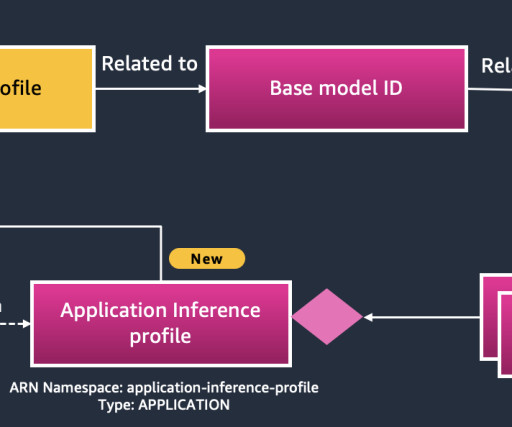
One of the key differences between the approach in this post and the previous one is that here, the Application Load Balancers (ALBs) are private, so the only element exposed directly to the Internet is the Global Accelerator and its Edge locations. These steps are clearly marked in the following diagram.
While organizations continue to discover the powerful applications of generative AI , adoption is often slowed down by team silos and bespoke workflows. It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Tenant This part represents the tenants using the AI gateway capabilities.
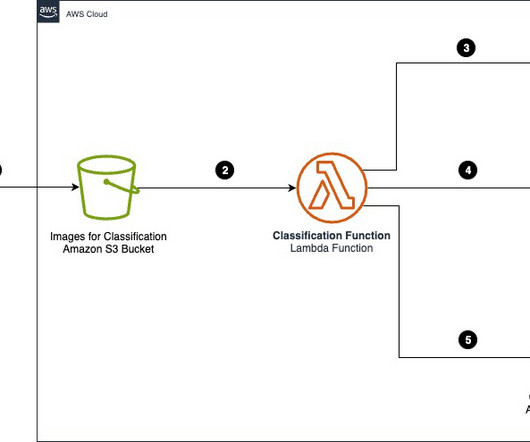
The text extraction AWS Lambda function is invoked by the SQS queue, processing each queued file and using Amazon Textract to extract text from the documents. The text summarization Lambda function is invoked by this new queue containing the extracted text. Choose one from the below compliance score based on evidence submitted: 1.
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. AWS Lambda is an event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers.
At the AWS re:Invent conference this week, Sumo Logic announced that in addition to collecting log data, metrics and traces, it now can collect telemetry data from the Lambda serverless computing service provided by Amazon Web Services (AWS).
With the significant developments in the field of generative AI , intelligent applications powered by foundation models (FMs) can help users map out an itinerary through an intuitive natural conversation interface. Amazon Bedrock is the place to start when building applications that will amaze and inspire your users.
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Overview of solution The first thing to consider is that different metrics require different computation considerations. The function invokes the modules.
Using Amazon Bedrock allows for iteration of the solution using knowledge bases for simple storage and access of call transcripts as well as guardrails for building responsible AI applications. With the use of Amazon Bedrock, various models can be chosen based on different use cases, illustrating its flexibility in this application.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. The Lambda wrapper function searches for similar questions in OpenSearch Service.
As a result, they needed a way to develop, test, and roll out customer experiences for each partner site and application with minimal disruption, to avoid lengthy delays or tying up the business for long periods of time during the transition. TrueCar needed to selectively switch traffic and applications between the legacy and new platforms.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon using a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock Agents offers developers the ability to build and configure autonomous agents in their applications. These agents help users complete actions based on organizational data and user input, orchestrating interactions between foundation models (FMs), data sources, software applications, and user conversations.
Have you ever wondered whether your AWS Lambda could be faster if you used a different runtime? AWS Lambda allows us to execute code in the cloud without needing to provision anything. In the past few years, it has become increasignly well-known thanks to the rise of serverless applications. Rust, Node.js 8.10, C# (.NET
We continue benchmarking AWS Lambda… In Part I of this blog we tested the performance of a Hello World example for 8 different runtimes and got us some very interesting metrics. We wanted to simulate a use case common in many applications?—? Once again, we used AWS CloudWatch to extract all the metrics we were interested in.
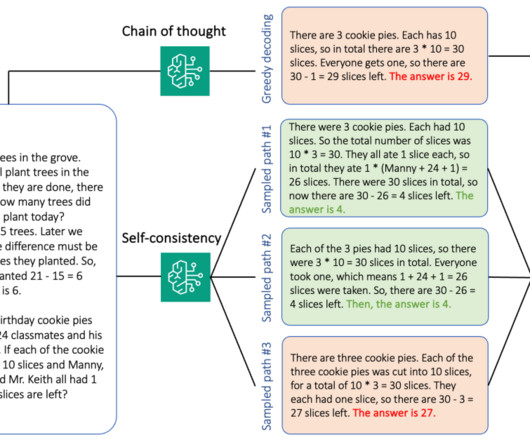
Generative AI question-answering applications are pushing the boundaries of enterprise productivity. With deterministic evaluation processes such as the Factual Knowledge and QA Accuracy metrics of FMEval , ground truth generation and evaluation metric implementation are tightly coupled.
This post explores an innovative application of large language models (LLMs) to automate the process of customer review analysis. Visualization – Generate business intelligence (BI) dashboards that display key metrics and graphs. Regular application of this solution can augment internal workforce efficiency, resulting in cost savings.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
In software engineering, there is a direct correlation between team performance and building robust, stable applications. This requires carefully combining applications and metrics to provide complete awareness, accuracy, and control. It’s also vital to avoid focusing on irrelevant metrics or excessively tracking data.
AWS makes it possible for organizations of all sizes and developers of all skill levels to build and scale generative AI applications with security, privacy, and responsible AI. Translate the English text to an ASL gloss using Amazon Bedrock, which is used to build and scale generative AI applications using FMs.
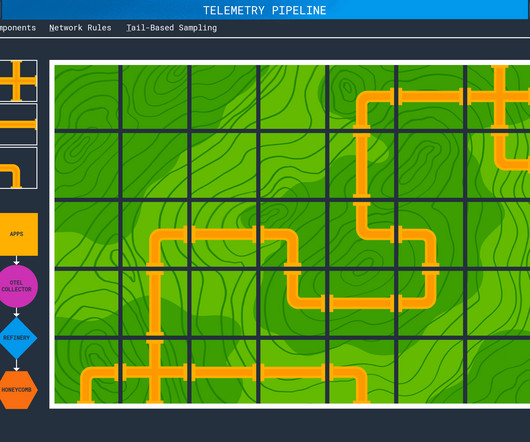
In this post, I describe how to send OpenTelemetry (OTel) data from an AWS Lambda instance to Honeycomb. I will be showing these steps using a Lambda written in Python and created and deployed using AWS Serverless Application Model (AWS SAM). AWS Lambda, Honeycomb, and OpenTelemetry all provide thorough documentation.
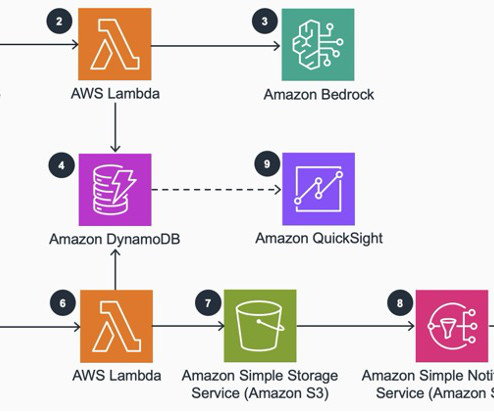
They used the following services in the solution: Amazon Bedrock Amazon DynamoDB AWS Lambda Amazon Simple Storage Service (Amazon S3) The following diagram illustrates the high-level workflow of the current solution: The workflow consists of the following steps: The user navigates to Vidmob and asks a creative-related query.
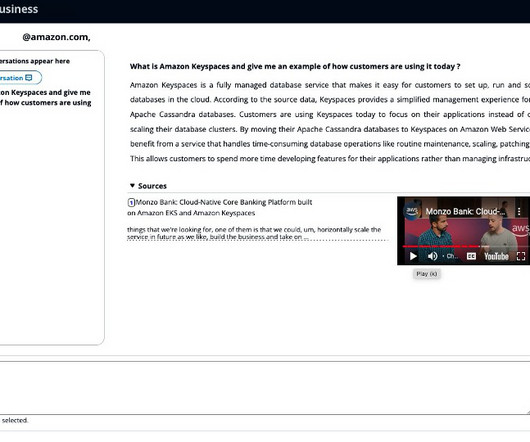
The solution also features an enhanced Amazon Q Business query application that allows users to play the relevant section of the original media files or YouTube videos directly from the search results page, providing a seamless and intuitive user experience. In this post, we create a customer managed application that supports OAuth 2.0,
A long time ago, in a galaxy far, far away, I said a lot of inflammatory things about metrics. Metrics are s**t salad.”. Metrics are simply nerfed dimensions.”. Metrics suck ,” “metrics are legacy ,” “metrics and time series aggregates will f **g kneecap you.”. Metrics aren’t worthless; they’re just limited.
Vector databases efficiently index and organize the embeddings, enabling fast retrieval of similar vectors based on distance metrics like Euclidean distance or cosine similarity. In our solution, when an application wants to perform a semantic search, the search document is first converted into an embedding. bedrock = boto3.client(
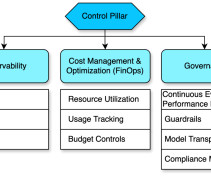
In this post, we share AWS guidance that we have learned and developed as part of real-world projects into practical guides oriented towards the AWS Well-Architected Framework , which is used to build production infrastructure and applications on AWS. We focus on the operational excellence pillar in this post.
AI-driven recommendations – By combining generative AI with ML, we deliver intelligent suggestions for products, services, applicable use cases, and next steps. Investments and support – Information on customer issues, promotional programs, support cases, and product feature requests. The following screenshot shows a sample account summary.
Distributed Load Testing on AWS helps you automate the testing of your software applications at scale and at load to identify bottlenecks before you release your application. Amazon CloudWatch metrics dashboard : To verify the test logs, you need to log in to Amazon CloudWatch. What is AWS DLT?
You can also enable advanced metrics and recommendations features for extra assistance and information, all of which can help you learn how to configure Lifecycle rules for S3 buckets. Key metrics like GET requests and Download Bytes help determine your buckets’ daily access frequency.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
Every time a new recording is uploaded to this folder, an AWS Lambda Transcribe function is invoked and initiates an Amazon Transcribe job that converts the meeting recording into text. This S3 event triggers the Notification Lambda function, which pushes the summary to an Amazon Simple Notification Service (Amazon SNS) topic.
At the core, Bots are third party applications that run in Telegram and help publish messages to the Telegram group. Here, the AWS Services used are AWS Cloudwatch, SNS, and Lambda. Instead, you will have to create a simple Lambda function which calls the Bot API and forwards the notifications to a Telegram chat. return output.
As a Honeycomb Pro or Enterprise user, you can also send metrics to Honeycomb from any AWS service that publishes metrics to CloudWatch Metrics. These integrations use a combination of serverless technologies, including AWS Kinesis Data Firehose and AWS Lambda , so that you don’t have to run extra infrastructure or agents.
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
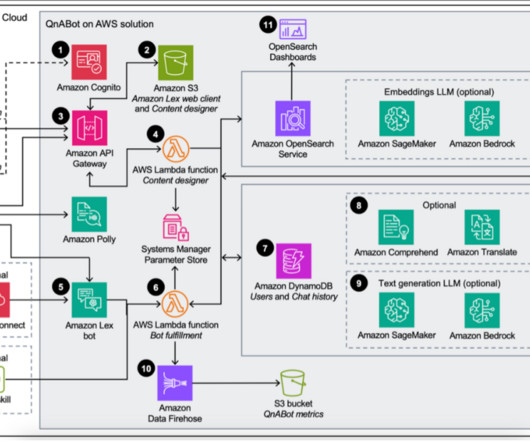
The Content Designer AWS Lambda function saves the input in Amazon OpenSearch Service in a questions bank index. Amazon Lex forwards requests to the Bot Fulfillment Lambda function. Users can also send requests to this Lambda function through Amazon Alexa devices. He lives with his wife and dog (Figaro), in New York, NY.
Because of Honeycomb’s unique pricing model where the only variable that impacts your renewal is event consumption, you don’t need to worry about the myriad of factors that impact your costs in traditional APM tools (eg: memory, hosts, Lambda invocations, devices, headcounts, or SKUs). Consolidate logging, tracing, and metrics ingest costs.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies and Amazon via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Lambda function B. SQS queue C. EC2 instance D.
In November, we announced Honeycomb’s extension for the Lambda Runtime Logs API to more reliably send Lambda events to Honeycomb while also decreasing any added overhead, latency, and cost. Pierre Tessier also had this hot walkthrough on getting infrastructure metrics out of the new Kubernetes + Honeycomb agent.
Each individual Streams application was deployed as a standalone microservice, and we used the Gradle Application plugin to build and deploy these services. applicationName = 'wordcount-lambda-example'. // Default artifact naming. applicationName = 'wordcount-lambda-example'. // Default artifact naming. version = '1.0.0'.
In a simple deployment, an application will emit spans, metrics, and logs which will be sent to api.honeycomb.io Simple and direct The most basic connection is where an application sends its trace data directly to Honeycomb. This also adds the blue lines, which denote metrics data. and show up in charts.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content