This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud storage.
All industries and modern applications are undergoing rapid transformation powered by advances in accelerated computing, deep learning, and artificial intelligence. The next phase of this transformation requires an intelligent data infrastructure that can bring AI closer to enterprise data. Imagine that you’re a dataengineer.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
A lack of monitoring might result in idle clusters running longer than necessary, overly broad data queries consuming excessive compute resources, or unexpected storage costs due to unoptimized data retention. Once the decision is made, inefficiencies can be categorized into two primary areas: compute and storage.
A lack of monitoring might result in idle clusters running longer than necessary, overly broad data queries consuming excessive compute resources, or unexpected storage costs due to unoptimized data retention. Once the decision is made, inefficiencies can be categorized into two primary areas: compute and storage.
Dbt is a popular tool for transforming data in a data warehouse or data lake. It enables dataengineers and analysts to write modular SQL transformations, with built-in support for data testing and documentation. This makes dbt a natural choice for the Ducklake setup.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. It’s no longer driven by data volumes, but containerization, separation of storage and compute, and democratization of analytics.
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Securing and scaling storage. Test Drive CDP Pubic Cloud.
Today, generative AI can help bridge this knowledge gap for nontechnical users to generate SQL queries by using a text-to-SQL application. This application allows users to ask questions in natural language and then generates a SQL query for the users request. This can be overwhelming for nontechnical users who lack proficiency in SQL.
Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and data lakes. Applicationdata architect: The applicationdata architect designs and implements data models for specific software applications.
A cloud architect has a profound understanding of storage, servers, analytics, and many more. Big DataEngineer. Another highest-paying job skill in the IT sector is big dataengineering. And as a big dataengineer, you need to work around the big data sets of the applications.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket. Solution overview Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
Data Science and Machine Learning sessions will cover tools, techniques, and case studies. This year, we have many sessions on managing and deploying models to production, and applications of deep learning in enterprise applications. Stream Processing and Real-time Applications sessions. Data platforms.
download Model-specific cost drivers: the pillars model vs consolidated storage model (observability 2.0) All of the observability companies founded post-2020 have been built using a very different approach: a single consolidated storageengine, backed by a columnar store. and observability 2.0. understandably). moving forward.
I know this because I used to be a dataengineer and built extract-transform-load (ETL) data pipelines for this type of offer optimization. Part of my job involved unpacking encrypted data feeds, removing rows or columns that had missing data, and mapping the fields to our internal data models.
In this blog post, we’ll look at both Apache HBase and Apache Phoenix concepts relevant to developing applications for Cloudera Operational Database. But first, let’s look at the different form factors in which Cloudera Operational Database is available to developers: Public cloud: CDP Data Hub Operational Database template .
As with many data-hungry workloads, the instinct is to offload LLM applications into a public cloud, whose strengths include speedy time-to-market and scalability. Without data, Holmes’ argument proceeds, one can twist facts to suit their theories, rather than use theories to suit facts.
Solution overview The NER & LLM Gen AI Application is a document processing solution built on AWS that combines NER and LLMs to automate document analysis at scale. Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs. Click here to open the AWS console and follow along.
Today’s data science and dataengineering teams work with a variety of machine learning libraries, data ingestion, and datastorage technologies. Risk and compliance considerations mean that the ability to reproduce machine learning workflows is essential to meet audits in certain application domains.
Modak, a leading provider of modern dataengineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera DataEngineering (CDE) integration with Modak Nabu.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. This greatly increases data processing capabilities.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, such as AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
The shift to cloud has been accelerating, and with it, a push to modernize data pipelines that fuel key applications. That is why cloud native solutions which take advantage of the capabilities such as disaggregated storage & compute, elasticity, and containerization are more paramount than ever.
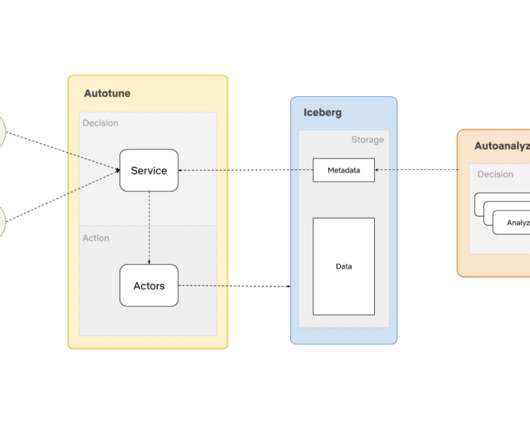
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloud storage (S3 for AWS, ADLS-gen2 for Azure).
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
We will describe each level from the following perspectives: differences on the operational level; analytics tools companies use to manage and analyze data; business intelligence applications in real life; challenges to overcome and key changes that lead to transition. the specialists, tools, and applications of Descriptive analytics.
The company currently has “hundreds” of large enterprise customers, including Western Union, FOX, Sony, Slack, National Grid, Peet’s Coffee and Cisco for projects ranging from business intelligence and visualization through to artificial intelligence and machine learning applications.
In this last installment, we’ll discuss a demo application that uses PySpark.ML to make a classification model based off of training data stored in both Cloudera’s Operational Database (powered by Apache HBase) and Apache HDFS. Afterwards, this model is then scored and served through a simple Web Application. Serving The Model
Python is used extensively among DataEngineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machine learning models. Apache HBase is an effective datastorage system for many workflows but accessing this data specifically through Python can be a struggle.
BSH’s previous infrastructure and operations teams, which supported the European appliance manufacturer’s application development groups, simply acted as suppliers of infrastructure services for the software development organizations. If we have a particular type of outage, our observability tool can also restart the application.”
And as data workloads continue to grow in size and use, they continue to become ever more complex. On top of that, today there are a wide range of applications and platforms that a typical organization will use to manage source material, storage, usage and so on.
In the finance industry, software engineers are often tasked with assisting in the technical front-end strategy, writing code, contributing to open-source projects, and helping the company deliver customer-facing services. Dataengineer.
In the finance industry, software engineers are often tasked with assisting in the technical front-end strategy, writing code, contributing to open-source projects, and helping the company deliver customer-facing services. Dataengineer.
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
To do this, they are constantly looking to partner with experts who can guide them on what to do with that data. This is where dataengineering services providers come into play. Dataengineering consulting is an inclusive term that encompasses multiple processes and business functions.
Streaming data technologies unlock the ability to capture insights and take instant action on data that’s flowing into your organization; they’re a building block for developing applications that can respond in real-time to user actions, security threats, or other events. The application will contain ML mathematical algorithms.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content