This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Azure Synapse Analytics is Microsofts end-to-give-up information analytics platform that combines massive statistics and facts warehousing abilities, permitting advanced records processing, visualization, and system mastering. What is Azure Synapse Analytics? Why Integrate Key Vault Secrets with Azure Synapse Analytics?
Today, data sovereignty laws and compliance requirements force organizations to keep certain datasets within national borders, leading to localized cloud storage and computing solutions just as trade hubs adapted to regulatory and logistical barriers centuries ago. This gravitational effect presents a paradox for IT leaders.
In this post, you will learn how to extract key objects from image queries using Amazon Rekognition and build a reverse image search engine using Amazon Titan Multimodal Embeddings from Amazon Bedrock in combination with Amazon OpenSearch Serverless Service. An Amazon OpenSearch Serverless collection. b64encode(resized_image).decode('utf-8')
The workflow consists of the following steps: WAFR guidance documents are uploaded to a bucket in Amazon Simple Storage Service (Amazon S3). Using Amazon Bedrock Knowledge Base, the sample solution ingests these documents and generates embeddings, which are then stored and indexed in Amazon OpenSearch Serverless.
These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help. In this post, we demonstrate how to leverage the new EMR Serverless integration with SageMaker Studio to streamline your data processing and machine learning workflows.
With serverless being all the rage, it brings with it a tidal change of innovation. or invest in a vendor-agnostic layer like the serverless framework ? or invest in a vendor-agnostic layer like the serverless framework ? What is more, as the world adopts the event-driven streaming architecture, how does it fit with serverless?
Get 1 GB of free storage. It’s the serverless platform that will run a range of things with stronger attention on the front end. Even though Vercel mainly focuses on front-end applications, it has built-in support that will host serverless Node.js This is the serverless wrapper made on top of AWS.
Designed with a serverless, cost-optimized architecture, the platform provisions SageMaker endpoints dynamically, providing efficient resource utilization while maintaining scalability. Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs.
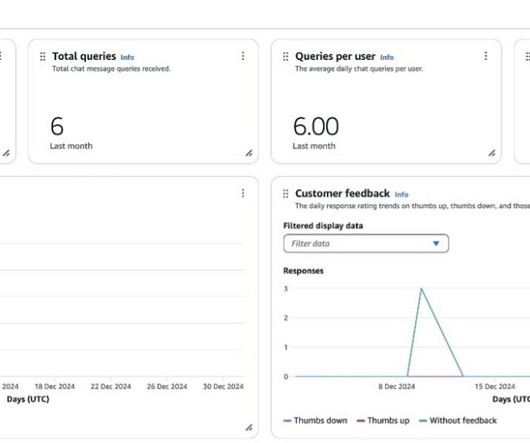
This comprehensive analytics approach empowers organizations to continuously refine their Amazon Q Business implementation, making sure users receive the most relevant and helpful AI-assisted support. For more details, see Viewing the analytics dashboards. These logs are then queryable using Amazon Athena.
Therefore, it was valuable to provide Asure a post-call analytics pipeline capable of providing beneficial insights, thereby enhancing the overall customer support experience and driving business growth. This step is shown by business analysts interacting with QuickSight in the storage and visualization step through natural language.
SageMaker Unified Studio setup SageMaker Unified Studio is a browser-based web application where you can use all your data and tools for analytics and AI. This will provision the backend infrastructure and services that the sales analytics application will rely on. Select OpenSearch Serverless as your vector store.
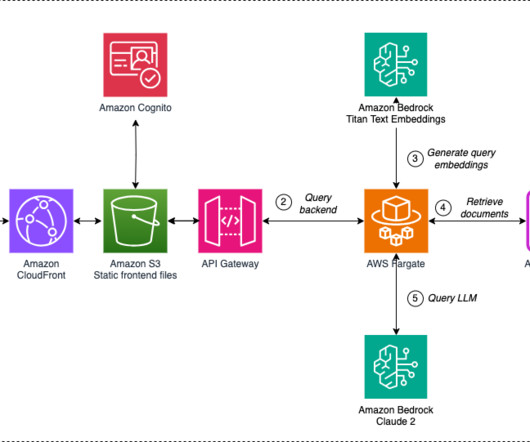
In this post, we dive deeper into one of MaestroQAs key featuresconversation analytics, which helps support teams uncover customer concerns, address points of friction, adapt support workflows, and identify areas for coaching through the use of Amazon Bedrock. The following architecture diagram demonstrates the request flow for AskAI.
Leveraging Rockset , a scalable SQL search and analytics engine based on RocksDB , and in conjunction with BI and analytics tools, we’ll examine a solution that performs interactive, real-time analytics on top of Apache Kafka and also show a live monitoring dashboard example with Redash. Overview of Rockset technology.
API Gateway is serverless and hence automatically scales with traffic. The advantage of using Application Load Balancer is that it can seamlessly route the request to virtually any managed, serverless or self-hosted component and can also scale well. It’s serverless so you don’t have to manage the infrastructure.
The growing volume of data is a concern, as 20% of enterprises surveyed by IDG are drawing from 1000 or more sources to feed their analytics systems. It is difficult to scale storage and process infrastructure to manage the sheer increase in the volume. The approach is efficient in processing high-volume data for analytics and BI.
After being in cloud and leveraging it better, we are able to manage compute and storage better ourselves,” said the CIO, who notes that vendors are not cutting costs on licenses or capacity but are offering more guidance and tools. He went with cloud provider Wasabi for those storage needs. “We
Security analytics can then be performed against the transcripts, enabling organizations to improve their security posture by increasing their ability to detect security anomalies by bad actors. Using this capability, security teams can process all the video recordings into transcripts. The transcript is provided in tags.
Flexible logging –You can use this solution to store logs either locally or in Amazon Simple Storage Service (Amazon S3) using Amazon Data Firehose, enabling integration with existing monitoring infrastructure. Cost optimization – This solution uses serverless technologies, making it cost-effective for the observability infrastructure.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure.
To this end, SurrealDB supports real-time queries, security permissions for multi-user access and “performant” analytical workloads, Tobie says. Client-side apps can be built with direct connections to SurrealDB, while traditional, server-side dev setups can leverage the platform’s querying and analytics abilities.
Verisk (Nasdaq: VRSK) is a leading strategic data analytics and technology partner to the global insurance industry, empowering clients to strengthen operating efficiency, improve underwriting and claims outcomes, combat fraud, and make informed decisions about global risks. The user can pick the two documents that they want to compare.
And it's serverless 6 , so you only pay for the actual usage. I'm deliberately vague about what exact role I mean here: take it to mean data engineers, data scientists, ML engineers, analytics engineers, and maybe more roles. But under the hood, the we use a content-addressed storage system. How does it work?
From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, data storage systems have come a long way to become what they are now. Summarized touches upon the fact the data is used for data analytics. Is it still so? Data warehouse architecture.
“The speed of innovation is really starting to accelerate,” says Jefferson Frazer, director of edge compute, delivery, and storage at Shutterstock, which is headquartered in the Empire State Building. “If Storage intelligence, for example, has reduced the duplication of images, an issue that occurs after acquisitions.
Some hyperscalers offer tools and advice on making AI more sustainable, such as Amazon Web Services, which provides tips on using serverless technologies to eliminate idle resources, data management tools, and datasets. AWS also has models to reduce data processing and storage, and tools to “right size” infrastructure for AI application.
The first is near unlimited storage. Leveraging cloud-based object storage frees analytics platforms from any storage constraints. Analytical engines can be scaled up (or down) on demand, as per the requirements of your workload. You will have access to on-demand compute and storage at your discretion.
According to the RightScale 2018 State of the Cloud report, serverless architecture penetration rate increased to 75 percent. Aware of what serverless means, you probably know that the market of cloudless architecture providers is no longer limited to major vendors such as AWS Lambda or Azure Functions. Where does serverless come from?
That’s why today, we’re incredibly excited to announce Log Drains for the Netlify Enterprise plan , providing analysis, alerting, and data persistence for Netlify traffic and serverless functions logs through Datadog. User agent analytics and troubleshooting. Serverless function invocation information and performance monitoring.
Key features of AWS Batch Efficient Resource Management: AWS Batch automatically provisions the required resources, such as compute instances and storage, based on job requirements. This enables you to build end-to-end workflows that leverage the full range of AWS capabilities for data processing, storage, and analytics.
As the name suggests, a cloud service provider is essentially a third-party company that offers a cloud-based platform for application, infrastructure or storage services. In a public cloud, all of the hardware, software, networking and storage infrastructure is owned and managed by the cloud service provider. What Is a Public Cloud?
The raw photos are stored in Amazon Simple Storage Service (Amazon S3). Aurora MySQL serves as the primary relational data storage solution for tracking and recording media file upload sessions and their accompanying metadata. S3, in turn, provides efficient, scalable, and secure storage for the media file objects themselves.
BigQuery’s serverless architecture lets you use SQL queries to answer your organization’s biggest questions with zero infrastructure management. BigQuery maximizes flexibility by separating the compute engine that analyzes your data from your storage choices.
The output data is transformed to a standardized format and stored in a single location in Amazon S3 in Parquet format, a columnar and efficient storage format. Venkat is a Technology Strategy Leader in Data, AI, ML, generative AI, and Advanced Analytics.
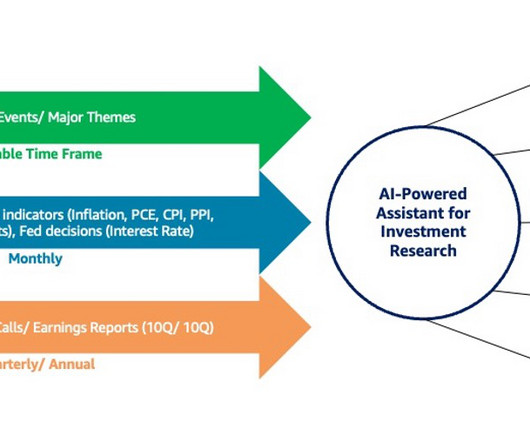
The key components of the technical architecture are as follows: Data storage and analytics – The quarterly financial earning recordings as audio files, financial annual reports as PDF files, and S&P stock data as CSV files are hosted on Amazon S3. The following diagram illustrates the technical architecture.
AWS had a lot to say about its analytics and data management capabilities this year at re:Invent 2022. AWS Glue for Apache Spark has added support for several open-source data lake storage frameworks. Other AWS Data Management and Analytics Announcements. We have the highlights from the event in this handy summary. AWS Glue 4.0
Beyond investments in narrowing the skills gap, companies are beginning to put processes in place for their data science projects, for example creating analytics centers of excellence that centralize capabilities and share best practices. For most companies, the road toward machine learning (ML) involves simpler analytic applications.
These services are also designed to function as gateway drugs to cloud services: e.g., Microsoft integrates its on- and off-premises Excel client experience with its PowerBI cloud analytics service, as well as with its ecosystem of Azure-based advanced analytics and machine learning (ML) services. Serverless Stagnant.
Skills: Relevant skills for a cloud software engineer include Python, Java, C#, JavaScript, microservices architecture, serverless computing, APIs and SKDs, DevOps, cybersecurity, and knowledge of the agile methodology. Role growth: 19% of companies have added cloud software engineer roles as part of their cloud investments.
This is a guest post co-written with Vicente Cruz Mínguez, Head of Data and Advanced Analytics at Cepsa Química, and Marcos Fernández Díaz, Senior Data Scientist at Keepler. About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química.
Source: IoT Analytics. These hardware components cache and preprocess real-time data, reducing the burden on central storages and main processors. Source: IoT Analytics. The number of active IoT connections is expected to double by 2025, jumping from the current 9.9 billion to 21.5 Transport layer: networks and gateways.
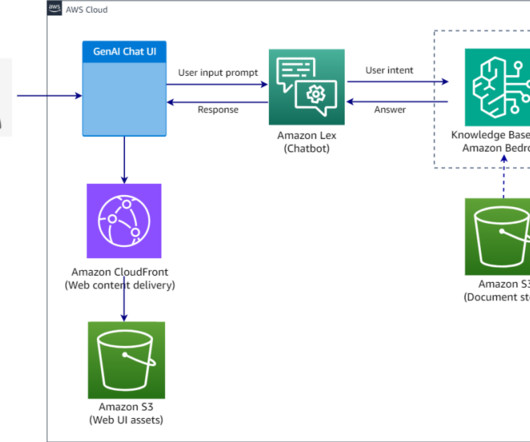
In this post, we demonstrate how you can build chatbots with QnAIntent that connects to a knowledge base in Amazon Bedrock (powered by Amazon OpenSearch Serverless as a vector database ) and build rich, self-service, conversational experiences for your customers. Create an Amazon Lex bot. Select the embedding model to vectorize the documents.
With the cloud, users and organizations can access the same files and applications from almost any device since the computing and storage take place on servers in a data center instead of locally on the user device or in-house servers. It enables organizations to operate efficiently without needing any extensive internal infrastructure.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake. Amazon Bedrock offers a practical environment for benchmarking and a cost-effective solution for managing workloads due to its serverless operation. About the Authors Aishwarya Subramaniam is a Sr. Solutions Architect in AWS.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content