This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. As a result, traffic won’t be balanced across all replicas of your deployment. For production use, make sure that loadbalancing and scalability considerations are addressed appropriately.
In this post, we dive deeper into one of MaestroQAs key featuresconversation analytics, which helps support teams uncover customer concerns, address points of friction, adapt support workflows, and identify areas for coaching through the use of Amazon Bedrock.
Loadbalancer – Another option is to use a loadbalancer that exposes an HTTPS endpoint and routes the request to the orchestrator. You can use AWS services such as Application LoadBalancer to implement this approach. API Gateway also provides a WebSocket API.
The easiest way to use Citus is to connect to the coordinator node and use it for both schema changes and distributed queries, but for very demanding applications, you now have the option to loadbalance distributed queries across the worker nodes in (parts of) your application by using a different connection string and factoring a few limitations.
Amazon SageMaker AI provides a managed way to deploy TGI-optimized models, offering deep integration with Hugging Faces inference stack for scalable and cost-efficient LLM deployment. During non-peak hours, the endpoint can scale down to zero , optimizing resource usage and cost efficiency.
The public cloud infrastructure is heavily based on virtualization technologies to provide efficient, scalable computing power and storage. Cloud adoption also provides businesses with flexibility and scalability by not restricting them to the physical limitations of on-premises servers. Scalability and Elasticity.
Dynamic loadbalancing : AI algorithms can dynamically balance incoming requests across multiple microservices based on real-time traffic patterns, optimizing performance and reliability.
Knowing your project needs and tech capabilities results in great scalability, constant development speed, and long-term viability: Backend: Technologies like Node.js Cloud & infrastructure: Known providers like Azure, AWS, or Google Cloud offer storage, scalable hosting, and networking solutions. Frontend: Angular, React, or Vue.js
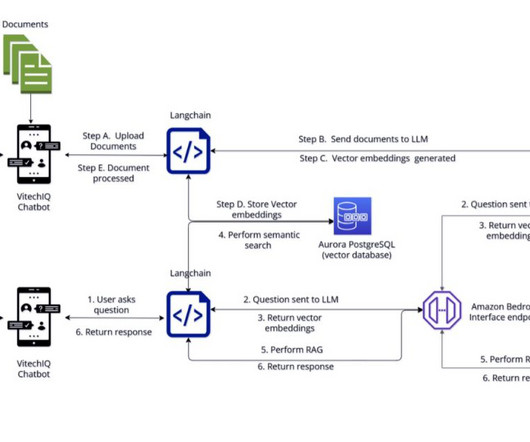
By using the Livy REST APIs , SageMaker Studio users can also extend their interactive analytics workflows beyond just notebook-based scenarios, enabling a more comprehensive and streamlined data science experience within the Amazon SageMaker ecosystem. After conversion, the documents are split into chunks and prepared for embedding.
It offers the most intuitive user interface & scalability choices. Features: Friendly UI and scalability options More than 25 free products Affordable, simple to use, and flexible Range of products Simple to start with user manual Try Google Cloud Amazon AWS Amazon Web Services or AWS powers the whole internet.
Scalability : Kong is designed to scale horizontally, allowing it to handle large amounts of API traffic. Plugins : Kong has a vast and continuously growing ecosystem of plugins that provide additional functionality, such as security, transformations, and integrations with other tools.
By Bob Gourley Note: we have been tracking Cloudant in our special reporting on Analytical Tools , Big Data Capabilities , and Cloud Computing. Cloudant will extend IBM’s Big Data and Analytics , Cloud Computing and Mobile offerings by further helping clients take advantage of these key growth initiatives. – bg.
Consider the following factors: Ease of integration with existing infrastructure (firewalls, firewall management stations, layer 3 devices, loadbalancers, proxies, clouds, etc.) Reporting and analytic capabilities, accuracy, and timing Policy enforcement and monitoring Scalability and performance User interface and usability Workflow optimization (..)
The Apache Solr cluster is available in CDP Public Cloud , using the “Data exploration and analytics” data hub template. For scalability, it is best to distribute the queries among the Solr servers in a round-robin fashion. We repeated the tests both with and without reusing the cookies sent back in the HTTPS responses.
In the current digital environment, migration to the cloud has emerged as an essential tactic for companies aiming to boost scalability, enhance operational efficiency, and reinforce resilience. Our checklist guides you through each phase, helping you build a secure, scalable, and efficient cloud environment for long-term success.
To optimize its AI/ML infrastructure, Cisco migrated its LLMs to Amazon SageMaker Inference , improving speed, scalability, and price-performance. However, as the models grew larger and more complex, this approach faced significant scalability and resource utilization challenges.
From origin through all points of consumption both on-prem and in the cloud, all data flows need to be controlled in a simple, secure, universal, scalable, and cost-effective way. Ingesting all device and application logs into your SIEM solution is not a scalable approach from a cost and performance perspective.
These applications are used to manage and streamline various business processes and operations, including customer relationship management, enterprise resource planning, enterprise resources planning, supply chain management, human resource management, and business intelligence and analytics. Key features of Node.js
These applications are used to manage and streamline various business processes and operations, including customer relationship management, enterprise resource planning, enterprise resources planning, supply chain management, human resource management, and business intelligence and analytics. Key features of Node.js
Most scenarios require a reliable, scalable, and secure end-to-end integration that enables bidirectional communication and data processing in real time. Most MQTT brokers don’t support high scalability. Use cases for IoT technologies and an event streaming platform. Requirements and challenges of IoT integration architectures.
Dispatcher In AEM the Dispatcher is a caching and loadbalancing tool that sits in front of the Publish Instance. Integrates seamlessly with other components of the AEM ecosystem, including AEM author and publish instances, AEM Forms, Adobe Target, and Adobe Analytics. Troubleshoot issues related to loadbalancing.
One of the main advantages of the MoE architecture is its scalability. There was no monitoring, loadbalancing, auto-scaling, or persistent storage at the time. They have expanded their offerings to include Windows, monitoring, loadbalancing, auto-scaling, and persistent storage.
Solarflare, a global leader in networking solutions for modern data centers, is releasing an Open Compute Platform (OCP) software-defined, networking interface card, offering the industry’s most scalable, lowest latency networking solution to meet the dynamic needs of the enterprise environment. Hardware Based Security (ServerLock).
The cloud environment lends itself well to Agile management, as it enables easy scalability and flexibility, providing a perfect platform for collaboration, automation, and seamless integration of development, testing, deployment, and monitoring processes. It is crucial to evaluate the scalability and flexibility of the platform.
It offers features such as data ingestion, storage, ETL, BI and analytics, observability, and AI model development and deployment. Adopting a cloud native data platform architecture empowers organizations to build and run scalable data applications in dynamic environments, such as public, private, or hybrid clouds.
Vitech helps group insurance, pension fund administration, and investment clients expand their offerings and capabilities, streamline their operations, and gain analytical insights. He currently collaborates with Independent Software Vendors (ISVs) to build highly scalable, innovative, and secure cloud solutions.
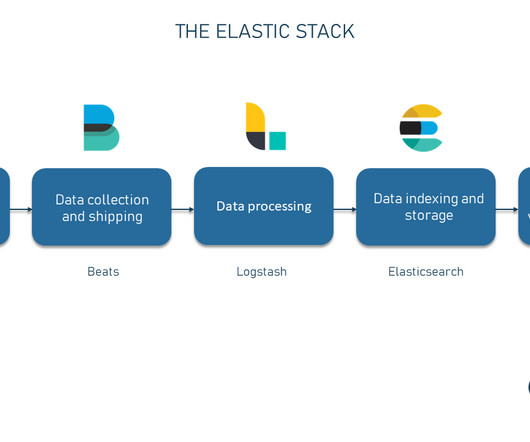
What if we told you that one of the world’s most powerful search and analytics engines started with the humble goal of organizing a culinary enthusiast’s growing list of recipes? First publicly introduced in 2010, Elasticsearch is an advanced, open-source search and analytics engine that also functions as a NoSQL database.
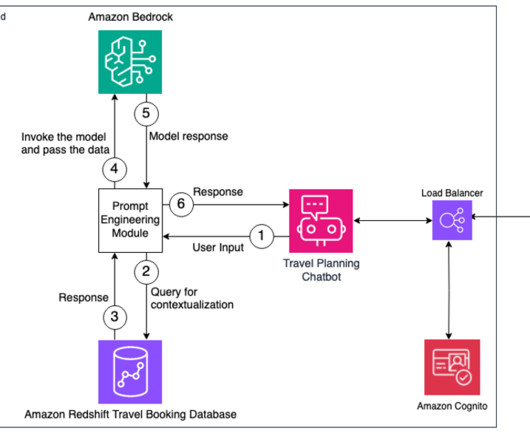
First, the user logs in to the chatbot application, which is hosted behind an Application LoadBalancer and authenticated using Amazon Cognito. She has over 15 years of strong experience in leading several complex, highly robust, and massively scalable software solutions for large-scale enterprise applications.
Data Analyses To get insights from such vast and diverse data sets, an appropriate analytical tool is essential. Scalability Demands As the volume of data grows, the systems have to handle & manage the data without compromising on performance. Scalability AWS provides EC2 instances that can be scaled up or down.
Security analytics: Along with security governance and compliance assurance, Prisma Public Cloud integrates with VPC flow logs to provide useful insight into east-west and north-south traffic flows by correlating data with various security intelligence sources. Schedule 1:1 time with us. Fill out this form to schedule time.
The successful revolution and evolution of GitOps practices in mainstream enterprises stem from the ability to give teams a process to streamline their unique paradigms and sets of practices, with the sole intention of producing more efficient integration, testing, delivery, deployment, analytics, and governance of code.
Delivers 1000s Virtual NICs for Ultimate Scalability with the Lowest Possible Latency. These high performance Ethernet adapters has been designed for modern data centers that require scalability and performance. The capability to distribute captured packets across many cores better supporting real-time packet analytics.
Scalability & Flexibility. Enhanced Scalability. Scalability and Flexibility With auto-scaling built into serverless frameworks, your applications can seamlessly handle variable workloads while reducing the operational complexity associated with server maintenance. Complexity. Tool Overload. Greater Tool Overload.
These are the common bottlenecks in analytic queries, and are notoriously difficult to optimize. . Allocate scan ranges to nodes based on data locality and the scheduler’s loadbalancing heuristics. Analytic Functions. Analytic functions depend on the PARTITION BY clause for parallelism. Summary and call to action.
Join Etleap , an Amazon Redshift ETL tool to learn the latest trends in designing a modern analytics infrastructure. Learn what has changed in the analytics landscape and how to avoid the major pitfalls which can hinder your organization from growth. Register for the webinar today.
Join Etleap , an Amazon Redshift ETL tool to learn the latest trends in designing a modern analytics infrastructure. Learn what has changed in the analytics landscape and how to avoid the major pitfalls which can hinder your organization from growth. Register for the webinar today.
An overview A cloud service platform offered by Amazon, known as AWS or Amazon Web Services, provides users with a range of services, including computation, storage, analytics, databases, networking, mobile, developer tools, management tools, and IoT. What is AWS Cloud Platform?:
Join Etleap , an Amazon Redshift ETL tool to learn the latest trends in designing a modern analytics infrastructure. Learn what has changed in the analytics landscape and how to avoid the major pitfalls which can hinder your organization from growth. Register for the webinar today.
They want to deploy a powerful content management solution on a scalable and highly available platform and also shift focus from infrastructure management so that their IT teams focus on content delivery. Progressing from visiting a website to filling out an online form, as one example, should be a seamless process. You can download it here.
Apps Associates prides itself on being a trusted partner for the management of critical business needs, providing strategic consulting and managed services for Oracle, Salesforce, integration , analytics and multi-cloud infrastructure. As such we wanted to share the latest features, functionality and benefits of AWS with you.
Apps Associates prides itself on being a trusted partner for the management of critical business needs, providing strategic consulting and managed services for Oracle, Salesforce, integration , analytics and multi-cloud infrastructure. As such we wanted to share the latest features, functionality and benefits of AWS with you.
This unified distribution is a scalable and customizable platform where you can securely run many types of workloads. Best of CDH & HDP, with added analytic and platform features . Further information and documentation [link] . Summary of major changes.
No wonder Amazon Web Services has become one of the pillars of todays digital economy, as it delivers flexibility, scalability, and agility. AWS cost optimization: The basic things to know AWS provides flexibility and scalability, making it an almost irreplaceable tool for businesses, but these same benefits often lead to inefficiencies.
For heads of IT/Engineering responsible for building an analytics infrastructure , Etleap is an ETL solution for creating perfect data pipelines from day one. We found that High Scalability readers are about 80% more likely to be in the top bracket of engineering skill. Need excellent people? Advertise your job here!
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content