

What is data architecture? A framework to manage data
CIO
DECEMBER 20, 2024
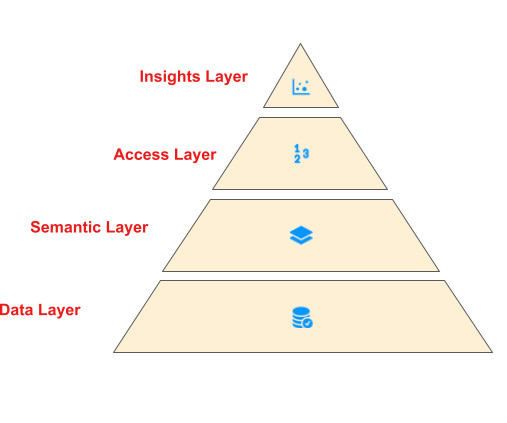
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Curate the data.













































Let's personalize your content