This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
In today’s data economy, in which software and analytics have emerged as the key drivers of business, CEOs must rethink the silos and hierarchies that fueled the businesses of the past. They can no longer have “technology people” who work independently from “data people” who work independently from “sales” people or from “finance.”
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
Successful AI teams also include a range of people who understand the business and the problems it’s trying to solve, says Bradley Shimmin, chief analyst for AI platforms, analytics, and data management at consulting firm Omdia. Data scientists may build the ML models, but its ML engineers who implement them.
The US financial services industry has fully embraced a move to the cloud, driving a demand for tech skills such as AWS and automation, as well as Python for dataanalytics, Java for developing consumer-facing apps, and SQL for database work. Dataengineer. Business systems analyst.
The US financial services industry has fully embraced a move to the cloud, driving a demand for tech skills such as AWS and automation, as well as Python for dataanalytics, Java for developing consumer-facing apps, and SQL for database work. Dataengineer. Business systems analyst.
AI continues to transform customer engagements and interactions with chatbots that use predictive analytics for real-time conversations. Cloud-native apps, microservices and mobile apps drive revenue with their real-time customer interactions. report they have established a data culture 26.5% That’s not to say it’ll be easy.
Similar to how DevOps once reshaped the software development landscape, another evolving methodology, DataOps, is currently changing Big Dataanalytics — and for the better. DataOps is a relatively new methodology that knits together dataengineering, dataanalytics, and DevOps to deliver high-quality data products as fast as possible.
Key survey results: The C-suite is engaged with data quality. Data scientists and analysts, dataengineers, and the people who manage them comprise 40% of the audience; developers and their managers, about 22%. Data quality might get worse before it gets better. An additional 7% are dataengineers.
It takes much more effort than just building an analytic model with Python and your favorite machine learning framework. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers.
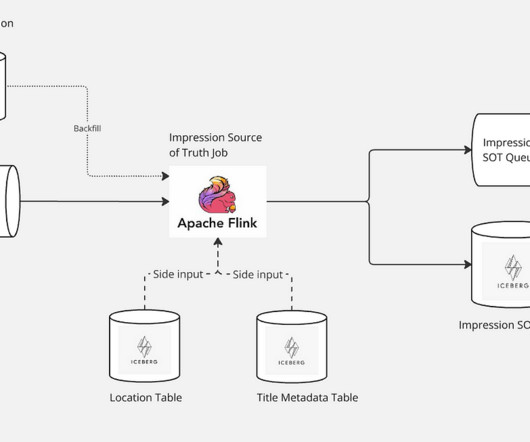
Analytical Insights Additionally, impression history offers insightful information for addressing a number of platform-related analytics queries. Stay tuned for the next part of this series, where well delve into how we use this SOT dataset to create a microservice that provides impression histories.
Tech Conferences Compass Tech Summit – October 5-6 Compass Tech Summit is a remarkable 5-in-1 tech conference, encompassing topics such as engineering leadership, AI, product management, UX, and dataengineering that will take place on October 5-6 at the Hungarian Railway Museum in Budapest, Hungary.
Get hands-on training in Docker, microservices, cloud native, Python, machine learning, and many other topics. Fundamentals of Machine Learning and DataAnalytics , July 10-11. Essential Machine Learning and Exploratory Data Analysis with Python and Jupyter Notebook , July 11-12. Data science and data tools.
The concept of the data mesh architecture is not entirely new; Its conceptual origins are rooted in the microservices architecture, its design principles (i.e., A data mesh can be defined as a collection of “nodes”, typically referred to as Data Products, each of which can be uniquely identified using four key descriptive properties:
Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , March 13. Data Modelling with Qlik Sense , March 19-20. Foundational Data Science with R , March 26-27. What You Need to Know About Data Science , April 1. Data Pipelining with Luigi and Spark , April 17.
And Holochain is a decentralized framework for building peer-to-peer microservices–no cloud provider needed. ApacheHop is a metadata-driven data orchestration for building dataflows and data pipelines. It integrates with Spark and other dataengines, and is programmed using a visual drag-and-drop interface, so it’s low code.
Get hands-on training in Docker, microservices, cloud native, Python, machine learning, and many other topics. Fundamentals of Machine Learning and DataAnalytics , July 10-11. Essential Machine Learning and Exploratory Data Analysis with Python and Jupyter Notebook , July 11-12. Data science and data tools.
One-sixth of respondents identify as data scientists, but executives—i.e., The survey does have a data-laden tilt, however: almost 30% of respondents identify as data scientists, dataengineers, AIOps engineers, or as people who manage them. All told, more than 70% of respondents work in technology roles.
Public cloud, agile methodologies and devops, RESTful APIs, containers, analytics and machine learning are being adopted. ” Deployments of large data hubs have only resulted in more data silos that are not easily understood, related, or shared. Happy New Year and welcome to 2019, a year full of possibilities.
Building data pipelines can offer strategic advantages to the business. It can be used to power new analytics, insight, and product features. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines. Data pipeline initiatives are generally unfinished projects.
Apache Spark unifies batch processing, real-time processing, stream analytics, machine learning, and interactive query in one-platform. A single, unified infrastructure for both majority of batch workloads and microservices. Background. Why choose K8s for Apache Spark. Fine-grained access controls on shared clusters. Acknowledgments.
Real-Time Streaming Analytics and Algorithms for AI Applications , May 15. Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , May 20. First Steps in Data Analysis , May 20. Data Analysis Paradigms in the Tidyverse , May 30. Microservice Fundamentals , July 10.
She formulated the thesis in 2018 and published her first article “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh” in 2019. Microservices are the architectural approach to building an application backend as a composition of multiple, loosely coupled, and independently deployable smaller components, or services.
The Deliveroo Engineering organisation is in the process of decomposing a monolith application into a suite of microservices. The benefit of central management of these rules is that we ensure good data quality across all inter-service communication because the rules are defined once and used consistently.
At its core, CDP Private Cloud Data Services (“the platform”) is an end-to-end cloud native platform that provides a private open data lakehouse. It offers features such as data ingestion, storage, ETL, BI and analytics, observability, and AI model development and deployment. What is cloud native exactly?
This might mean a complete transition to cloud-based services and infrastructure or isolating an IT or business domain in a microservice, like data backups or auth, and establishing proof-of-concept. Either way, it’s a step that forces teams to deal with new data, network problems, and potential latency.
Data solution vendors like SnapLogic and Informatica are already developing machine learning and artificial intelligence (AI) based smart data integration assistants. These assistants can recommend next-best-action or suggest datasets, transforms, and rules to a dataengineer working on a data integration project.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. process data in real time and run streaming analytics. In other words, Kafka can serve as a messaging system, commit log, data integration tool, and stream processing platform. Kafka vs ETL.
This year you will have 6 unique tracks: Cloud Computing: IaaS, PaaS, SaaS DevOps: Microservices, Automation, ASRs Cybersecurity: Threats, Defenses, Tests Data Science: ML, AI, Big Data, Business Analytics Programming languages: C++, Python, Java, Javascript,Net Future & Inspire: Mobility, 5G data networks, Diversity, Blockchain, VR.
Clustered computing for real-time Big Dataanalytics. This involves pre-selecting various combinations of dimensions/columns from the source data, and collapsing that data into multiple result sets that contain only those dimensions. Post-Hadoop NetFlow analytics. Flow records — NetFlow, sFlow, IPFIX, etc. —
But, in any case, the pipeline would provide dataengineers with means of managing data for training, orchestrating models, and managing them on production. To enable the model reading this data, we need to process it, and transform into features that a model can consume. Generating predictions.
Its a common skill for cloud engineers, DevOps engineers, solutions architects, dataengineers, cybersecurity analysts, software developers, network administrators, and many more IT roles. Its a skill common with data analysts, business intelligence professionals, and business analysts.
The cloud computing market covers many areas like business processes, infrastructure, platform, security, management, analytics supported by cloud providers. Along with meeting customer needs for computing and storage, they continued extending services by presenting products dealing with analytics, Big Data, and IoT. Game tech
TIBCO DQ will become the new data quality product family, through an evolution of our current data quality offerings, significantly enhancing current capabilities available throughout the TIBCO data fabric with built-in AI and ML to automate quality, detection, monitoring, and anomaly resolution.
The use of ML-powered analytics solutions can help businesses forecast inventory demand with high accuracy. Systems that rely on machine learning are capable of analyzing a multitude of data points, finding subtle patterns (indicating changes in customer preferences, behavior, or satisfaction) which can be non-obvious for a human.
Building applications with RAG requires a portfolio of data (company financials, customer data, data purchased from other sources) that can be used to build queries, and data scientists know how to work with data at scale. Dataengineers build the infrastructure to collect, store, and analyze data.
For several years, microservices has been one of the most popular topics in software architecture, and this year is no exception. Although DDD has been around for a long time, it came into prominence with the rise of microservices as a way to think about partitioning an application into independent services. growth over 2021.
The microservice movement will reignite the need for orchestration. Some analyst is bound to rename BPM engines to Microservice Orchestration Engines (MOE).wait Customer demand for solutions built on lean, loosely coupled BPM microservices will skyrocket. wait did I just do that. Lloyd Dugan BPM.com [link].
Machine learning, artificial intelligence, dataengineering, and architecture are driving the data space. The Strata Data Conferences helped chronicle the birth of big data, as well as the emergence of data science, streaming, and machine learning (ML) as disruptive phenomena.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content