This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineering is one of these new disciplines that has gone from buzzword to mission critical in just a few years. As data has exploded, so has their challenge of doing this key work, which is why a new set of tools has arrived to make dataengineering easier, faster and better than ever.
DuckDB is an in-process analytical database designed for fast query execution, especially suited for analytics workloads. However, DuckDB doesn’t provide data governance support yet. Dbt is a popular tool for transforming data in a data warehouse or data lake. Why Integrate DuckDB with Unity Catalog?
During their time at Segment, Hightouch co-founders Tejas Manohar and Josh Curl witnessed the rise of data warehouses like Snowflake, Google’s BigQuery and Amazon Redshift — that’s where a lot of Segment data ends up, after all. Typically, though, this information is then only used for analytics purposes.
Users can then transform and visualize this data, orchestrate their data pipelines and trigger automated workflows based on this data (think sending Slack notifications when revenue drops or emailing customers based on your own custom criteria). y42 founder and CEO Hung Dang. Image Credits: y42.
It takes much more effort than just building an analytic model with Python and your favorite machine learning framework. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers.
The team leaned on data scientists and bio scientists for expert support. These algorithms were built on top of an advanced analytics self-service platform, enhancing the agility of our data modeling, training, and predictive processes,” Gopalan explains. These transitions are intricate processes and mistakes are inevitable.
Data Hub – has expanded to support all stages of the data lifecycle: Collect – Flow Management (Apache NiFi), Streams Management (Apache Kafka) and Streaming Analytics (Apache Flink). Enrich – DataEngineering (Apache Spark and Apache Hive). Predict – DataEngineering (Apache Spark).
Rules based systems become unwieldy as more exceptions and changes are added and are overwhelmed by today’s sheer volume and variety of new data sources. For this reason, many financial institutions are converting their fraud detection systems to machine learning and advanced analytics and letting the data detect fraudulent activity.
We've been focusing a lot on machine learning recently, in particular model inference — Stable Diffusion is obviously the coolest thing right now, but we also support a wide range of other things: Using OpenAI's Whisper model for transcription , Dreambooth , object detection (with a webcam demo!). I will be posting a lot more about it!
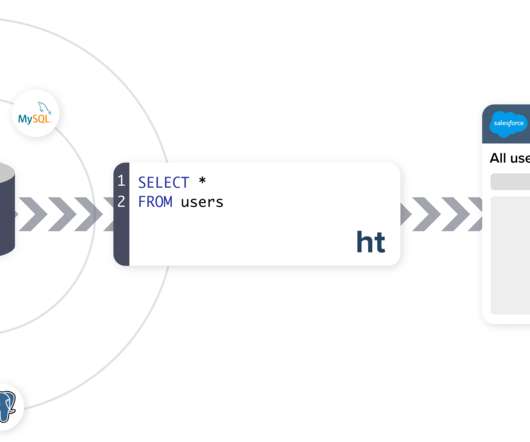
Apache Spark is a very popular analyticsengine used for large-scale data processing. It is widely used for many big data applications and use cases. We are going to use an Operational Database COD instance and Apache Spark present in the Cloudera DataEngineering experience. . Cloudera DataEngineering.
The second blog dealt with creating and managing Data Enrichment pipelines. The third video in the series highlighted Reporting and Data Visualization. And this blog will focus on Predictive Analytics. Data Collection – streaming data. Data Enrichment – dataengineering. Additional Resources.
This includes high-demand roles like Full stack- Django/React, Full stack- Django/Angular, Full stack- Django/Spring/ React, Full stack- Django/Spring/Angular, Dataengineer, and DevOps engineer. We have 20 pre-defined roles available now, and we intend to add more to the stack. And that’s all.
We are super excited to participate in the biggest and the most influential Data, AI and Advanced Analytics event in the Nordics! Data Innovation Summit ! There our Gema Parreño – Data Science expert at Apiumhub gives a talk about Alignment of Language Agents for serious video games.
Today, we are thrilled to announce the upcoming beta release of Cloudera Altus Analytic DB. As the first data warehouse cloud service that brings the warehouse to the data, it delivers instant self-service BI and SQL analytics to anyone – easily, reliably, and securely.
Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like data warehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data.
We wanted to provide a modern cloud-based platform leveraging the latest in machine learning, analytics and automation to fight the many cyber attacks businesses face every day. The new platform also integrates a rich set of identity data sources and built-in analytics to address a variety of identity-based threats. .
In this blog we will take you through a persona-based data adventure, with short demos attached, to show you the A-Z data worker workflow expedited and made easier through self-service, seamless integration, and cloud-native technologies. Data Catalog profilers have been run on existing databases in the Data Lake.
Like all of our customers, Cloudera depends on the Cloudera Data Platform (CDP) to manage our day-to-day analytics and operational insights. Many aspects of our business live within this modern data architecture, providing all Clouderans the ability to ask, and answer, important questions for the business.
Many consumer internet companies invest heavily in analytics infrastructure, instrumenting their online product experience to measure and improve user retention. It turns out that type of data infrastructure is also the foundation needed for building AI products. If you can’t walk, you’re unlikely to run. AI doesn’t fit that model.
So we’ve called this new feature Peering Analytics, because it will primarily be used to determine who to peer (interconnect) with. But as you’ll see, Peering Analytics — which launched in November 2015 and has now emerged from Beta into a full v1 release — has use cases far beyond peering. Using Peering Analytics.
I’ll keep the sizes as small as possible, since it is only for demo purposes. It provides a collaborative environment for teams to work together, accelerating the development and deployment of data-driven solutions. First, click on SQL Warehouses on the left bar, then Create SQL warehouse button. This will open a new window.
It is also a good starting point for debugging data quality issues, because it offers an easy way to copy the actual compiled SQL that was executed for a given test. packages: - package: elementary-data/elementary version: 0.13.1 In case you do not have a packages.yml file yet, you can create one in the root of your dbt project.
Data scientists play a critical role in the DataOps ecosystem, leveraging advanced analytics and machine learning techniques to gain insights from large and complex data sets. DataOps team roles In a DataOps team, several key roles work together to ensure the data pipeline is efficient, reliable, and scalable.
Along with thousands of other data-driven organizations from different industries, the above-mentioned leaders opted for Databrick to guide strategic business decisions. What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning.
The one key component that is missing is a common, shared table format, that can be used by all analytic services accessing the lakehouse data. Data services, including cloud native data warehouse called CDW, dataengineering service called CDE, data streaming service called data in motion, and machine learning service called CML.
Embracing the hybrid cloud model – We delivered all the key tenets of CDF on Cloudera Data Platform (CDP) Data Hub as well – Flow Management for Data Hub, Streams Messaging for Data Hub, and Streaming Analytics for Data Hub. If you are interested, you can watch it on-demand as well.
While these instructions are carried out for Cloudera Data Platform (CDP), Cloudera DataEngineering, and Cloudera Data Warehouse, one can extrapolate them easily to other services and other use cases as well. Watch our webinar Supercharge Your Analytics with Open Data Lakehouse Powered by Apache Iceberg.
Iceberg is an emerging open-table format designed for large analytic workloads. Several compute engines such as Impala, Hive, Spark, and Trino have supported querying data in Iceberg table format by adopting this Java Library provided by the Apache Iceberg project. It includes a live demo recording of Iceberg capabilities.
Kentik’s Advanced Analytics Turns Routes into Insights. That’s why network engineers have long used the BGP routing table on routers or looking glasses to get an idea of how their Internet traffic is routed. This is the premise behind the Analytics features in Kentik Detect, Peering Analytics and Route Traffic Analytics.
Imagine a big data time-series datastore that unifies traffic flow records (NetFlow, sFlow, IPFIX) with related data such as BGP routing, GeoIP, network performance, and DNS logs, that retains unsummarized data for months, and that has the compute and storage power to answer ad hoc queries across billions of data points in a couple of seconds.
The page features joint solution briefs, solution demos, and sales enablement templates. According to Ramakrishna Peddiraj, Vice President and Head of DataEngineering and Analytics at iSteer, “This partnership is a great opportunity to create value-based solutions for customers. The Solution in Action.
Enterprise data architects, dataengineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas.
Key IoT Analytics Requirements. Network-based analytics is critical to managing IoT infrastructure. Network analytics has the power to examine details of the IoT communications patterns made through various protocols and correlate these to data paths traversed throughout the network.
Service providers of all stripes can benefit from big data-powered network insights in similar ways as KDDI, both in planning as well as operational realms. If you’d like to learn more, check out our products , read our Kentik DataEngine (KDE) white paper, and dig into why NFV needs advanced analytics.
The pace of data being created is mind-blowing. For example, Amazon receives more than 66,000 orders per hour with each order containing valuable pieces of information for analytics. Yet, dealing with continuously growing volumes of data isn’t the only challenge businesses encounter on the way to better, faster decision-making.
Applying Network Analytics. A traffic analytics system that correlates flow with BGP can reveal the best opportunities for peering. are correlated with BGP routing data in a datastore that’s optimized for traffic analytics it’s relatively easy to discover the best peering opportunities for your network.
This year you will have 6 unique tracks: Cloud Computing: IaaS, PaaS, SaaS DevOps: Microservices, Automation, ASRs Cybersecurity: Threats, Defenses, Tests Data Science: ML, AI, Big Data, Business Analytics Programming languages: C++, Python, Java, Javascript,Net Future & Inspire: Mobility, 5G data networks, Diversity, Blockchain, VR.
They decided that what they needed was to be able to collect, store, and analyze network flow data like NetFlow, sFlow, and IPFIX. So they all set out to build their own flow analytics system, each one based on a different database. Or step inside today for your own look around: request a demo or start a free trial.
Needless to say, this call-out by analysts Nolan Greene and Rohit Mehra reflects well on what we’ve been doing to advance the state of the art in areas such as DDoS protection, infrastructure visibility, performance monitoring, and peering analytics. Sign up today for a free trial , or contact us for a demo. Why Kentik?
That’s how much flow data is ingested by Kentik DataEngine (KDE), the distributed big data backend that powers Kentik Detect®. It’s also just one of the many interesting statistics that we run across as we operate our SaaS platform for network traffic analytics. Roughly 100 billion flow records each and every day.
Clustered computing for real-time Big Dataanalytics. This involves pre-selecting various combinations of dimensions/columns from the source data, and collapsing that data into multiple result sets that contain only those dimensions. Post-Hadoop NetFlow analytics. Flow records — NetFlow, sFlow, IPFIX, etc. —
As a single platform for your entire team, AI Cloud brings together Data Scientists , analytics experts , IT and the business to collaborate, combine expertise and align resources on shared initiatives. AI Cloud brings together any type of data, from any source, giving you a unique, global view of insights that drive your business.
Without the visibility and analytics provided by tracking data, there would be no way to know, nor any way to leverage that data to improve delivery times, reduce cost, or allocate load across the paths and system components that serve various customers. Learn More With a Demo or Free Trial.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content